セキュリティチームの ぐっちー です。先日のIgnite周りのアップデートにより、Azure AI Search(旧:Cognitive Search)の新しいカスタムスキル「Azure OpenAI Embeddingスキル」でcsvからベクトルDBを比較的楽に作成することができるようになりました。当社はこの処理を今まで、Logic AppsやFunctionsにやらせていましたが、シンプル化できて嬉しい悲鳴です。
めんどくさいベクトルDB構築
企業データを活用したChatGPT活用(ほとんどの場合RAG)を実施する際、特にめんどくさいと思われる作業はベクトルDBの構築です。ベクトルDB(ベクトル検索)は検索の精度を上げるための常套手段ですが、読み込みに使う元データを取得し、ベクトルに変換して検索しやすい状態で保管する作業は、面倒な作業です。もちろん、最近は様々なツールが登場し、難易度は日々下がり続けていましたが、Azure AI SearchでcsvやJSONなどを元データとし、特定のフィールドを取り出して、ベクトル化するフローを構築するのはめんどくさいなと感じておりました。
カスタムスキルで楽にベクトルDBを構築
しかし、Azure AI Searchの新しいカスタムスキルとして登場した「Azure OpenAI Embedding Skill」を使用すると、Azure AI SearchとAzure OpenAIのリソースのみを用いてベクトルフィールドを作成できます。これにより、構築と運用が容易になると思います。
ちなみに、カスタムスキルとはAzure AI Searchのインデクサーが検索したドキュメントの中身のデータを外部 Web API に飛ばして、さまざまなエンリッチメント処理をすることができる機能です。今回はベクトル化の部分で使っていますが、他にもたくさんのユースケースがあります。
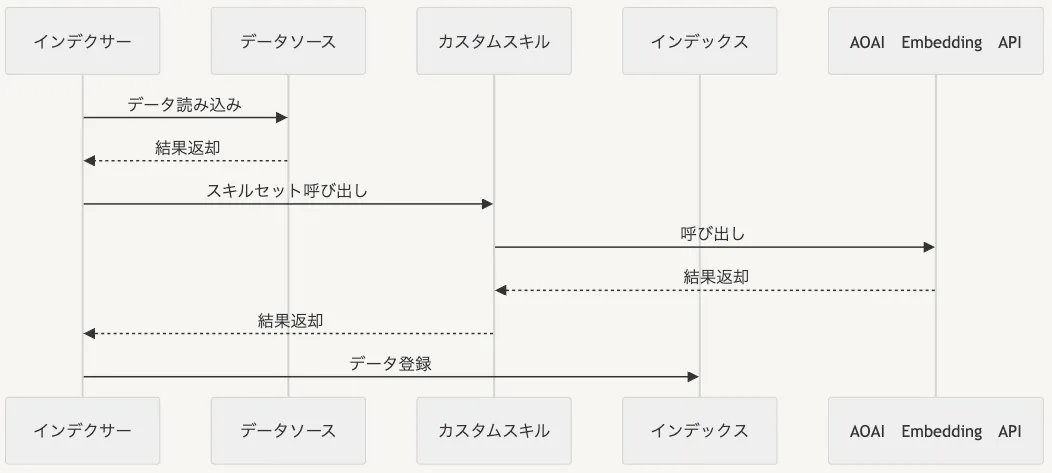
事前準備
今回は、以下の様な構造のCSVサンプルデータを使用し、特定のフィールドをベクトルに変換して保管するチュートリアルを紹介したいと思います。
| id | category | source_document | title | question | answer | url |
| 1 | 人事 | 規定1 | 元気か? | 元気ですか? | 元気です。 | [xxx].com |
| 2 | IT | 規定2 | パソコンが壊れた | パソコンが壊れました。 | 再起動してください。大体直ります。 | [xxx].com |
また、Azure AI SearchとAzure OpenAIのリソースを作成し、Azure OpenAIでは、text-embbeding-ada-002をデプロイしておきます。
インデクスの作成
まずは、普通にAzure AI Searchインデックスを作成します。ストレージアカウントのコンテナにcsvファイルをアップロードし、[ストレージアカウント] > [(右のバーの)Azure Search]からインデックスを作成します。データ接続時の設定で、今回使う対象ファイルがcsvなので読み込みには区切り文字を利用します。
