こんにちは、臼田です。
みなさん、Web上の脅威保護してますか?(挨拶
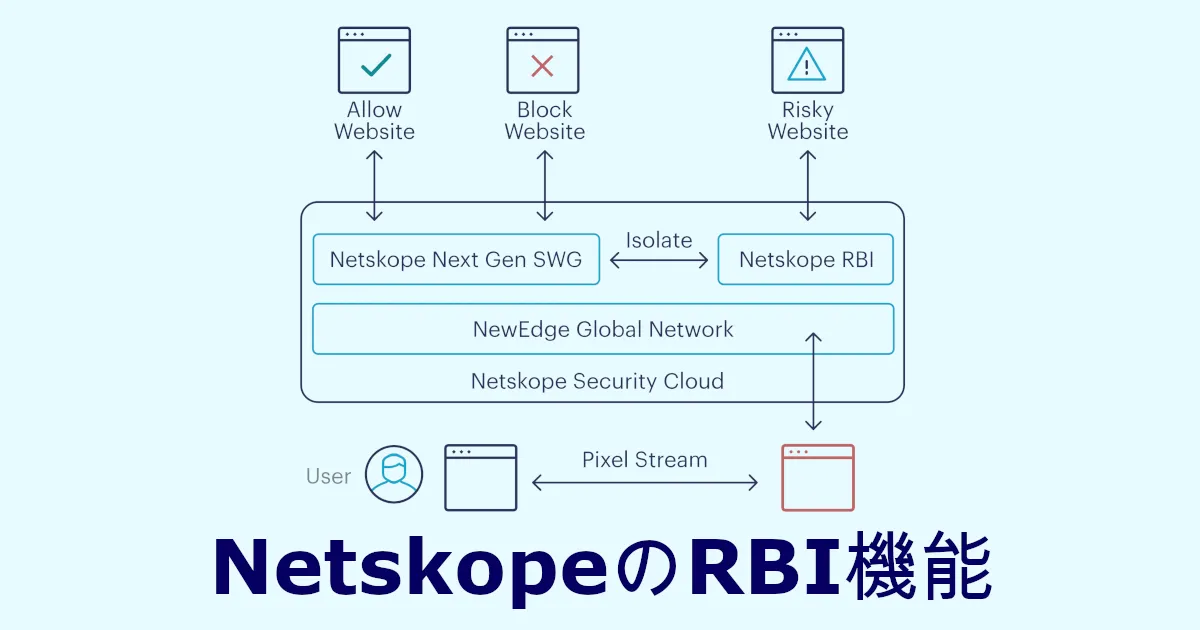
今回はNetskopeのいい感じに業務を止めずにブラウジングの脅威を分離するRemote Browser Isolation(RBI, リモートブラウザ分離)機能を使ってみたので、その方法をまとめます。
RBIとは
Netskopeには様々なエンドポイントの保護機能がありますが、RBIはユーザーがアクセスするWebサイトが危険かどうか判断に迷うような場合の保護に役立つ機能です。
通常Web上に存在する脅威から従業員の端末を保護したい場合、適切なサイトは閲覧させ、不適切なサイトはブロックするようにします。しかし実際には明確にこの2つに分類することはできず、グレーな判断となるサイトがあります。例えばNetskopeを利用している場合にはこういった不適切なサイトの分類などをユーザーが細かく日々確認する必要なく、マネージドなリストで分類を提供してくれているのでそれを利用するだけで済みますが、その中でもまだ分類されていない新しいサイトなどがあります。Netskopeのブログではそういった対象となるリクエストが約6~8%存在していると下記のように書かれています。
一般的にこうした未分類またはセキュリティリスクがあるWebサイトは、Webブラウザによるリクエスト全体の約6~8%を占めています。
