セキュリティチームの ぐっちー です。 最近のAIブームにより毎日のように自社データを使ったChatGPT活用に関する商談をやっていますが、そこで、かなりの確率で質問されることをブログにしました。権威ドキュメントや公式ドキュメントの情報を元にしたものではないので、網羅性には欠けると思いますが、参考情報として見ていただけたら幸いです。
ご注意
- 本ブログの内容は、2023年10月10日時点までの情報を元に作成しております。
- 個人的な経験や検証結果を元に記載しており、網羅性/MECEなどは考慮してません。
- 本書の想定読者は情報システム部門の担当者です。
- 実際にアクセス制御を実施する場合には、自社のユースケースを考慮して実装いただけたら幸いです。
自社データを使ったChatGPTの代表的な考慮点
ChatGPTは、情報を生成する際に、一部の情報を誤って組み合わせたり、存在しない情報を捏造する可能性があり、ビジネスの現場では使えないという声をよく聞きます。これは最新のトピックや複雑なトピック、厳密さが求められるトピックについて話すときに特に顕著になります。
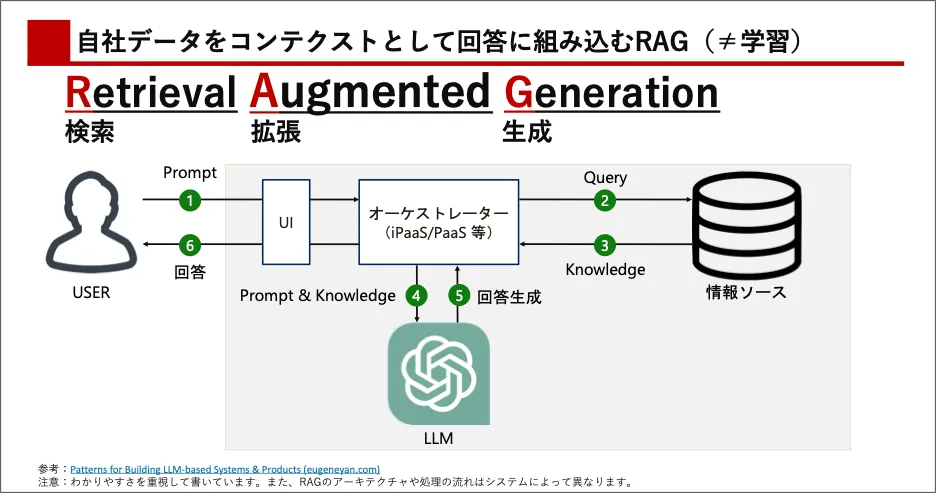
この問題を解消するためのアプローチの一つがRAG(Retrieval Augmented Generation)1です。これは、ユーザーから質問を受けた際、生成AIが回答する前に、基礎モデルの外部データソースからデータを取得し、取得した関連データをコンテキストに追加して回答します。このように、情報検索(取得)と生成の2つのステップを組み合わせることで、生成AIの回答の精度を向上させることができます。
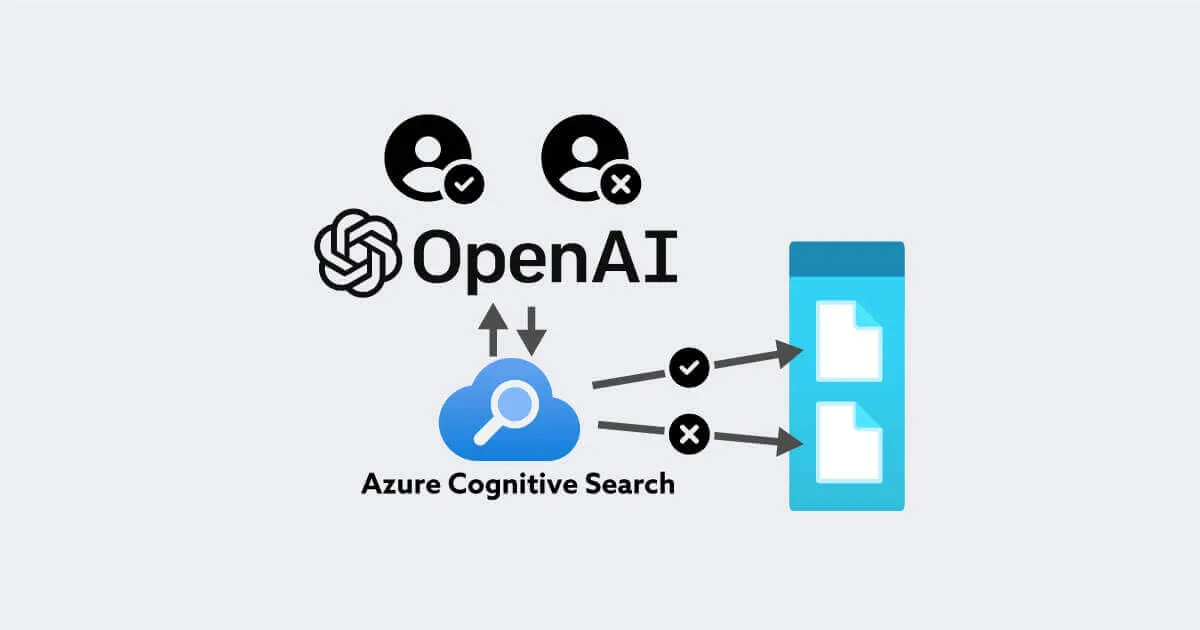
このアーキテクチャーにおいて自社データを使う場合は、アクセス権の制御が問題として上がります。例えば、「公開されていない経営会議議事録」などの重要な情報をChatGPT経由で一般社員が閲覧してしまうと、情報セキュリティインシデント以外の何者でもありません。
大事にしていること
