セキュリティチームの ぐっちー です。以前、Azure OpenAI Service “on your data” でChatGPTに自社データを組み込む というブログを書きましたが、読者の皆様から「精度どんなもん?ビジネスで使える?」という質問をよくいただきます。私はLLMの研究をしているわけではないので「XX%の精度がでました!」という話は難しいのですが、実務目線でできる限りのアンサーブログを書きたいと思います。「ChatGPTと簡易な作り込みで作ったBotがどれだけ役に立つのか?どれだけ役に立たないのか?」を理解する一助となればと思います。
3行サマリー
- 自社データを組み込んだChatGPTを作る手段は複数ありますが、Azure OpenAI の on your data 機能がノーコードで手頃に始めることができる手段として期待されています。
- その中で、読者の皆様としては「手頃にやって、どれだけの効果が上がるのか?精度がでるのか?」という点が気になると思い、GPT-3.5を利用して検証してみました。
- 一発で正確な回答を出すツールとして捉えると実用に足るものではないと考えられますが、視点を変えて、社内QAサポートの1次受けつけや、情報検索補助ツールとしては一定の有効性があると筆者は考えています。

情報検索&生成でChatGPTの精度向上
ChatGPTは、情報を生成する際に、一部の情報を誤って組み合わせたり、存在しない情報を捏造する可能性があり、ビジネスの現場では使えないという声をよく聞きます。これは最新のトピックや複雑なトピック、厳密さが求められるトピックについて話すときに特に顕著になります。