<cite>次世代SWGでのリモートブラウザ分離の実装 – Netskope</cite>
従来、Web上に存在する脅威から保護する仕組みの1つとしてRBIの技術が用いられてきましたが、どうしてもリモート環境でWebのレンダリングを行ってこれを転送するという特性上、描写のパフォーマンスに問題がありユーザー体験を損ねていました。そのため、すべてのWebリクエストに対してRBIを適用するのではなく、グレーな場合にのみRBIを適用するというターゲットRBIをNetskopeでは採用しています。これを既存のNetskopeの機能であるSWG(セキュアWebゲートウェイ)と組み合わせて実現しています。
RBI対象のカテゴリ
RBI機能を利用する際には、専用の分類カテゴリが用意されていてこれがデフォルトで設定されます。現状では下記6種類が存在しています。詳細はこちらのナレッジで確認してください。
- 新規登録ドメイン
- 新たに観測されたドメイン (NOD)
- コンテンツなし
- ドメイン パーキング
- 未分類
- Web プロキシ/アノニマイザー
使ってみた
実際にRBIを設定していきます。ちなみに今回はRBIを利用できるところまでに主眼を当てているため、実践的な設定ではないことを留意してください。
大体の設定方法などはこちらのナレッジで説明がありますので参考にしてください。
前提条件
