セキュリティチームの ぐっちー です。最近のAIブームにより、毎日のようにChatGPTの自社データ活用に関する商談をやっていおり、セキュリティの仕事はあんまりやってませんw
今日は商談の中で、かなりの確率で質問されることが多い「精度向上にはどういう手法があるか?」という点をブログにしました。権威ドキュメントや公式ドキュメントの情報ではなく、様々な手法の中から僕なりに情シス向けにトリアージをしたもので、網羅性には欠けると思いますが、参考情報として見ていただけたら幸いです。
前提条件
- 本ブログの内容は、2023年10月22日時点までの情報を元に作成しております。
- 精度向上に対しての有効なプラクティスは企業の置かれている状況やユースケースによって異なりますので、参考までに見ていただけたら幸いです。
- 本ブログはベストプラクティスや特定の正解を提供することを主旨とするものではありません。あくまで、プラクティス(方法論)についてを提供して、目線合わせすることを目的としています。
- 想定読者:
- 本ブログは情報システム部門の方がChatGPT / Azure OpenAI Service を自社のビジネスで活用することを念頭に記載しています。AIの研究をされている研究者の方や、SaaSに対して生成AIを組み込みたいプロダクトサイドのエンジニアの方は別のアプローチになるかもしれないですので、本ブログをそっと閉じるといいかもしれません。
- 本ブログは簡易的なRAGアーキテクチャを実装してみた方を想定して記載しています。もしやったことがない方は、以下のブログなどを参考に簡易的なRAGアーキテクチャを構築してから読むと良いと思います。
Azure OpenAI Service “on your data” でChatGPTに自社データを組み込む – CloudNative Inc. BLOGs
RAGの基本と課題
ChatGPTは豊富な知識を持っていますが、データベースではありません。ChatGPTは特定の時点の情報でしかトレーニングされておらず、継続的に更新されないため、知識は古くなっています。さらに、公開情報にのみアクセスでき、企業の中にあるユースケース固有の情報に関する知識が不足しています。そのため、ChatGPTは知識の蓄積ではなく、エンジンとして使用することが有効ですし、ChatGPTの一般的な機能とユースケースに関連する特定の情報を組み合わせる方法がユーザー企業としての活用としては主流です。