この問題を解消するためのアプローチの一つがRAG(Retrieval Augmented Generation)[1] です。これは、ユーザーから質問を受けた際、生成AIが回答する前に、基礎モデルの外部データソースからデータを取得し、取得した関連データをコンテキストに追加して回答します。このように、情報検索(取得)と生成の2つのステップを組み合わせることで、生成AIの回答の精度を向上させることができます。
そして、RAGを比較的簡単に実現する方法として注目されているのが、Azure OpenAI Serviceの「on your data」です。この機能はノーコードでRAGを実現することができるため、これを使った社内QAボットを作成できないかと言う点が話題に上がります。
「精度どうですか問題」について
そこで気になるのが、「RAGを利用するとどれだけ正確になるのか?」と言う点です。ここで、「RAGを使うとXX%の精度が向上しました」と言えたらかっこいいですね。
しかし、ひとえに「RAGを使ったQAボットの精度」といっても、LLMモデル(GPT-3.5/GPT-4)、読み取りデータ(on your data)の性質、言語、検索方式、ユーザーからの質問(ユーザープロンプト)、システムプロンプト、裏側の処理 等々・・・で結果が左右されます。また、たとえ「XX%の精度が出ました」と言ったところで、その数字を見ても読者の皆さんのビジネスに役に立つかは判断が難しいかと思います。そういう観点はLLM研究者の方にお任せしたいと思います。
今回のブログではどのような前提条件で、どの様なデータを読み込ませて、どんな質問をしたら、どういう結果が返ってきたということをひたすら紹介します。その結果を受けて、どの程度の精度が出るのかのイメージを掴んでいただけたらと思います。最終的には「ChatGPTと簡易な作り込みで作ったBotがどれだけ役に立つのか?どれだけ役に立たないのか?」を理解する一助となればと思います。