自社データの活用したChatGPT(RAGアーキテクチャ)を実装する上で、僕が大事にしていることは「アクセス権の変わらないように設計する」と、「ChatGPT(LLM)にアクセス制御ロジックを持たせない」という点になります。「アクセス権の変わらないように設計する」ことは基本中の基本ですが、加えて「ChatGPT(LLM)にアクセス制御ロジックを持たせない」ことも重要だと考えています。
ChatGPTの内部の仕組みは基本的にブラックボックスですし、LLMは良くも悪くも回答は安定しません。プロンプトインジェクションと言われるようにプロンプトを工夫することで、意図しない動作を引き起こそうとする攻撃も存在ます。そのため、厳密さが求められるアクセス制御を任せられる段階にはなく、ChatGPT(LLM)以外の地点でアクセス制御の実装を行うことがポイントだと考えています。(技術進歩が早いので、未来では「ChatGPTにアクセス制御させた方がコスパいいよね」という風に変わっているかもしれませんが、そんな時代が来たらしれっとこの部分削除します。。。)
そもそもアクセス制御の必要性のない(薄い)情報を取り扱うパターン(ユースケースの再検討)
この問題に対処するために最もシンプルな方法は、ユースケースを再整理して、アクセス制御の必要性のない/薄い情報を取り扱うことです。
例えば、Box(クラウドストレージ)内の全ての情報を一括で取り出してチャットで検索可能にするというアプローチはアクセスコントロールを実装することが骨が折れます。そのため、例えば「社員全員が既にアクセス権限がある社内規定」に限定したチャットボットを作成するなどのアプローチが費用対効果が高くなることがあります。
また、このようなアプローチを取ることは、アクセス制御の観点だけでなく、実用的なChatGPTの活用においても非常に有用だと考えています。ChatGPTにデータを雑に読み込ませると成果が上がらないという事例も沢山報告されており、特定のタスクに特化した形でChatGPTを提供するアプローチも盛んです。そのため、実用的なChatGPTを活用する観点もで、ユースケースをきちんと整理してデータを絞り込むことは特に重要です。
入り口・検索インデックス・出口を分けるパターン