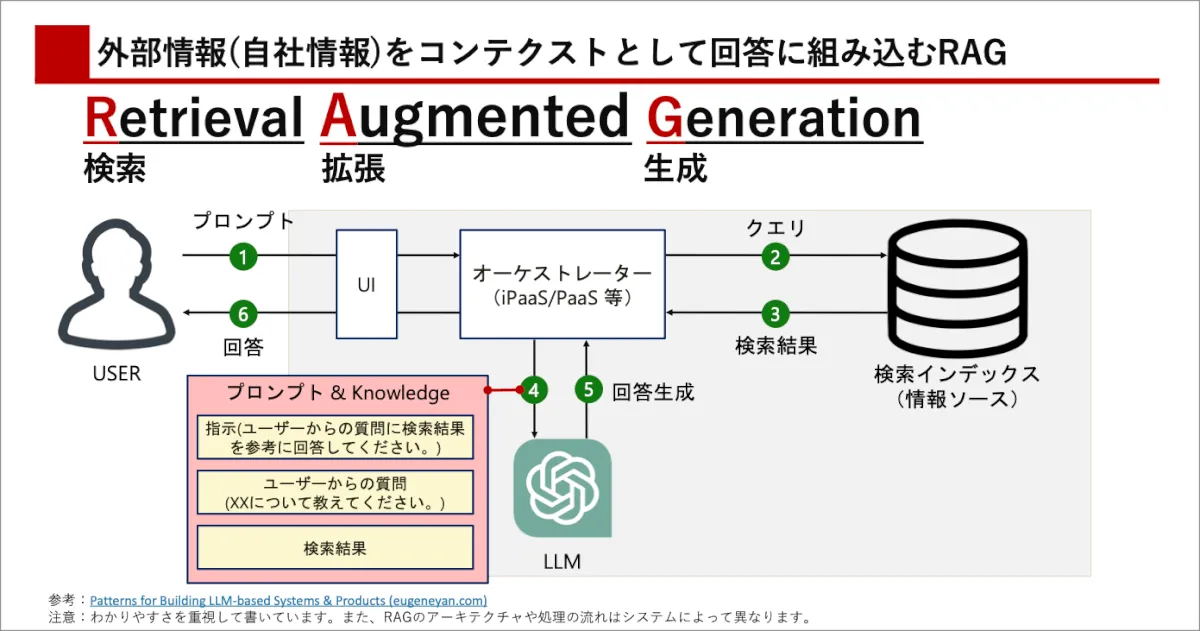
検索拡張生成(RAG)1は、タスクに関連する情報を検索・取得し、プロンプトとともにChatGPTに提供し、応答時にこの特定の情報を使用する手法です。自社データを組み込むことで、自社のユースケースに特化したChatGPTを作ることができることで注目されています。また、RAGを簡易的に実装すること自体はそんなに難しくない状況になっています。一方で、RAGをやってみても業務改善につながるほどの成果(精度)がでないという声も上がっており、精度向上が目下の関心事となっています。
スタートライン:ボトルネックを特定する
まず基本的な考えとして、精度を悪化させているボトルネックを特定するのが重要だと考えています。今回はいくつかのプラクティスを紹介しますが、ただプラクティスを上から順番に実施するのでは非効率です。お金と時間が無限にあるならそれもいいかも知れませんが、実際には以下のような考慮点のトレードオフバランスを保ちながら、適切な方法を選択することが不可欠です。
また、本ブログでは大きく下記の3つの方向性でまとめて、プラクティスを紹介します。
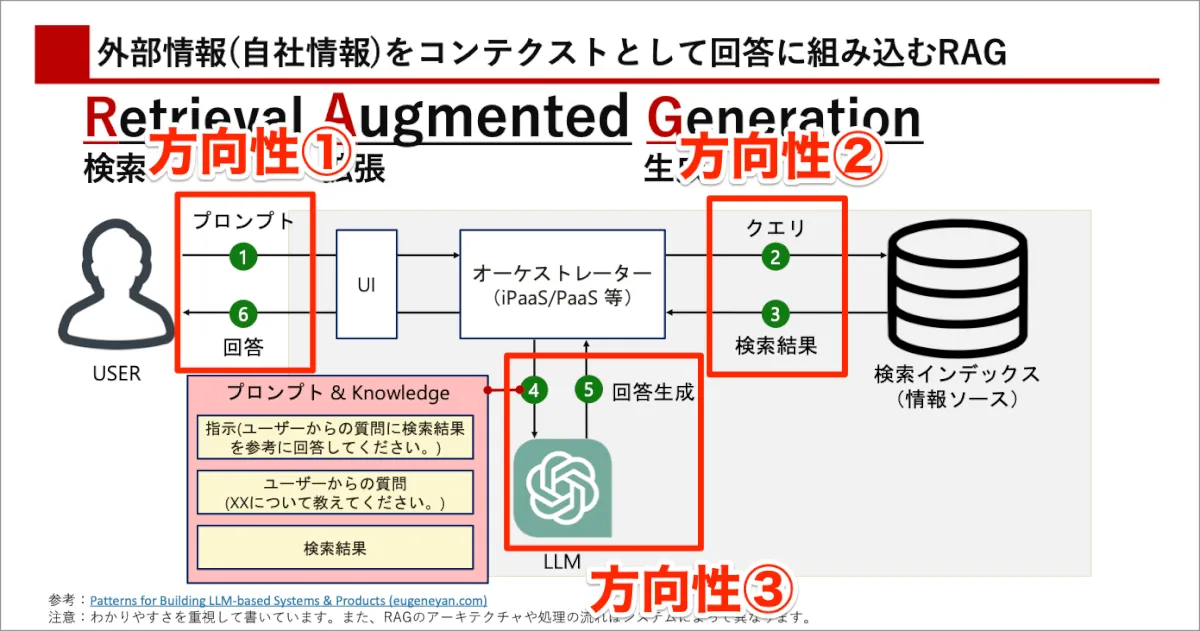
方向性①:プロンプト・回答部分の改善
ユースケースの再考
最初にご紹介するアプローチは、そもそも論ですがユースケースの再検討です。精度が低い問題は一見、技術や手法が問題かと思われがちですが、実際には利用しているユースケースが適切でない場合が多々あります。詳細については、ここでは割愛しますが、ユースケースや解決したい課題、そして「そもそもソリューションはAIなんだっけ?」という根本的な必要性について再度整理することが推奨されます。
特に、ChatGPTではほとんどのユースケースで100点満点の回答はできず、40点程度(筆者主観)がいいとこでしょう。それならば、40点の成果物で嬉しい業務ユースケースに対して適用することが成果をわかりやすくするために重要だと考えています。
システム側でのプロンプトの補足(プロンプトエンジニアリング)
次に、システム側でのプロンプトの最適化です。一部では「プロンプトエンジニアリング」という用語で言及されることもありますが、ユーザーの質問に対して適切なシステムプロンプトを組み込むことが重要です。全てのユーザーがChat GPTの仕組みやプロンプトの重要性を理解しているわけではないため、システム側でこの部分を補完すると効果的です。