前提条件の説明
まず、今回の前提条件のコンセプトは手頃に始めることができる手段を使ってと言う点です。実際、RAGの実装方法は無数にありますが、簡単な手法として先ほど紹介したAzure OpenAIのon your data 機能を主軸としつつ、構成は以下のような形としています。
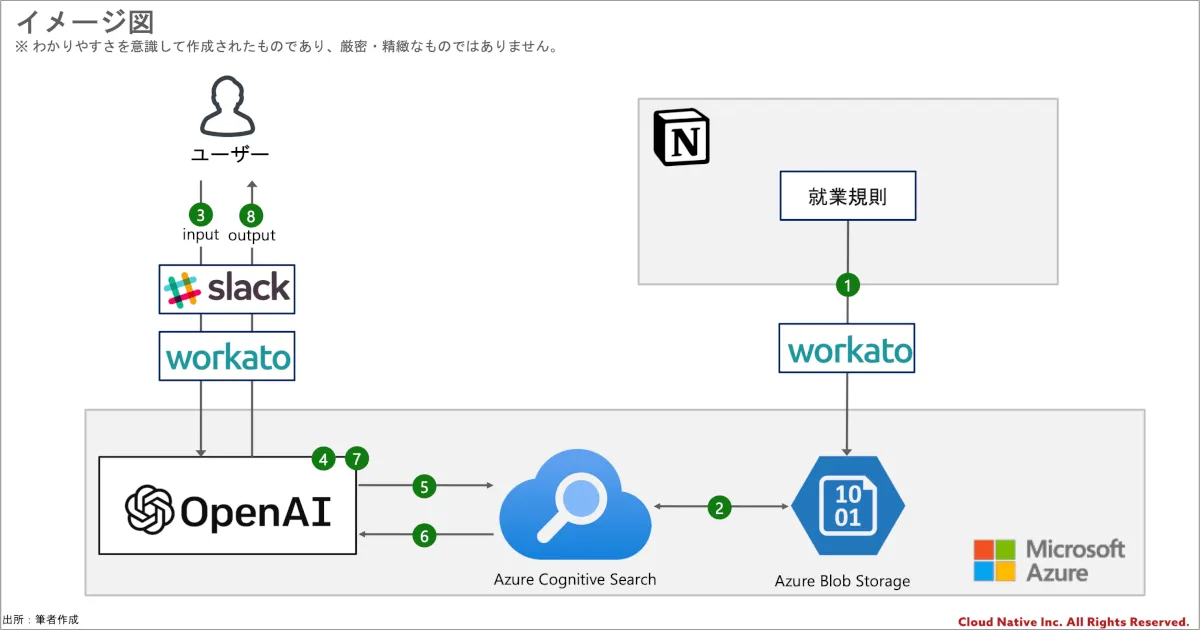
- 就業規則をBlobストレージに格納する
- 格納されたデータを元に検索用のインデックスを作成する
- ユーザーが就業規則について質問をする
- Azure OpenAI がユーザーの質問に回答するための検索のクエリを作成する
- 作成したクエリを使って Cognitive Search のインデックス内を検索する
- 検索結果を Azure OpenAI に返す
- 帰ってきた検索結果を元にユーザーへの回答を生成する
- 回答をSlackの投稿に編集して、ユーザーに回答する
また、今回の様々な前提条件は以下の通りです。
| 項目 | 今回の条件 |
|---|---|
| シナリオ | 従業員が人事に対して就業規則に関する質問を行う。(たまにあえて、問い合わせ窓口を間違えた質問も行う) |
| LLMモデル | gpt-3.5-turbo-16K(2023/6/1) |
| 読み取りデータ (on your data) | クラウドネイティブがリアルに利用している就業規則(公開情報)を利用する。 ※ 読み取りデータそのものを見ながら結果を見た方が、回答の制度のイメージが湧きやすいと思います。就業規則以外の規定は公開情報ではないので、今回は読み込みを行なっておりません。 |