RBIを利用するにはRBIの追加ライセンスの他、SWGのライセンスも必要です。詳細な前提条件はこちらを確認してください。
RBIテンプレートの作成
RBIを適用するための最初のステップはRBIテンプレートの作成です。RBIテンプレートはRBI自体の設定をまとめたものです。Netskopeの画面で「Policies -> Templates」の配下に設定画面があるため、ここから「NEW TEMPLATE」を押して作成開始します。(テナントにライセンスが適用されていないとページが出てきません)
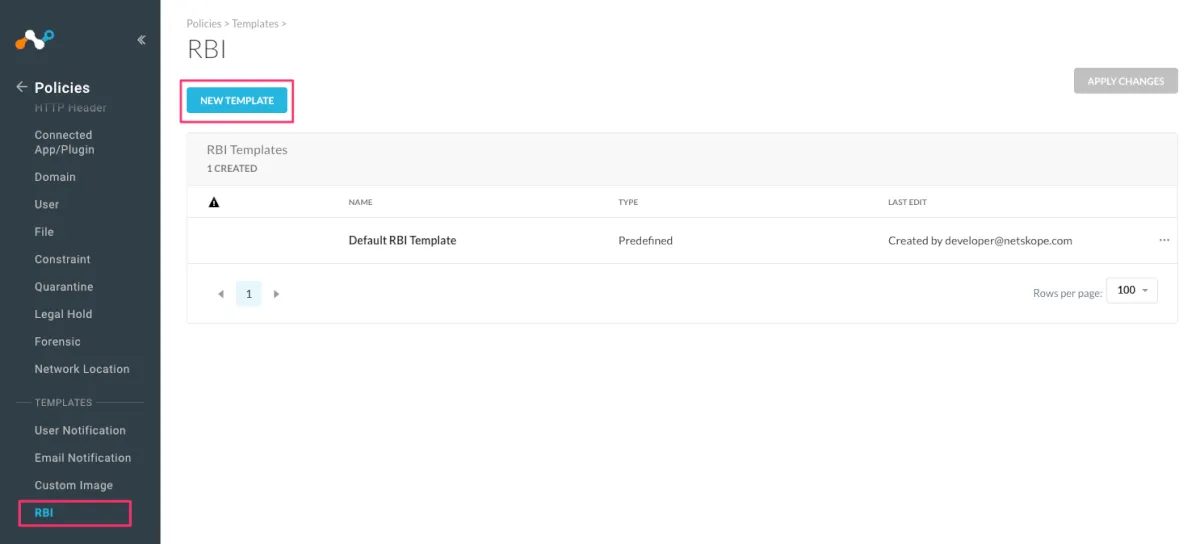
今回は分離されていることをタブにアスタリスクをつけて表現する設定のみを入れて作成します。ちなみにこの設定では入力の許可やコピー・ペーストの許可も可能です。
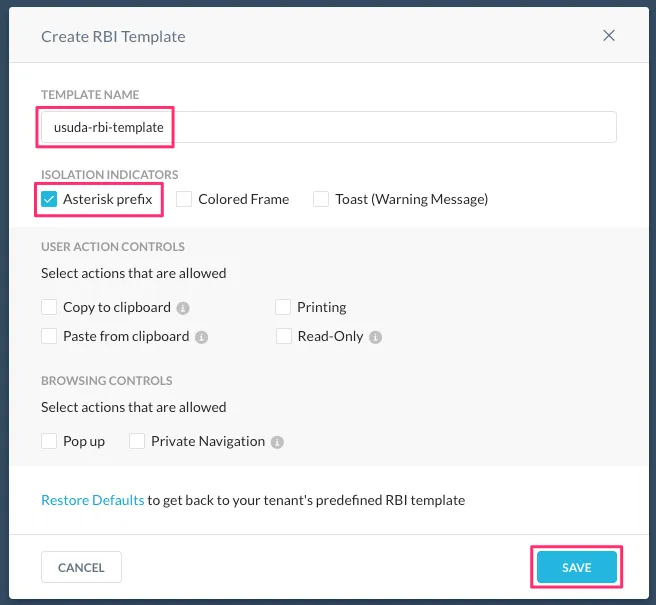
作成後、ApplyしたらRBIテンプレートの作成は完了です。
対象リストの追加
今回は分離する対象のドメインリストを自分で追加してみます。具体的にはgoogle.comを分離の対象としてみます。通常であればNetskopeが用意している分類を用いることが多いと思うのでここは実施する必要はありません。
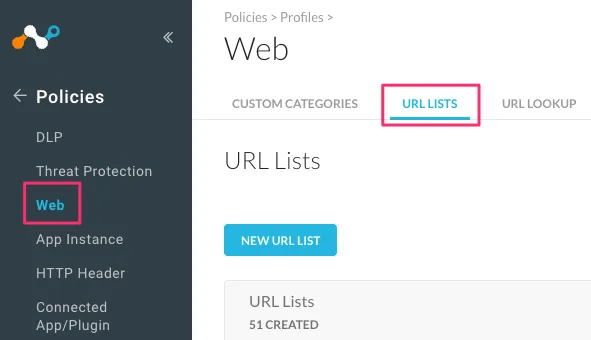
まずは「Policies -> Profiles -> Web」の「URL LISTS」にアクセスして「NEW URL LIST」から追加します。