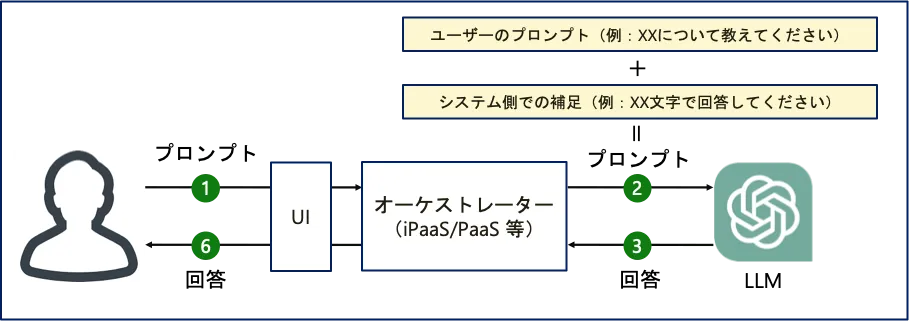
検索結果のユーザーへの提示
このアプローチは、ChatGPTによる生成の結果だけではなく、検索の結果を一緒に表示するアプローチです。ChatGPTの精度に関係なく、検索結果をユーザーに提示することは有効だと考えています。例えば、この情報をユーザーに示すことで、ユーザーが自己解決したり、ChatGPTの出力が間違っているものを検証するなど、システムの有用性を高めることができます。
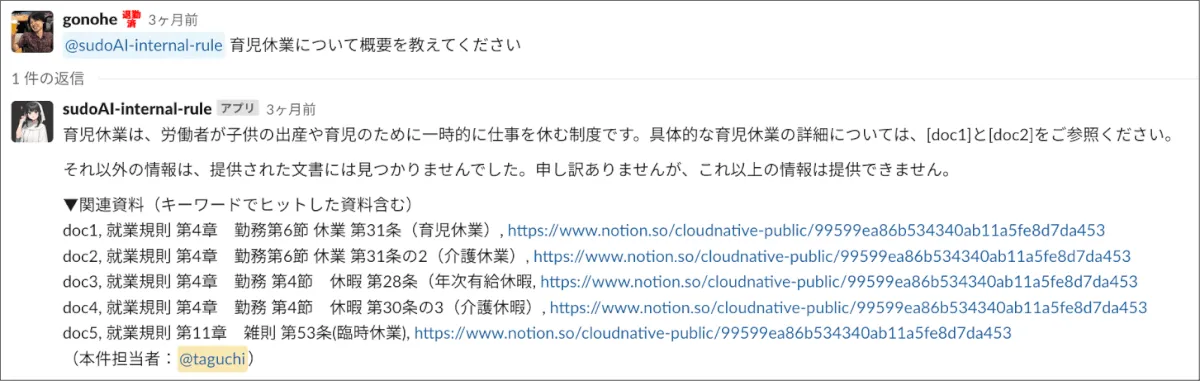
方向性②. 検索(Retrival)部分の改善
インデックスの整備
データのクリーンナップ
正規データとゴミデータが混在している場合、システムの性能が低下するのは通常のシステムでもChatGPTを使ったシステムでも変わりません。ChatGPTはすごいテクノロジーでずがまだ完璧にはほど遠いです。例えば、データをインデックス化する際に重複データの削除や不要・古い情報のクリーンアップが検索の精度を向上させるのに寄与します。検索の部分でゴミがヒットしてしまったら、最終的な出力もゴミになるのは当然の話です。
インデックスの仕方を変える
インデックスの方法を変えるアプローチも有効です。例えば、すべてのデータをインデックス化するのではなく、ドキュメントのサマリーをインデックス化するとノイズが除去されて検索の精度が上がることも期待されます。
当社では、顧客サポートの過去のケースを検索して回答の下書きを作るシステムを構築していますが、過去のサポートケースの情報を全てインデックス化するのではなく、ノイズや顧客固有の情報を排除したサマリーのみを抽出して、インデックス化しています。(セキュリティ的にも効果的です。)ちなみにこの作業自体も正規表現やChatGPTを活用して一部システム的に行っています。

チャンキングの見直し
検索インデックス作成の際、情報を大きなまとまりとして保存するのではなく、小さな単位(チャンク)に分割して保存する方法が一般的です。元々のドキュメントがWord等のファイルだったとしても、インデックス化される際に、1つ1つのチャンクはJSON等の型式で保存されており、最終的に検索結果をChatGPTに返す時にはチャンクの単位で返されます。