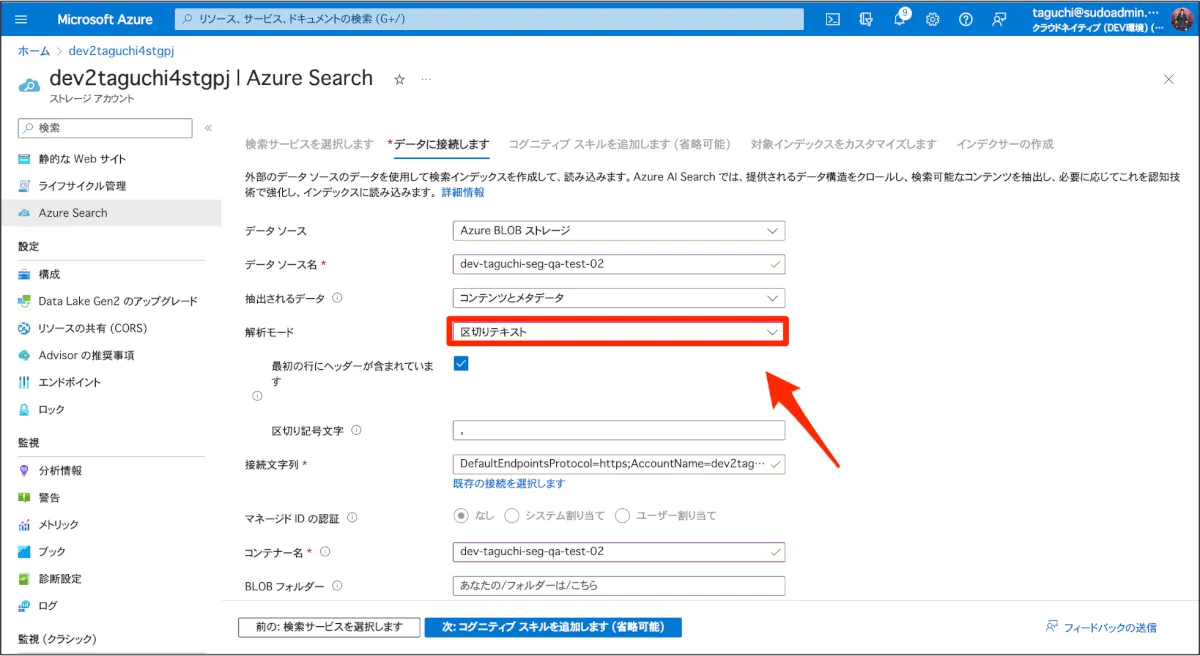
[コグにティブスキルを追加します]は省略可能ですが、[対象インデックスをカスタマイズします]ではベクトル化したデータを格納するベクトルフィールドも作成しておきます。
![[型] より [Collection(Edm.Single)] を選択します。また、今回はAzure OpenAI(text-embedding-ada)を使うのでディメンションは1536を入力します。さらに、[ベクター化]ではデプロイしたtext-embedding-adaのモデルを選びます。](/assets/images/notion/e17e356ca9d5.webp)
カスタムスキルの設定
続いて、Azure AI Searchのカスタムスキルの設定です。[Azure AI Search] > [カスタムスキル] よりカスタムスキルのJSON定義に遷移し、以下のように設定します。赤字の部分は自社の情報に変更をしてください。
{
"@odata.context": "https://<CognitiveSearchName>.search.windows.net/$metadata#skillsets/$entity",
"@odata.etag": "\"0x8DBEA935C98187C\"",
"name": "<カスタムスキル名>",
"description": "test",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#1",
"description": "",
"context": "/document",
"resourceUri": "https://<YOUR_AZURE_OPENAI_NAME>.openai.azure.com",
"apiKey": "<YOUR_AZURE_OPENAI_API-KEY>",
"deploymentId": "<YOUR_MODEL_DEPLOYMENT_ID>",
"inputs": [
{
"name": "text",
"source": "/document/question"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "embedding"
}
],
"authIdentity": null
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.DefaultCognitiveServices",
"description": null
},
"knowledgeStore": null,
"indexProjections": null,
"encryptionKey": null
}その後、インデクサーのJSON定義を編集し、カスタムスキルを登録したら準備完了です。[Azure AI Search] > [インデクサー] > [対象のインデクサー] よりJSON定義を開き、赤字の部分を変更してください。
{
"@odata.context": "https://[CognitiveSearchName].search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\\"0x000000000000000\\"",