| 言語 | 全て日本語 |
| 検索方式 | キーワード検索のみ ※ セマンティック検索やベクトル検索などの高度な検索オプションは利用していない |
| ユーザープロンプト | 後述 |
| システムプロンプト | ロールでassistantを指定 日本語で回答する様に指定 ※ ここは改良の余地がありますが、一旦シンプルにしています。 |
| Slack・OpenAIの連携部分 | Workatoで実装 |
| Fine-tuning | しない |
| パラメータ | ・最大応答:800 ・温度:0 ・上位P:1 |
回答の精度どんなもん?袋叩きにして検証してみた
上記のチャットQAボットをクラウドネイティブのSlackに召喚し、有志で集まった従業員の方々に袋叩きにしてもらいました。
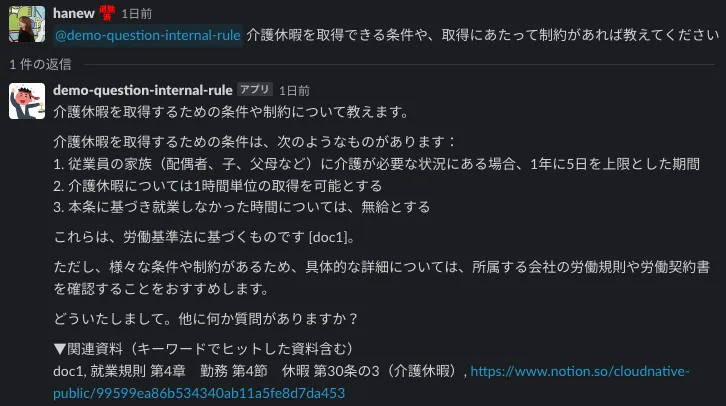
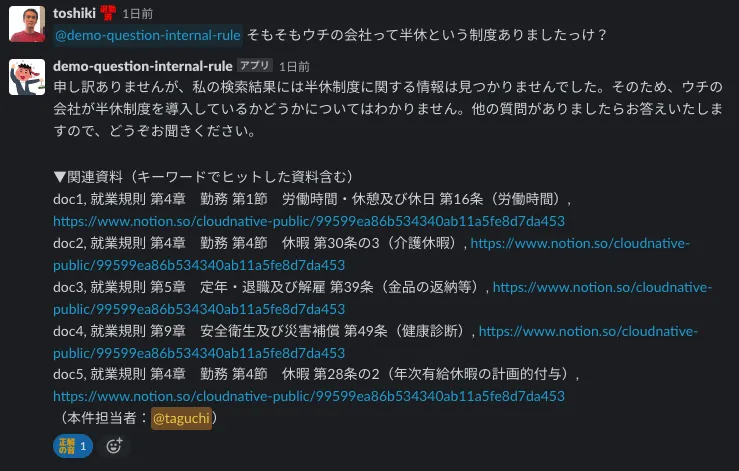
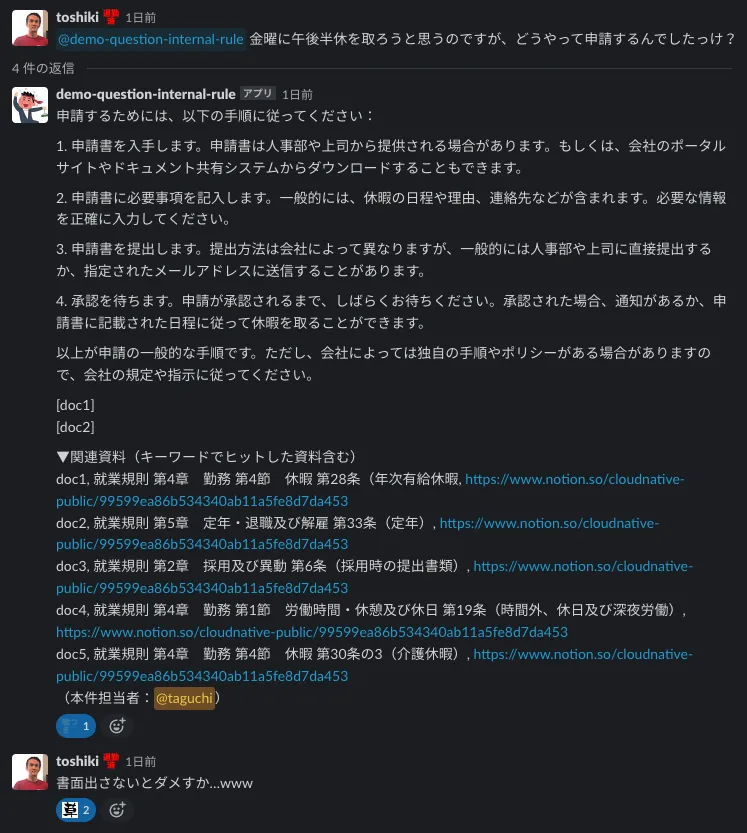
A. 期待した回答をする時
傾向として、質問に含まれるキーワードと、読み取りデータ内の文言が合致した際には、期待した回答が返ってきやすい傾向がありました。キーワード検索なので仕方のない部分かもしれませんが、まずはうまくいった事例から紹介します。
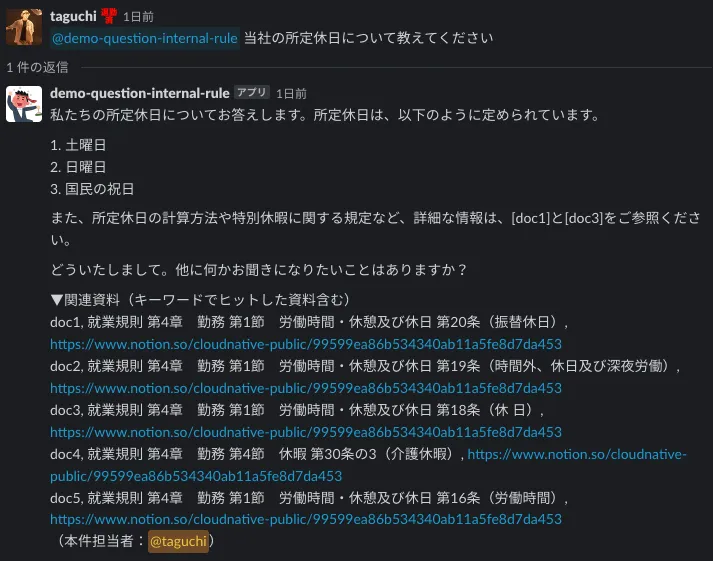
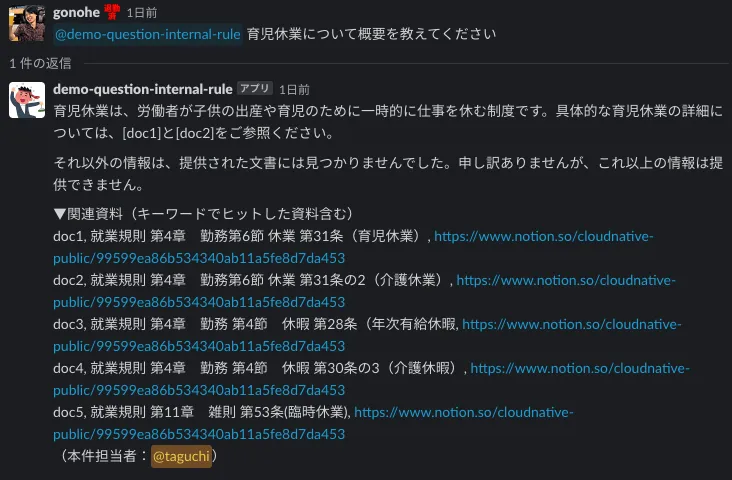