次に考えられるアプローチは、入り口、検索インデックス、出口を分けるパターンです。例えば、営業部門の方は「営業チャンネル」のチャットボットを使用し、経営企画部門の方は「経営企画チャンネル」のChatGPTを使用するといった入り口の分け方があります。このように、入り口を分けることで検索インデックスの部分も独立して実装し、アクセス制御することができます。
また、入り口と出口は一緒でも検索インデックスだけを分けてあげて、内部の実装でユーザーやグループ単位でルーティングするアプローチもあります。(作るの大変そうですが。。。)
メタデータを使ったフィルタリングするパターン
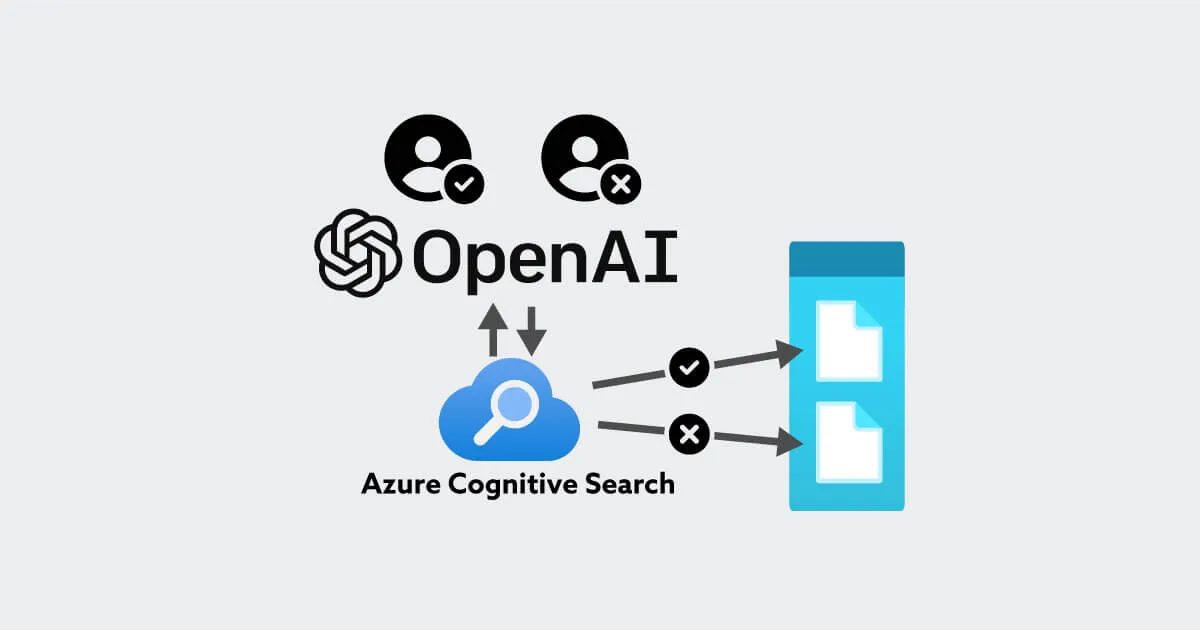
次に紹介するアプローチはメタデータを用いてのフィルタリングです。当社で検証実績のある手法としては、Cognitive Search を利用したフィルタリング方法が挙げられます。
例えばBox上のコンテンツをチャンク分割して Cognitive Search の検索インデックスを作成する際、メタデータとして「A部門だけがアクセス可能」というような情報を付与しておきます。そして、検索をする時に、そのメタデータを基にフィルタリングを行い、検索結果絞り込んで表示します。

詳しくは、当社のすかんくがブログを書いているので、そちらをみていただけたら幸いです。

ユーザーの認証情報を使った検索をするパターン
次に紹介するのは、ユーザーの認証情報を利用して検索する方法です。このパターンは実例として、「Slackを通じてBox上のデータを検索するユースケース」を例に紹介します。まず、ユースケースとしてはユーザーがチャット経由で質問を投げたら、ChatGPTの Function Calling を使ってユーザーが目的を達成するために必要なFunctionや検索キーワードを生成し、その後BoxのAPIを叩いてBoxのコンテンツ検索結果を取得し、ユーザーに表示します。
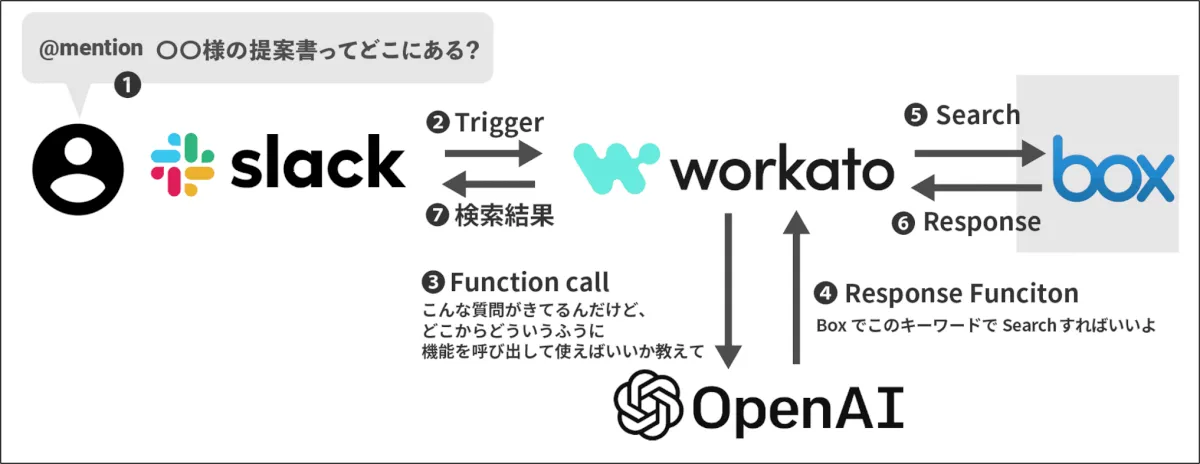
Slackを通じてBox上のデータを検索するユースケースの簡単な流れです。ただし、このフローにはRAGのG(Generatoin)は含まれていません。