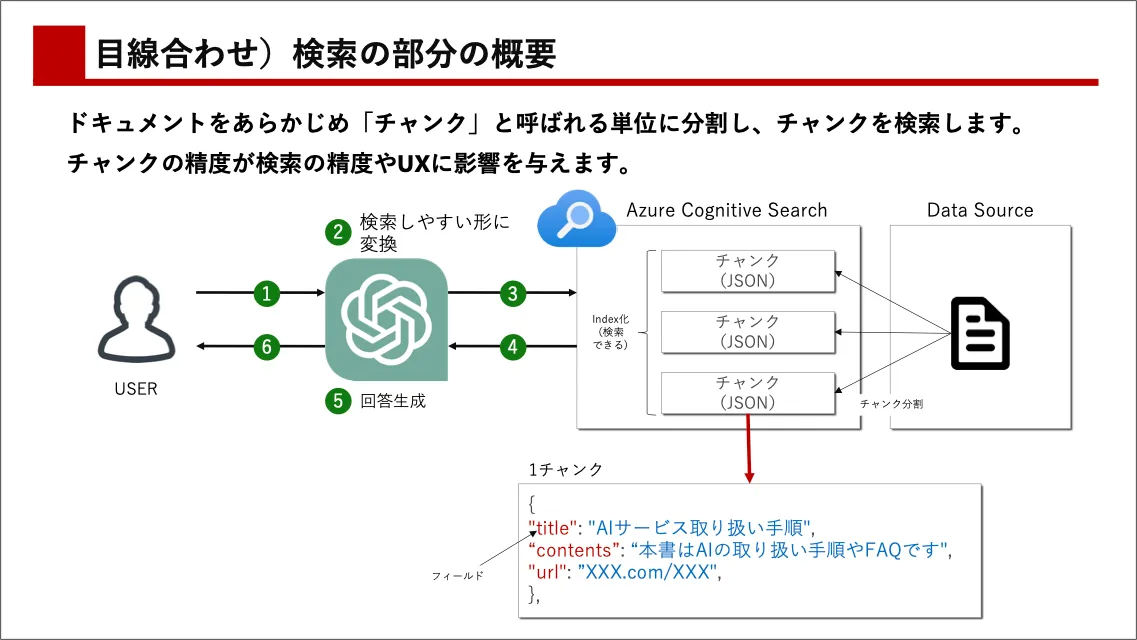
そして、チャンクのサイズや型式をどう作るか(チャンキング)が、検索の精度を大きく左右します。僕も最適なチャンクのサイズについて、日々模索していますが、日本語であれば400文字程度が良いのではと思ったりしています。ちなみに、僕が試している中でのチャンク分割のアンチパターンもまとめておきます。
チャンク分割のアンチパターン
インデックス(チャンク)のフィールド構造の見直し
ChatGPTは「非構造化データ」を処理することに長けていますが、システム全体で見た時に構造化データ(jsonやcsv)を利用することでパフォーマンスを大幅に向上させることができます。例えば、ドキュメントの中身の情報だけではなく、ドキュメントタイトルやセクション情報、日付などのメタデータを含めると、ChatGPTの精度向上に利用できたり、それを別で利用することができます。
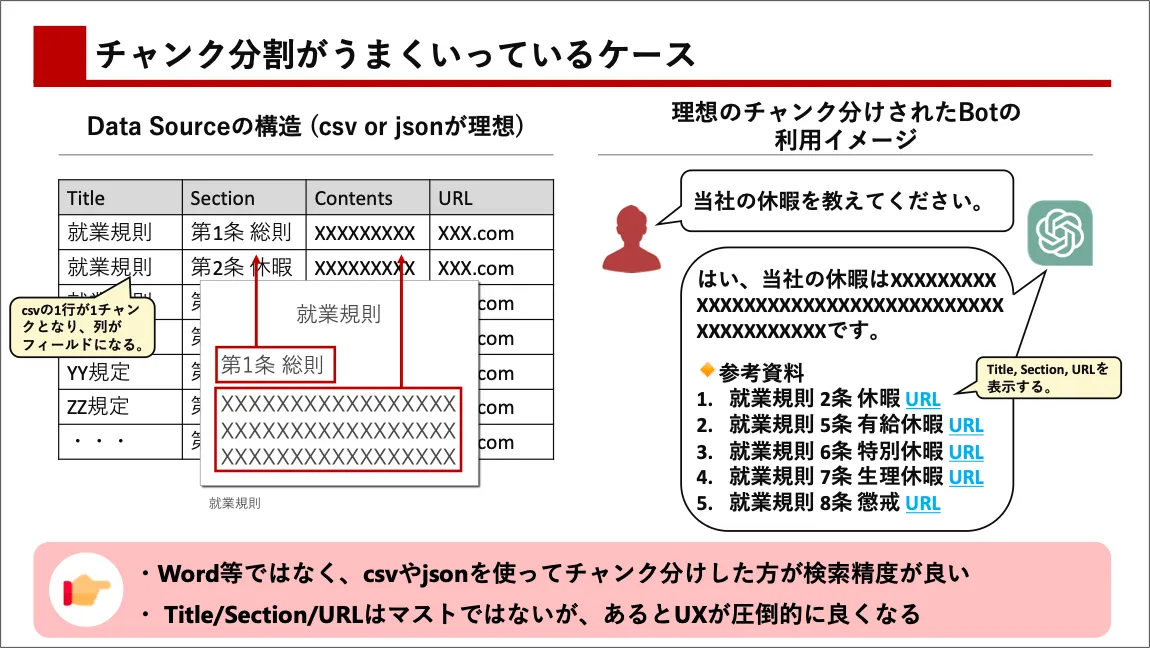
例:ドキュメントタイトルやセクション、URLをメタデータとしてチャンクの中に保持していると、ソースの情報を提示する時に利用することができる。
高度な検索オプションの利用
キーワード検索以外の検索の選択
高度な検索オプションとして、Microsoftが推奨するベクトル検索、セマンティック検索、そしてそのハイブリッド検索を検討することも考えられます。キーワード検索だけでは、キーワードに部分位一致したものが表示されるため、例えば「チワワ」の情報を探している時に、「犬」ような類義語の情報は欠落してしまいます。
まず、セマンティック検索2では、単語やフレーズの意味や文脈を理解して、ユーザーが求める情報に関連するコンテンツを見つけ出します。セマンティック検索の仕組みは、人間の言語理解に似ています。つまり、検索エンジンは単なるキーワードの一致だけでなく、文章内の単語の意味や関係性を理解しようとします。これによって、より具体的で正確な情報を提供できるようになります。例えば「キャピタル」をキーワードにした場合、関連する「タックス」や「マネー」も考慮に入れる方法です。
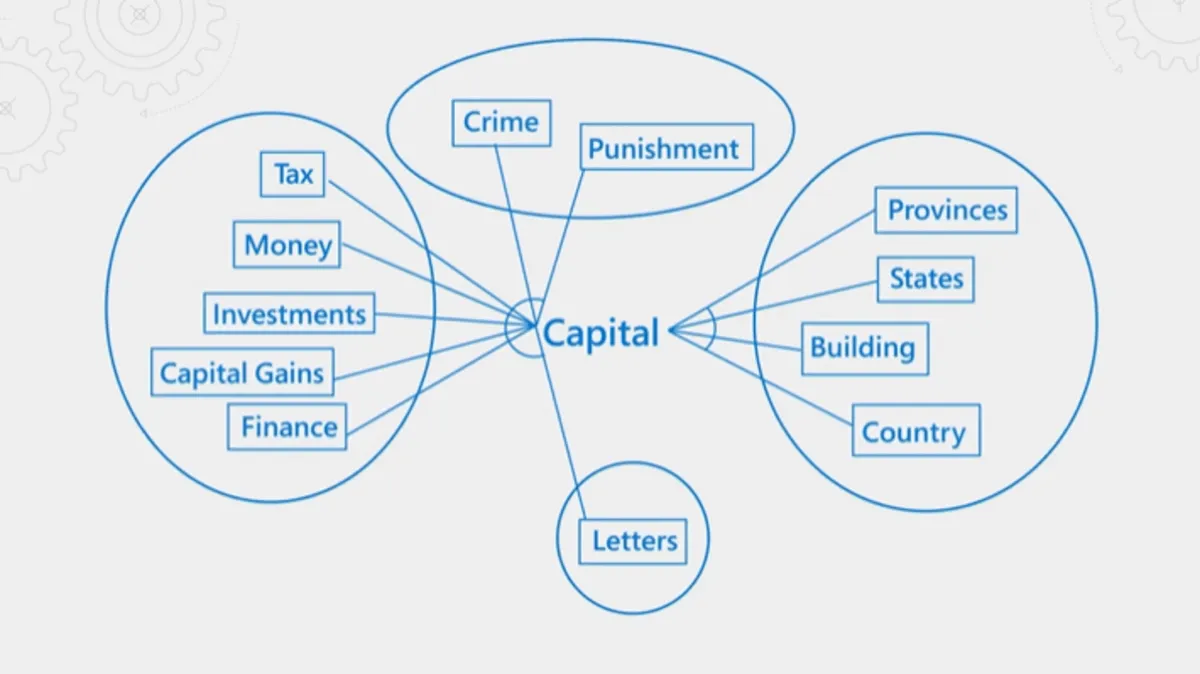
セマンティック検索のイメージ画像(引用:Azure Cognitive Search でのセマンティック検索 https://learn.microsoft.com/ja-jp/azure/search/semantic-search-overview#how-semantic-ranking-works)