対象として*.google.comを入力して保存します。ちなみにURL TYPEにはExactとRegexがありますが、デフォルトのExactのままでもこの表記で問題なく利用できました。
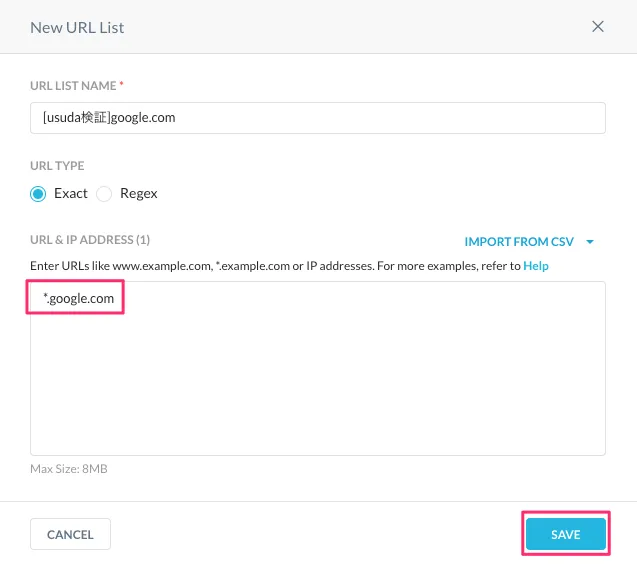
続いてこのリストを含むカスタムカテゴリを作成します。
同じく「Policies -> Profiles -> Web」の「CUSTOM CATEGORIES」にアクセスして「NEW CUSTOM CATEGORIES」から追加します。
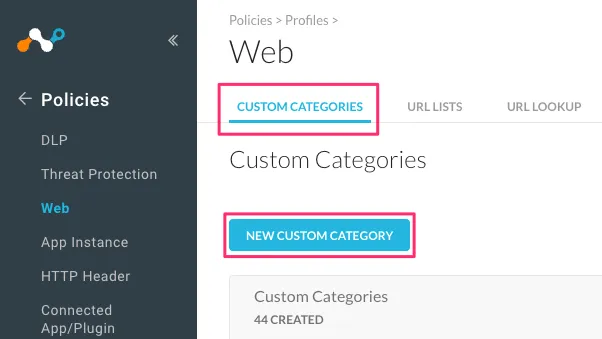
URL List(Include)に先ほど作成したURL LISTを追加します。
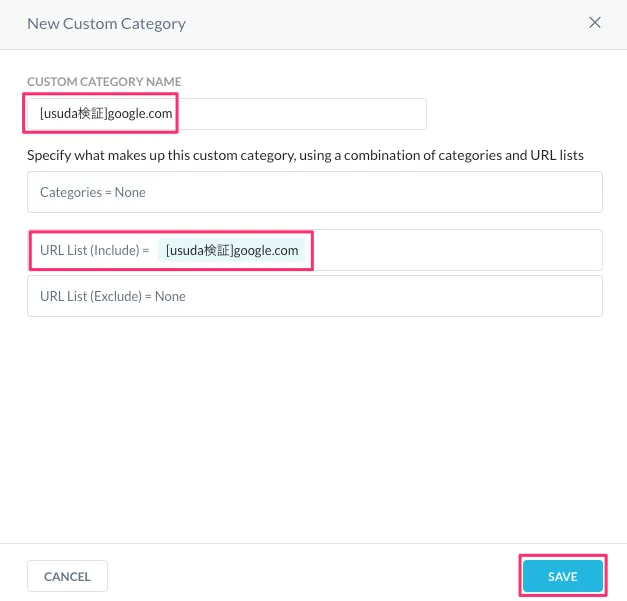
これで対象リストの追加完了です。
Real-time Protectionの設定
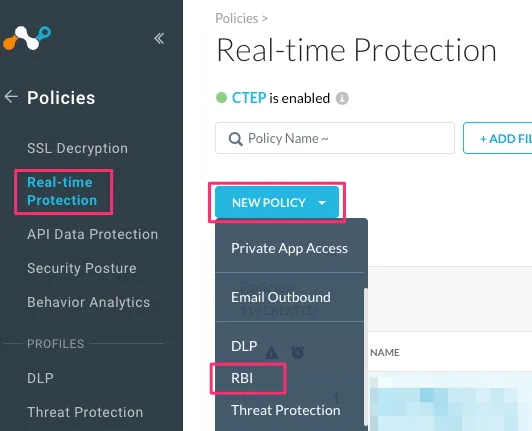
RBIを適用するためにはReal-time ProtectionでRBIのポリシーを作成する必要があります。
「Policies -> Real-time Protection」から「NEW POLICY」の下の方にある「RBI」を選択します。