その中で Box API を利用する際に、ユーザーの認証情報を使用して、アクセス可能な情報だけを取り出すのがこのアプローチのポイントです。この実装では Workato の特許技術である「実行時ユーザー接続2」を使って、ユーザーの認証情報を連携していたりします。詳細は当社の Workato マスターの俊介がブログを書いてくれることでしょう……!
注意
Workatoの機能を使って実装していますが、検索先SaaSによっては対応が難しいことがあるので、ご了承ください。また、Workatoを使わない場合でも、API経由で一旦ユーザーがアクセス可能なフォルダ/ファイルを取得して、そこを検索すると、理論上同じことができるとは思いますが、処理が多段になってレスポンスが遅くなったり、そもそも開発が大変だったりすることが予想されます。
URLだけ表示するパターン
続いてのアプローチは、URLのみを表示する方法です。Boxの検索を例にすると、ユーザーが「提案資料を探してほしい」という問いかけをした場合、詳細情報を見せずに検索結果のURLだけを提示するアプローチです。これにより、Box上でアクセス権が制限されている情報は最終的には見えなくなります。
ただし、この方法の欠点は、ファイルの存在自体が知られてしまうことです。例えばある大手企業との事業提携計画などの情報などは、その存在が知られるだけで問題となる場合があります。その点には注意が必要です。また、これはそもそもRAGとは言えなくて、完全に検索をしているだけで生成は諦める形となります。さらに、アクセスできない情報が表示されるとUXも悪くなるので、実際使い所が難しい手法ではあると思います。
サニタイズ(無害化)処理を行うパターン
最後に紹介するのは、サニタイズ(無害化)処理を行う方法です。このアプローチでは、ユーザーがChatGPTに質問し、回答が返されるまでの間に、重要な情報が含まれていないかをチェックし、必要に応じて情報を削除する無害化の処置を講じます。
具体的な事例として、当社の顧客サポートシステムでこの手法を採用しているので紹介します。まず前提となる業務の流れですが、お客様が当社からご購入いただいている製品に関する問い合わせを投げかけた場合、ChatGPTが類似の過去のチケットを検索し、それに基づいた回答を生成します。