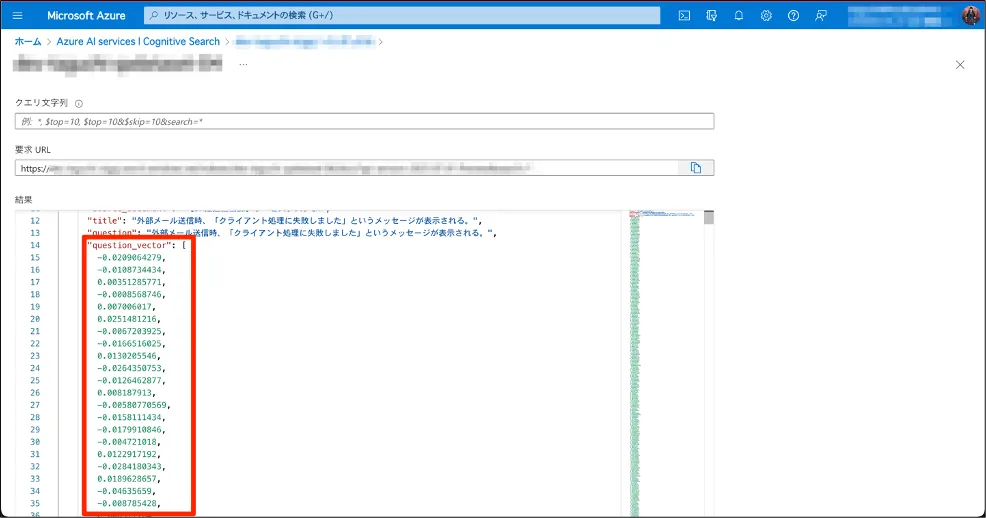
次に、ベクトル検索3では、テキスト、画像、音声などのデータを数学的な「ベクトル」と呼ばれる数値の集まりで表現し、これらのベクトルを使って情報を検索したり、比較するアプローチです。テキストデータをベクトル化する場合、文章内の単語やフレーズを数値で表現します。この数値表現を使って、文章同士の類似度を計算したり、特定のキーワードに関連する文章を探したりすることができます。同様に、画像や音声もベクトル化して、類似した画像や音声を探すことができます。

上記の表では2次元のベクトルを使って簡易的に表現していますが、Azure OpenAI Service の test-embeddign-ada-02 のモデルでは、テキストを1536次元のベクトルに変換して、インデックスに組み込むことができます。
そして、ハイブリッド検索は、キーワード検索やベクトル検索等の手法を組み合わせて最も関連性の高い結果を返すアプローチであり、複数の手法を組み合わせるとより効果的です。
メタデータや別インデックスを使ったフィルタリング
検索の範囲を狭めることで、目的のドキュメントに迅速にアクセスできます。フィルタリングや複数インデックスを用いて、ユースケースに応じて検索範囲を調整するのが一つの方法です。例えば、「社内規定」に関する情報や特定の企業データベースに関するクエリなど、特定のタグやラベルをもとに検索を行うことが考えられます。
スコアリング(重み付け)を使った検索の強化
チャンクの中にはさまざまなフィールドをつけることができますが、そのフィールドの中で重みづけして、検索結果を向上させるアプローチもあります。重みづけにも様々のやりようがありますが、Cognitive Search ではスコアリング機能が提供されているので、これを使って模索していくのが、初手としては難易度が設定までの難易度は低いように思います。ただ、この重みづけに関しては、設定自体はGUIでできて難しくありませんが、効果が実感できるほどの変化をもたらすには試行錯誤が必要であり、初手としてはあまりお勧めしてません。
クエリの変換・複数生成