"name": "dev-datasearch",
"description": "",
"dataSourceName": "<読み込むデータソース>",
"skillsetName": "<先ほど設定したスキルセット名>",
"targetIndexName": "<登録先のインデックス>",
"disabled": null,
"schedule": {
"interval": "P1D",
"startTime": "2023-01-1T00:00:00.000Z"
},
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": null,
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "delimitedText",
"firstLineContainsHeaders": true,
"delimitedTextDelimiter": ",",
"delimitedTextHeaders": ""
}
},
"fieldMappings": [
{
"sourceFieldName": "AzureSearch_DocumentKey",
"targetFieldName": "AzureSearch_DocumentKey",
"mappingFunction": {
"name": "base64Encode",
"parameters": null
}
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/embedding",
"targetFieldName": "embedding"
}
],
"cache": null,
"encryptionKey": null
}
オプション:デバッグセッション
また、オプションではありますが、デバッグセッションを利用すると、作成したカスタムスキルが正常に動作するかを動作確認することができます。インデクサーをゴリっと実行する前に、様子を見たい場合などには利用していただけたら幸いです。デバッグセッションは[Azure AI Search] > [デバッグセッション] より作成できます。
動作確認
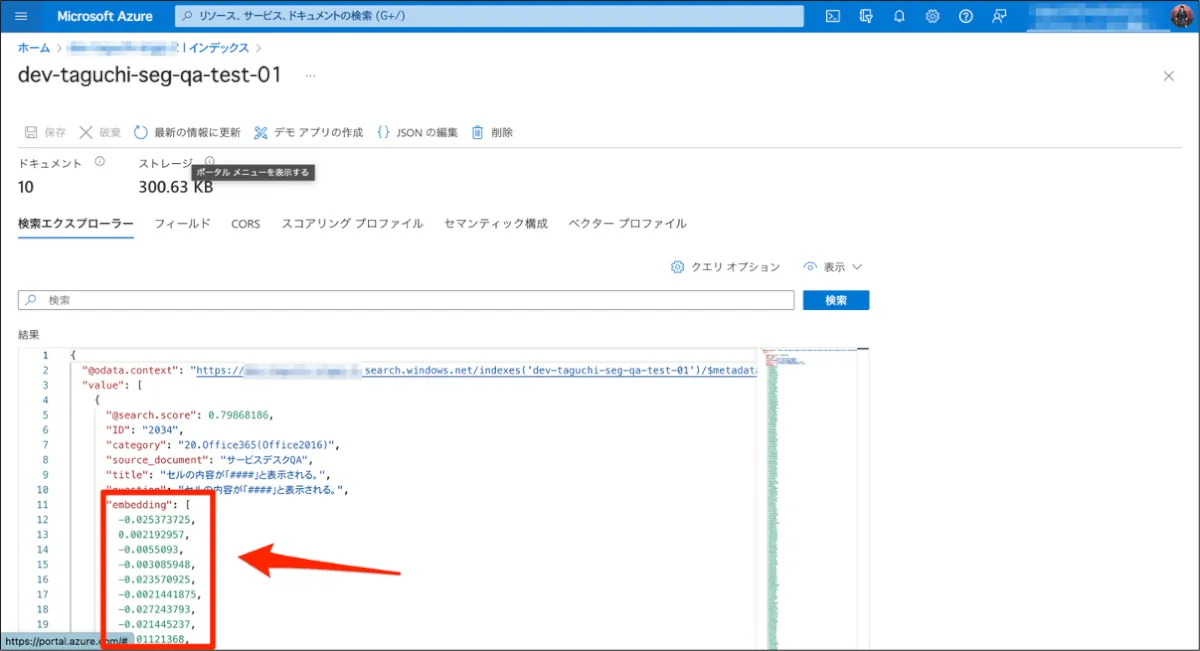
[Azure AI Search] > [インデクサー] より対象のインデクサーを開き、一度インデクサーをリセットします。その後、再実行を行うと、カスタムスキル付きのインデクサーが実行されます。処理が終わったら、[Azure AI Search] > [インデックス] よりテストのクエリを実行すると、ベクトル化されたデータがembeddingフィールドに格納されていることがわかります。
おわりに
以前はAzure AI SeachでのベクトルDB構築のために、FunctionsやらLogic Appsを使わないといけませんでしたが、非常に楽になったなっと実感します。ドキュメントがすごくわかりにくいのはなんとかしてほしいですが、Azureの進化の速度には目を見張るばかりです。