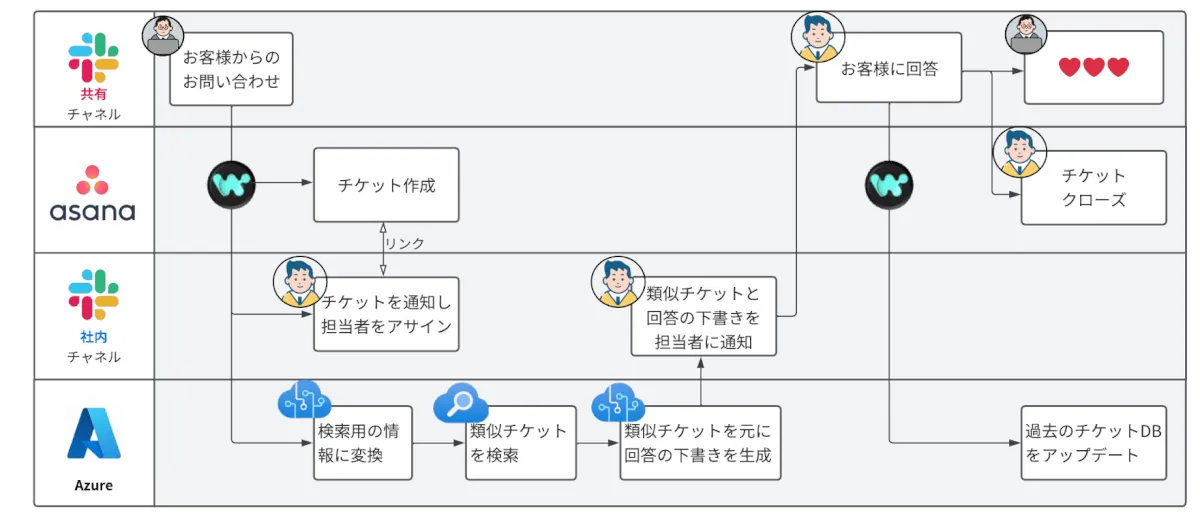

この際、ChatGPTが生成する成果物は直接お客様には見せず、一度当社のエンジニアがチェックし、必要に応じて情報の無害化処理を行った上で回答としてお客様に提示するのがポイントです。
加えて、この仕組みでは合計3段階のサニタイズ処理は行っています。1段階目はお客様に回答する前ですが、2段階目・3段階目として過去の問い合わせデータベース(Blob/Cognitive Search)に情報を格納する前に、Workato等のシステムを用いて、お客様の情報を削除処理しています。このシステム的な処理の後、更に運用担当者が内容を確認し、処理に漏れがないかを再チェックしています。もし漏れがあれば、その情報を削除した上で、データベース(Blob/Cognitive Search)に情報を追加する流れとなります。
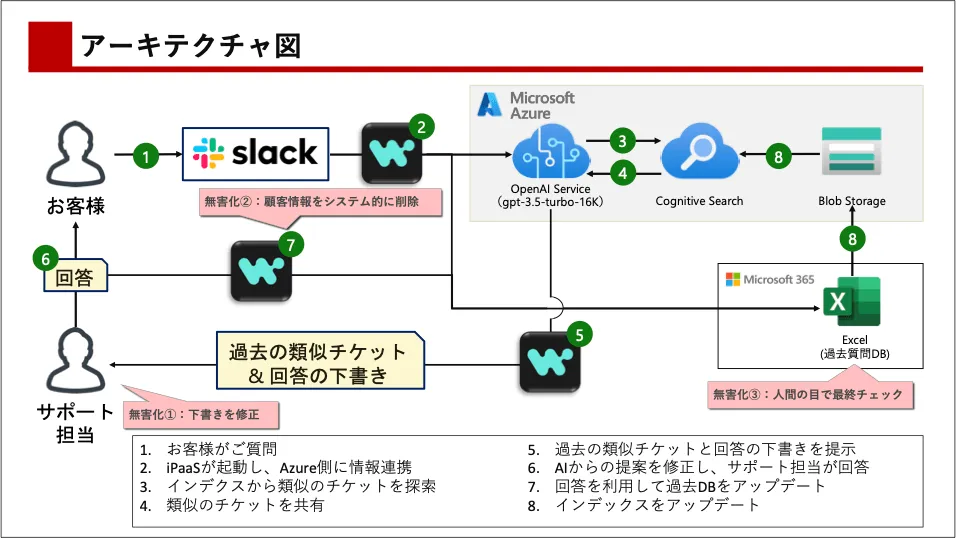
このように当社では複数の手続きを経てお客様の情報が他のお客様に閲覧可能とならないようなアーキテクチャを実装していますし、ユースケース次第ではこのようなアプローチもありなのではと思います。弱点としては、サニタイズを行っている分だけ、回答が質問者に届くまでに時間がかかるという点があるので、リアルタイムの回答を必要としないユースケースを選定することが重要です。
おわりに
冒頭でお話しした通り、このブログは私の日々の経験をもとにまとめたものであり、公式なドキュメントや権威ある情報ではありません。他にも効果的なアプローチや異なる意見があるかと思いますので、それに関するご意見や情報をお待ちしています。
注釈
- RAG(Retrieval Augmented Generation):RAG and generative AI – Azure Cognitive Search | Microsoft Learn ↩︎
- 実行時ユーザー接続:https://docs.workato.com/ja/features/runtime-user-connections.html ↩︎