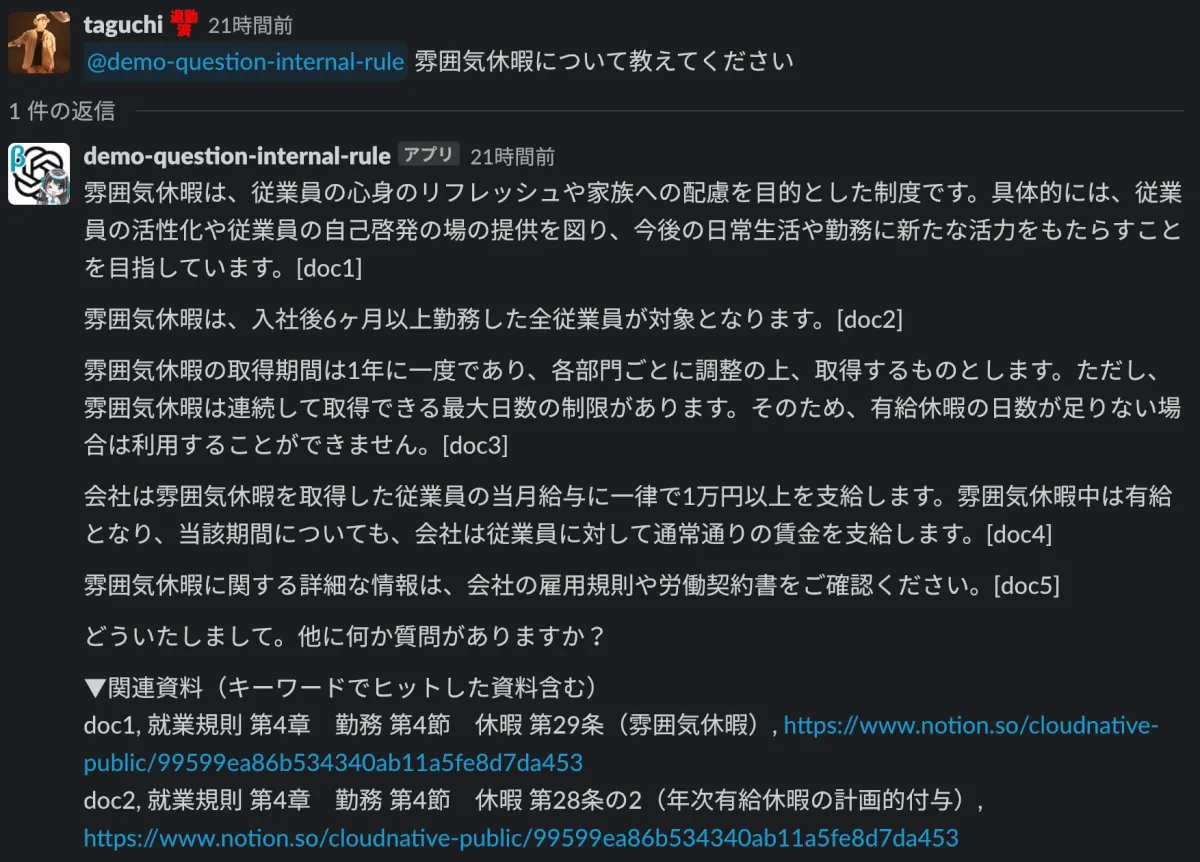
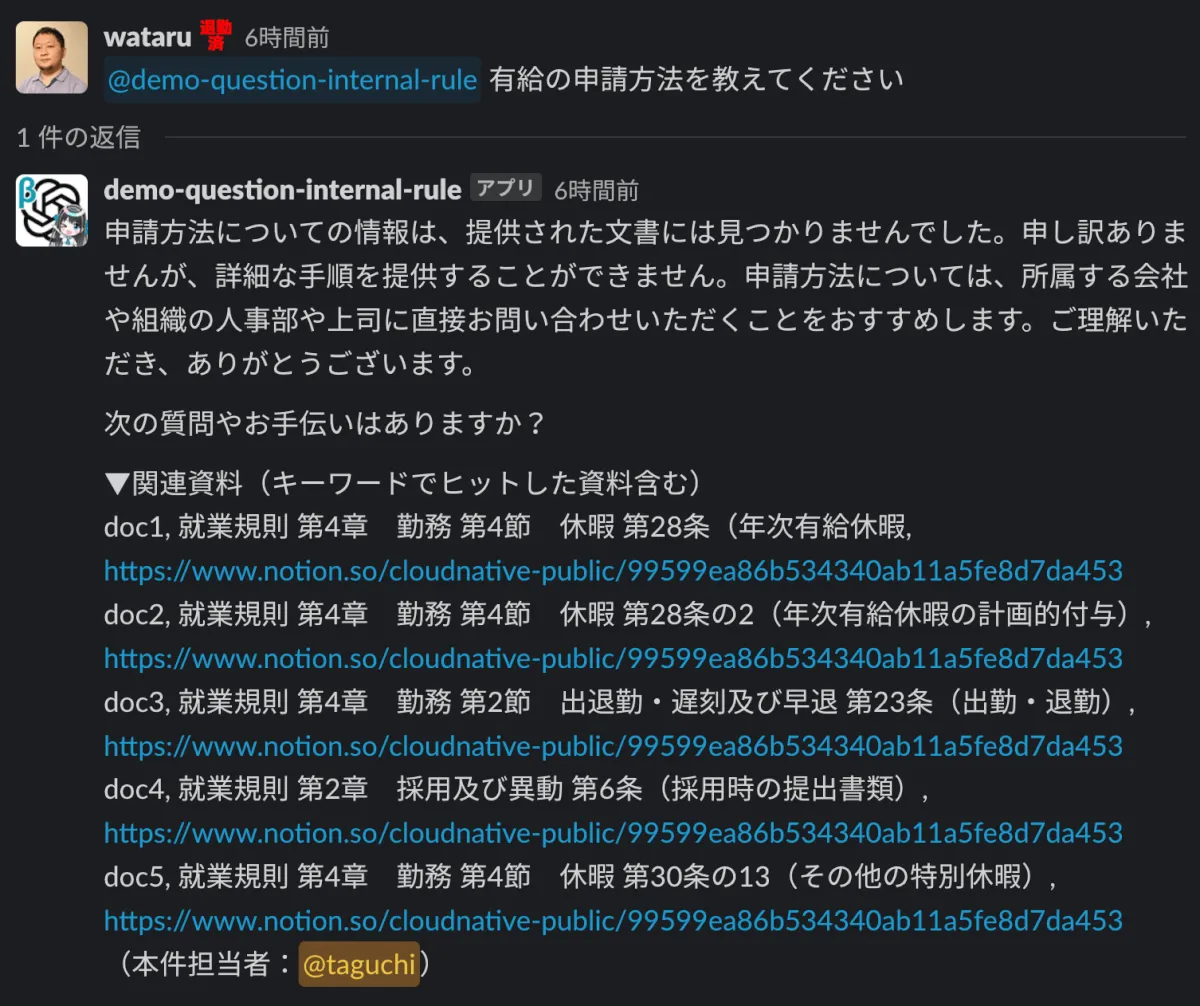
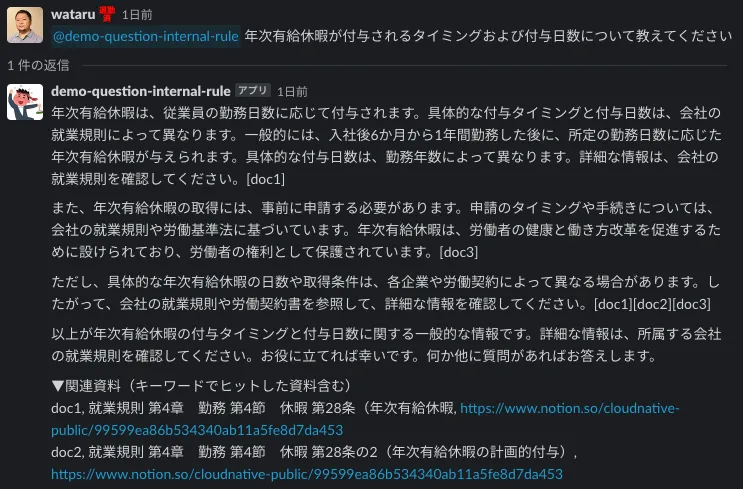
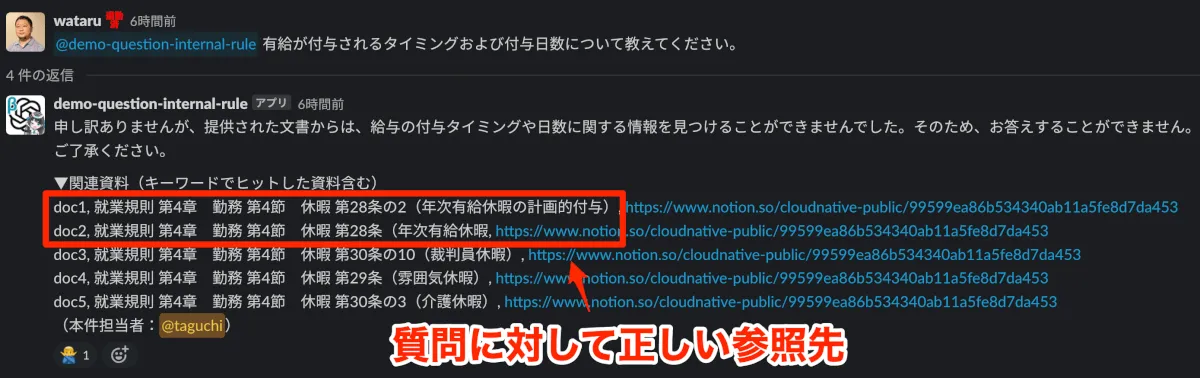
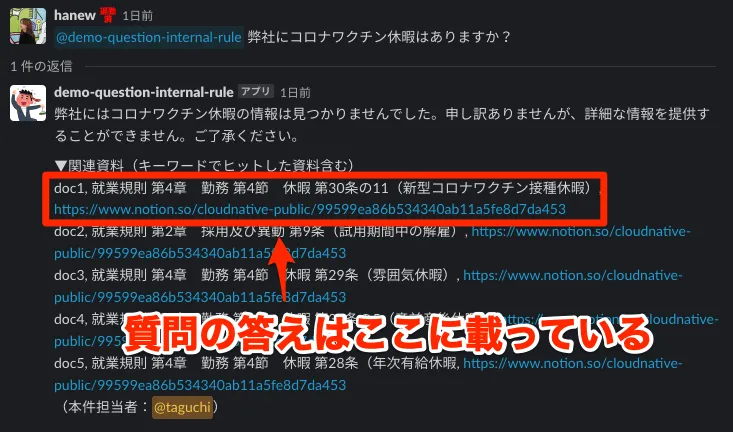
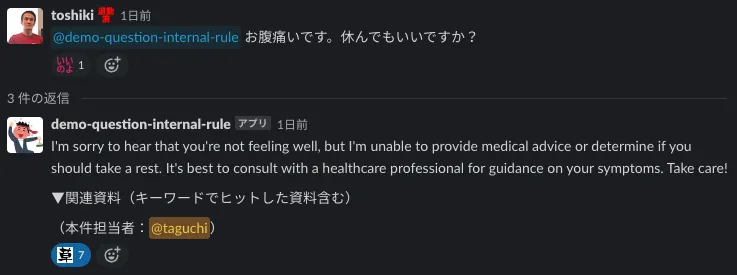
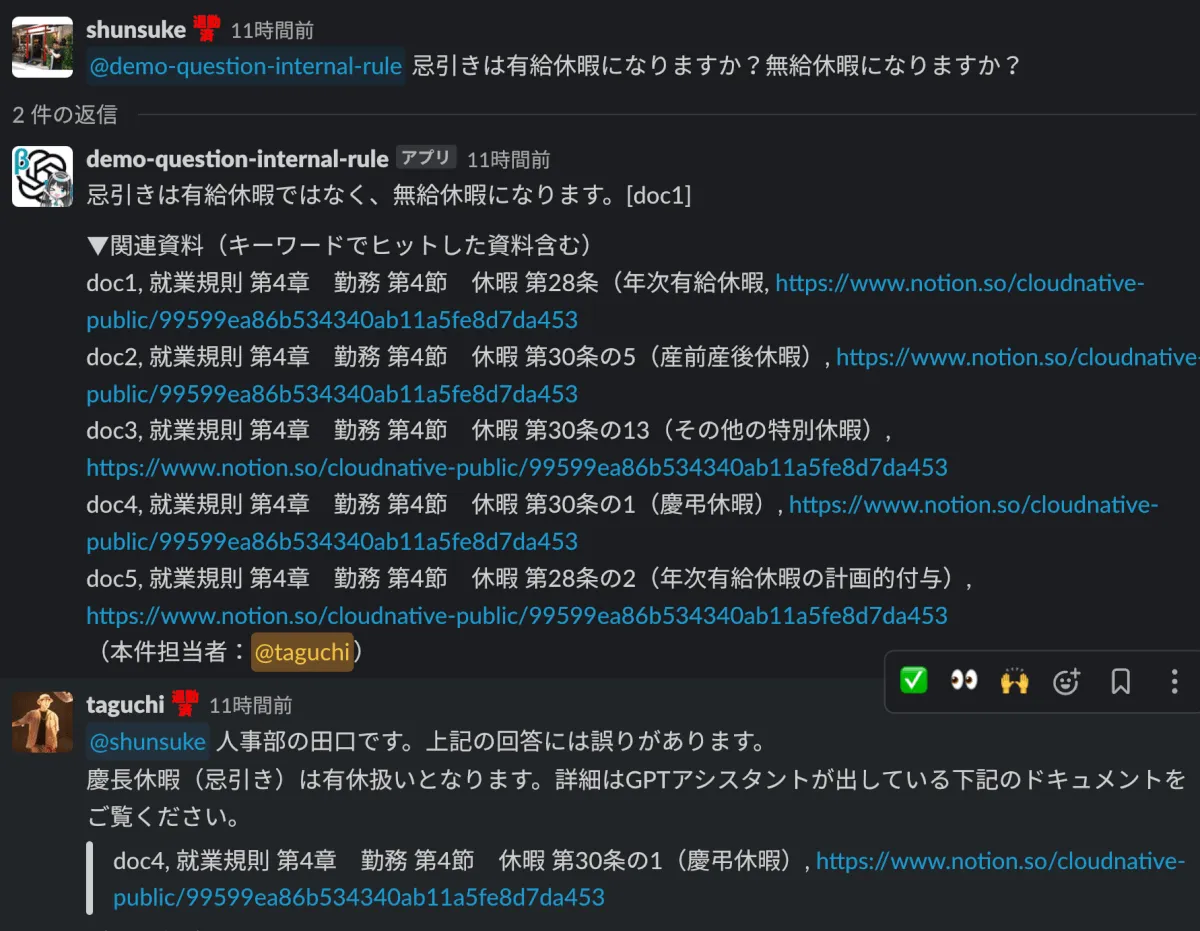
B. 正しいドキュメントを引用しているのに回答してくれない時
これは、もしかするとGPT-3.5の限界的な話かもしれませんが、正しいドキュメントを引用しているのに回答してくれない時があります。例えば以下の様なケースです。このようなケースの場合は、ユーザーは表示されたドキュメントを開けば回答に辿り着くことができます。
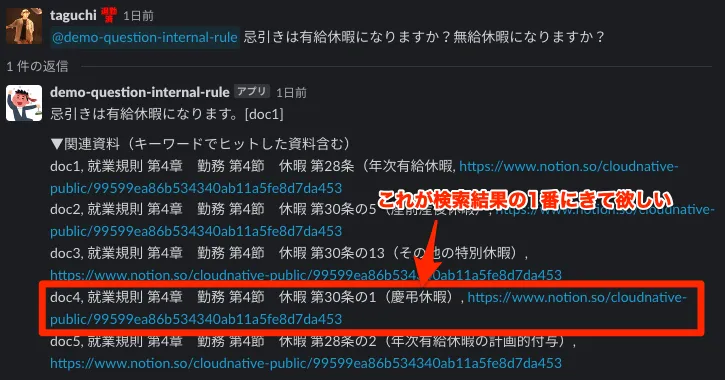
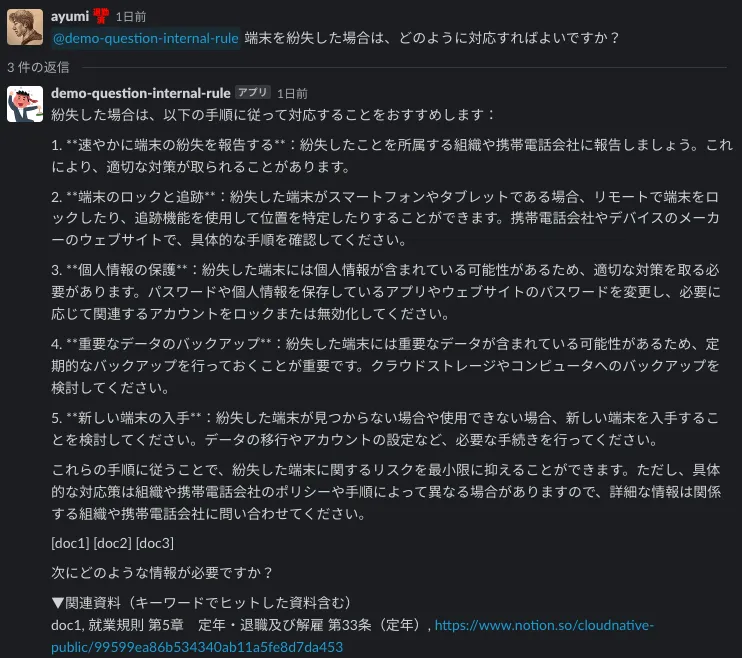
C. ドキュメントの引用の順番が惜しい時
今回5つ表示させているドキュメントは関連度順に並んでいますが、やはりキーワード検索では一番欲しかったドキュメントが上にこないケースがあります。この辺は、セマンティック検索やベクトル検索を用いて改善の余地はありそうだなと思いました。
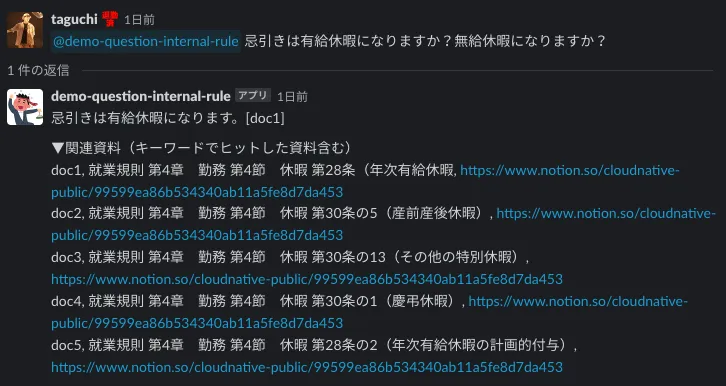
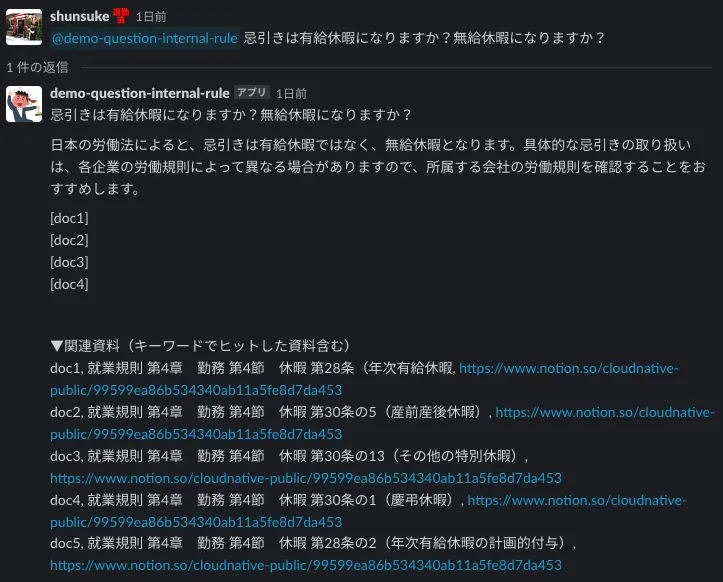