このアプローチでは、ユーザーの入力した質問を直接の検索キーワードとするのではなく、チャットGPTを活用して関連するキーワードを生成してから検索を行います。ユーザーも人間ですから、目的に対して正しい問いを立てられないことが多いかと思います。そこをChatGPTの力で補ってあげようというアプローチです。例えば、「質問をもとに問題解決のための検索キーワードを複数生成して」とChatGPTに裏側でお願いするアプローチであったり、言語を変換して、英語で検索をかけさせる等のアプローチもあります。
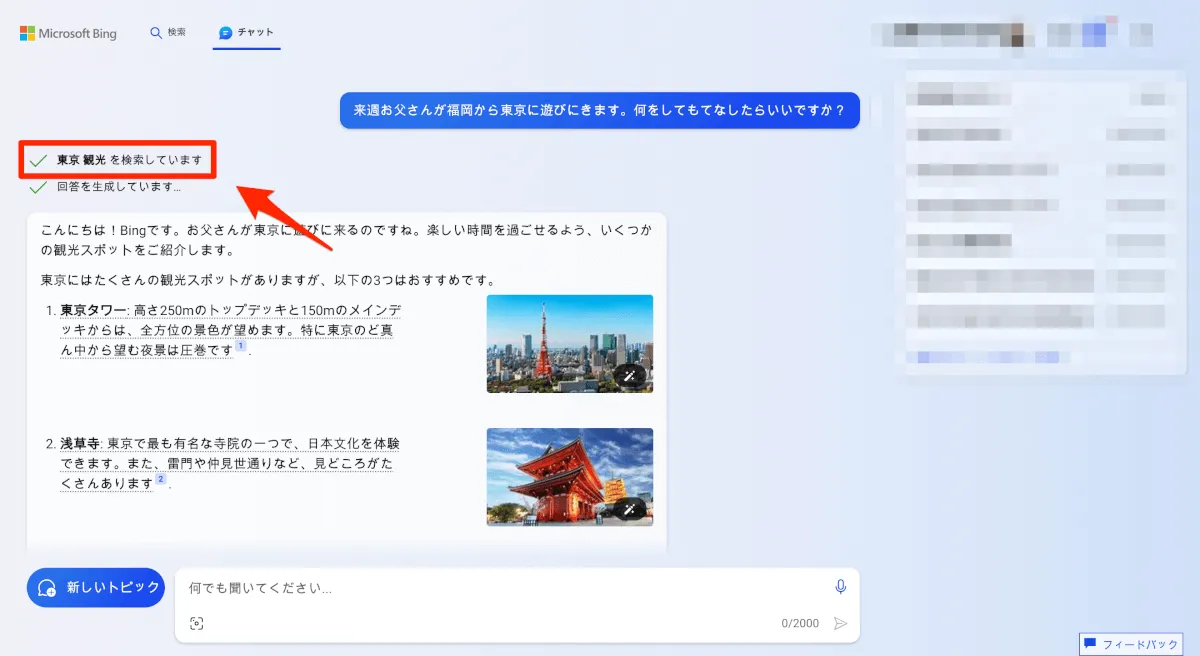
クエリの変換の例としてイメージが湧きやすいのは、Bing Chatの利用時です。プロンプトとしてインプットした以外の情報が検索されることがあり、クエリの変換を実感できます。
方向性③:生成(Generation)部分の改善
より高度なモデルの採用
改善の第一のアプローチとして、より進化したモデルの採用が考えられます。たとえば、チャットGBT-3.5の代わりにGPT-4-32Kを試すなどが考えられます。また、長い文章をコスパよく処理したいのであれば、GPT-3.5-turbo-16kなども良いと思います。ただ、当然、高度なモデルほどコストが高くつきますし、GPT-3.5-turbo-16kとGPT-4-8kであれば10倍ほどの価格差があります。そのため、必要性を強く意識しなければ、ならない手法だと言えます。
翻訳の活用
翻訳API等を活用し、英語でChatGPTを扱うアプローチも考えられます。ChatGPTは、日本語よりも英語の処理に強いとされています。このため、ユーザーからの日本語のプロンプトを翻訳APIを使って英語に変換し、その後生成された回答を再度日本語に翻訳してユーザーに返す方法です。
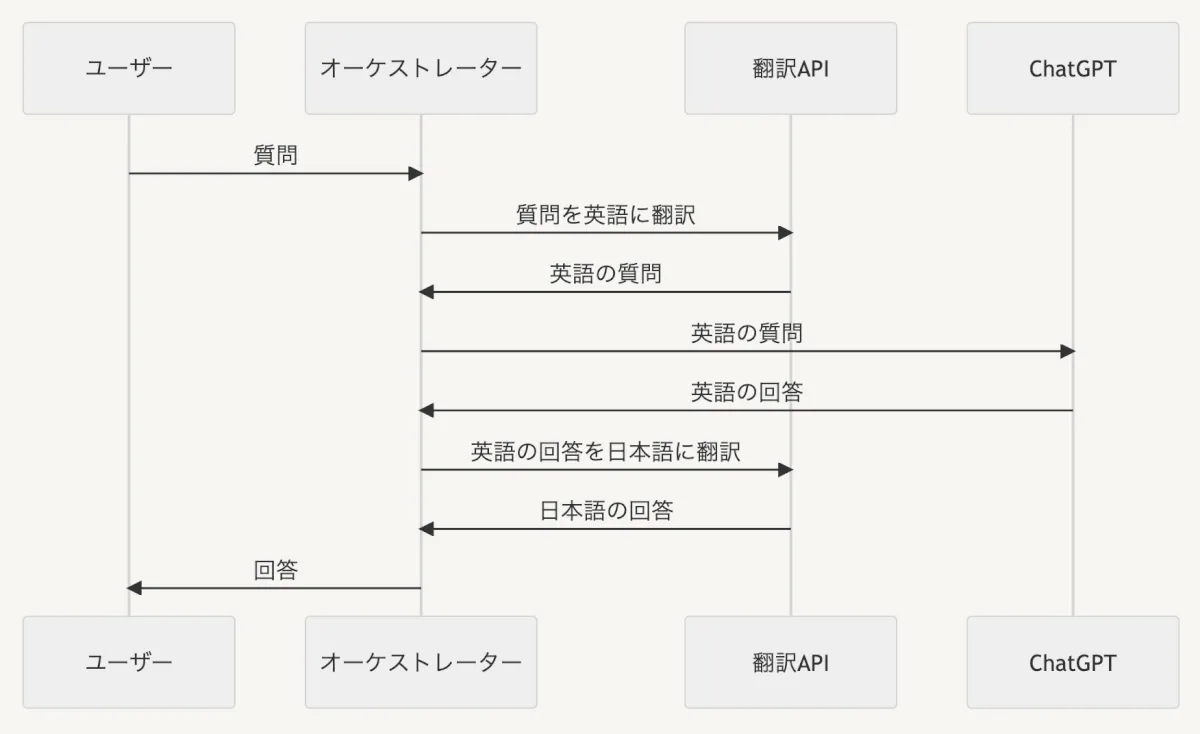
しかし、2回も機械翻訳が挟まるので、翻訳の精度次第では精度が悪くなることも考えられるので、その点の考慮が必要です。このアプローチで確実に保証できるのは長文への対応であり、日本語よりも英語の方が多くの情報をGPTが処理できるので、文章が長くなるケースなどで活用すると良いかと思います。
複数段階の処理
最後に、複数段階の処理を利用するアプローチを考えます。例として、ユーザーの質問に対して一度回答を生成し、その回答を再度ChatGPTにレビューさせる方法などが挙げられます。または、長い文章を要約する際に、事前に文章を分割して、それぞれを要約し、要約されたもの同士をたし合わせて更に要約させる等の作り込みも考えられます。