D. 同じ質問をしても違う回答の時
全く同じ文面で質問をしても、違う回答が返ってくるケースがあります。というか、厳密には語尾レベルでは毎回回答が違います。生成AIではその名の通り、毎回回答を生成しており、その過程の中で揺らぎが生じるため、同じインプットをしても同じ回答を得られるわけではありません。これは、生成AIの良い面でもあり、悪い面でもありますが、QAサービスというユースケースでは悪く作用してしまうことの方が多い様に思います。
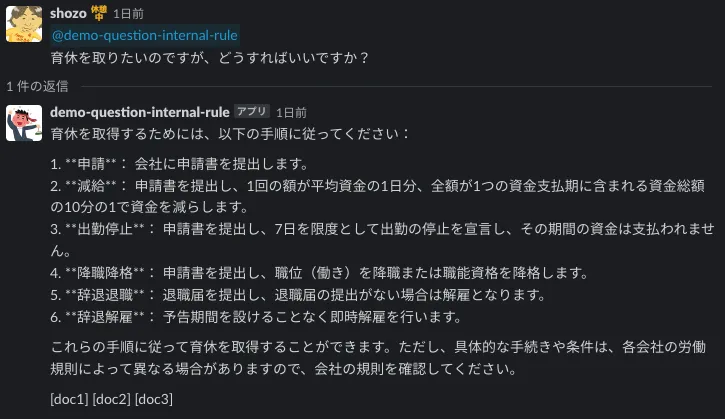
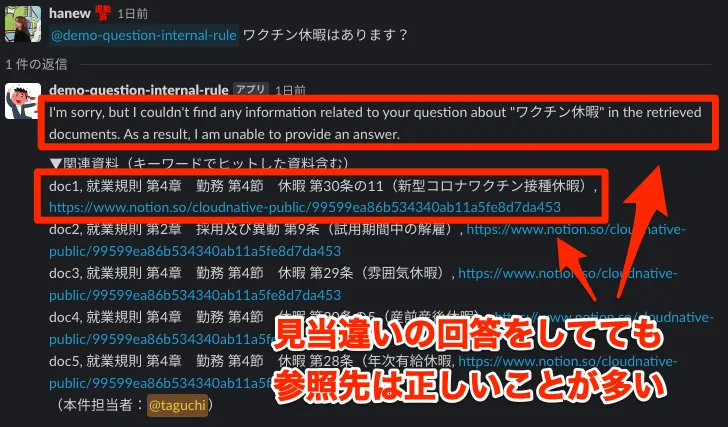
E. おかしい時・でっちあげる時
GPT-3.5レベルだと、まだまだおかしな回答をしたり、でっちあげたりすることも多いです。
簡易ボットは役にたつのか?〜活用のためのヒント〜
「一発で正確な回答を出すツール」として捉えると実用に足るものではない
今回作ったシステムを「一発で正確な回答を出すツール」として捉えると、GPT-3.5で作ったQAボットは全く実用に足るものではないと考えています。自社データを読み込ませて利用したとしても、やはり回答をでっち上げたり、惜しいけど不正確な回答を行うことは多々あります。ユーザーサポートの工数をゼロにするということが期待値で検証を始めると、痛い目を見ると思います。
「何も調べずに質問してくる問題」と「質問のしやすさの向上」のジレンマを解消
一方で、ユーザーからの問い合わせのインターフェイスをこのシステムに置き換えることで「何も調べずに質問してくる問題」を解消しつつ、「質問のしやすさ」を向上させるという、相反するように見える効果を得られる可能性があると考えました。
一般的に、なんでも質問をしやすい風通しの良い環境を作っておくと、ユーザーが疑問点を解消しやすくなり、業務が進みやすくなりますが、サポートデスクの負荷が上がります。一方で、サポートデスクの負担を減らすために「調べてから質問してこい」とハードルを上げると、ユーザーの業務が進みにくくなる可能性があります。
今回導入したシステムでは、確かに回答の精度はまちまちでした。しかし、見当違いの回答をしてても参照先は正しいことが多いため、質問してきたユーザーに参照ドキュメントをルーティングする役割を果たしてくれそうに思います。また、人間のサポート担当者はどうしても即答が難しい場合がありますが、GPTで作ったQAボットであれば、基本的に数秒で答えを返します。
人間のサポートと組み合わせアプローチだと効力を発揮
上記に加えて、やはり、人間のサポートと組み合わせアプローチだと効力を発揮しそうだと思います。QAボットが変な回答をしている場合は、人間のオペレーターが補足をすることで、従来通りのクオリティのサポートを提供することが可能となると思います。
人間のサポートは回答をゼロから作成するのではなく、QAボットの回答を補足するようになるため、ゼロから調べて回答を作るよりも工数の削減が見込めます。短期的にはこのような効果を出しつつ、長期的にはGPT-4やその先の技術を使って、回答の精度を向上させて、サポート担当の手があまりかからないようにすることを目指すと、投資対効果を出しながら未来に進んでいけるかと思います。
ユーザーが誤認しないための仕掛けは必要
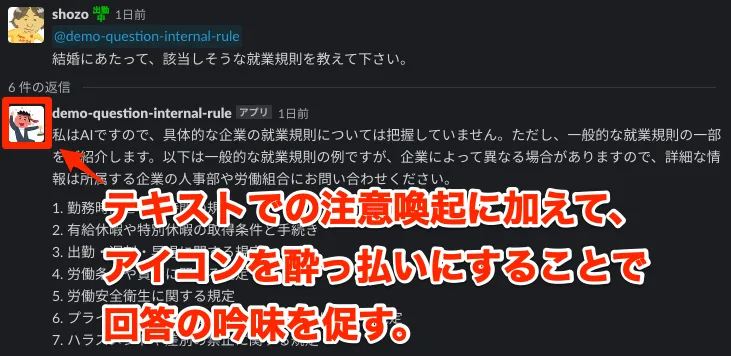