この手法は、コストパフォーマンスの観点からも、GPT-4のような強力な言語モデルを使うよりも、既存のモデルを複数回使う方が有益な場合があると思います。
逆にあまり情シスの皆様にお勧めしてない手法
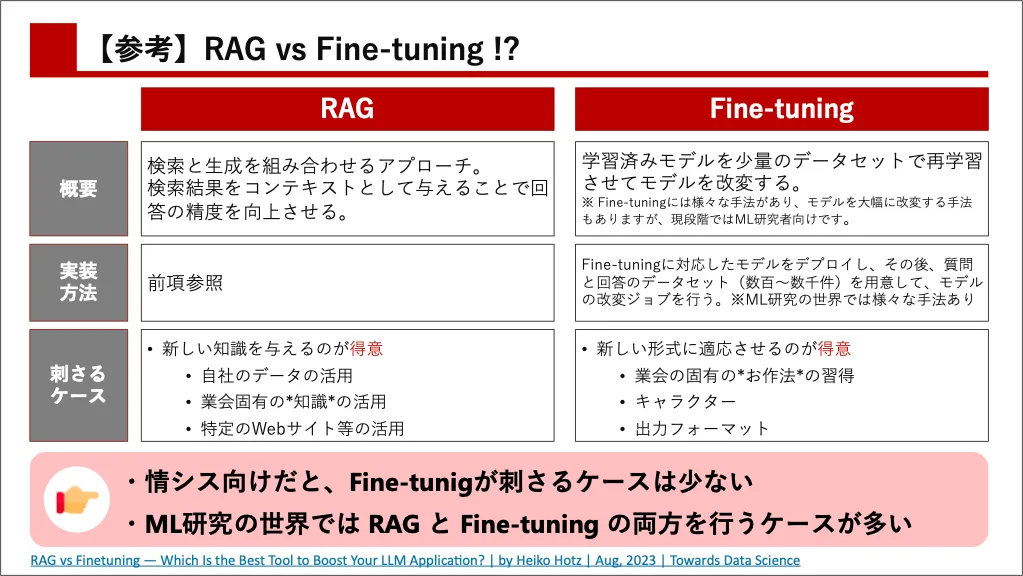
Fine-tuning
そもそもFine-tuning自体に様々な手法がありますが、基本AIモデルのすべてのパラメータを調整する手法と、基本AIモデルの一部を調整する手法があります。そして、基本AIモデルのすべてのパラメータを調整する手法は、言語モデルを作るのと近しい領域なので、情報システム部門にお勧めできないのは言うまでもありません。これをやるにはアカデミックよりに近い専門知識が必要な領域です。
一方、モデルの一部を調整するFine-tuningであれば、それをやること自体はそんなに難易度は高くありません。しかし、それで成果を上げるのは別の話です。モデルの一部を調整するFine-tuningをやったところで、精度はほんの数%しか向上しないか、ほぼ実感がないのがコンセンサスとなっており、こちらも情報システム部門の皆様にお勧めできるものではないかなと考えています。Fine-tuningに頼る前に、まずRAGの可能性を探求することをお勧めします。
注意
自社のSaaS製品にLLMを組み込むケースなど、超大規模ケースにおいては、RAG+Fine-tuningに関する取り組みが活発に行われているようです。GPT-3.5等のモデルを利用しつつ、RAG+Fine-tuningを使ってGPT-4よりも成果を上げることを目指しつつ、コストを抑える方法は多くの方がトライされています。また、僕自身もISMSに特化したモデルや当社のキャラクターである「あどみんちゃん」っぽいモデルにトライしてはいます。
オープンソースのLLMの利用や様々なベクターデータベースの利用
今回のブログでは、LLMのモデルとしては ChatGPT/Azure OpenAIを、ベクターデータベースとして Cognitive Search を中心に言及してきました。一方で、LLMのモデルとしてはオープンソース含めて様々なモデルが登場していたり、ベクターデータベースとしてもPinecone、Weaviate、QDrant などの専用のベクターデータベースが登場しています。