ユーザーが誤認しないための仕掛けは必要なように思えました。ChatGPTに対する理解や期待値は人それぞれです。中にはGPTは全て正しい回答をすると思っており、「GPTがXXって回答したからXXをしたんだ」という方もいらっしゃるかもしれません。このようなシステムを入れる前には、教育や注意喚起は必要になるかと思います。
その手段は沢山ありますが、1つのアイデアとして、テキストでの注意喚起に加えて、アイコンを酔っ払いにすることで回答の吟味を促すという方法があるかと思いました。酔っ払いの人から何か教えを受けても、みなさん半信半疑になりますよね…..?
おわりに(今後の展望)
今回の検証で利用したシステムは、手頃にできる手段(On your dataやキーワード検索)を縛りで実装しており、今取り得る手段の最高スペックのものを利用しているわけではありません。そのため、今後はGPT-4をはじめとするよりハイスペックなテクノロジーを用いてどの様な変化が起こったのかを取り上げていきます。マイクロソフト社をはじめとするBig Tech企業から凄まじい勢いで新技術が登場していますが、負けずに検証・実証をしていきたいと思います。
ちなみに、Azure OpenAIとSlackの連携はWorkatoを利用して実装していますが、その部分はDeveloperチームの俊介に実装してもらいました。この場を借りてお礼を申し上げたいと思います。

俊介
こんなん余裕っす!(ドヤァ)
開発中のシステム沢山あるので、どんどん出していきますね!
注釈
- Retrieval Augmented Generation (RAG) https://www.promptingguide.ai/techniques/rag