これらのテクノロジを検証して、自社に取り込んでいくことは有益にはなると思いますが、特にAIの基盤モデルの部分を中心に変化の早い領域です。そのため、検証していると別の良いものが出てきたり、OpenAIが新しいバージョンのモデルを出してきてまた比較しなくてはならなくなったりと、振り回される懸念もあります。また、SaaS型のシステムであれば、セキュリティチェックも欠かせません。そこで情報システム部門としては、AzureなりAWSなりの機能をメインで利用しながら、自社の課題や業務プロセス、データライフサイクルマネジメントに向き合っていく方が高い成果が上がるのではと言うふうに考えています。
注意
当然、状況によって異なるので、自社の置かれている状況や自身の立場等を勘案して、戦略を決めていただけたら幸いです。
おわりに
とりあえず、網羅性とかは捨てて、商談でよくお話しすることをまとめたものなので、ツッコミどころも多いかと思いますが、ぜひご意見のある方は連絡をいただけたら幸いです。
参考文献
- Grounding LLMs – Microsoft Community Hub
- Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities – Microsoft Community Hub
- RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application? | by Heiko Hotz | Aug, 2023 | Towards Data Science
- 2308.01223.pdf (arxiv.org)
注釈
- RAG(Retrieval Augmented Generation):https://learn.microsoft.com/ja-jp/azure/search/retrieval-augmented-generation-overview ↩︎
- セマンティック検索: https://learn.microsoft.com/ja-jp/azure/search/semantic-search-overview#how-semantic-ranking-works ↩︎
- ベクトル検索:https://learn.microsoft.com/ja-jp/azure/search/vector-search-overview ↩︎