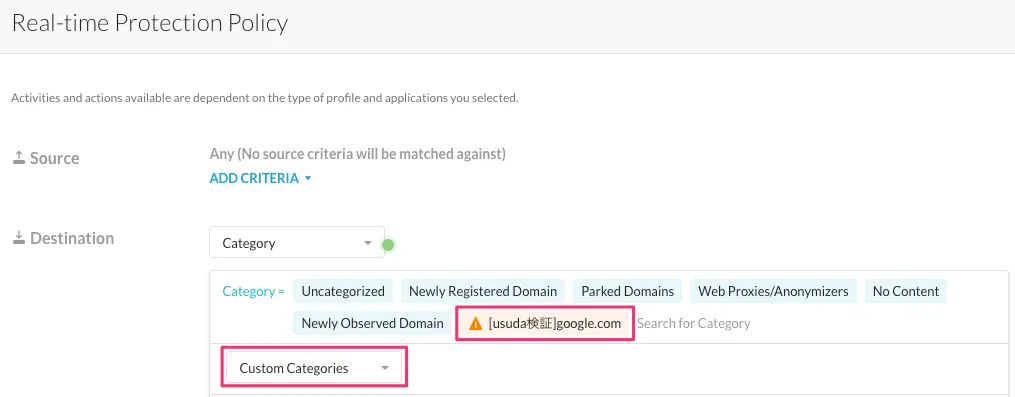
DestinationではデフォルトでCategoryに6つのRBI用カテゴリが設定されています。今回は任意で追加したgoogleのドメインも追加したいので、先ほど作成したカテゴリを「Custome Categories」から追加します。ちなみにこのカテゴリはおそらく対象が広いせいで、パフォーマンスに影響が出ると警告が表示されました。が、無視して進めます。
検証目的であればSourceで適用対象も絞っておきましょう。
Profile & Actionで先ほど作成したRBI Templateを設定します。適当な名前を入れて保存しましょう。
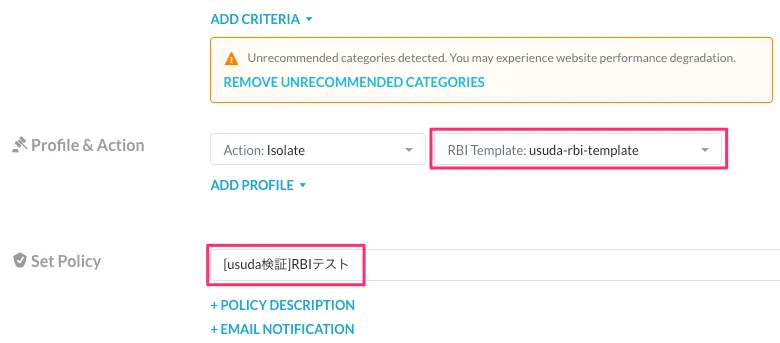
保存したらApplyして適用します。これでRBIの設定が完了しました。
動作確認
実際にRBIが動作することを確認します。
まずクライアント側でNetskopeクライアントのConfigurationを開き、Config Updatedの時刻から設定が反映されていることを確認します。
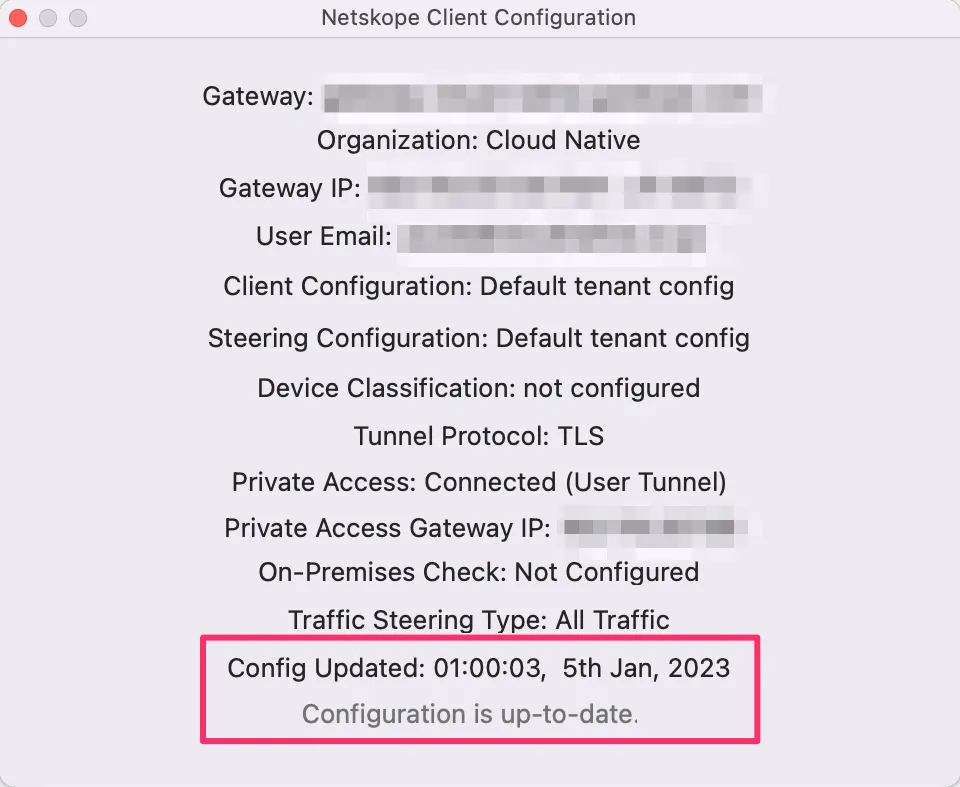
ブラウザを開いてgoogleへアクセスしてみます。すると一瞬タブがRemote Browser Isolationの表示になり、画面上でもNetskopeのロゴが動きます。
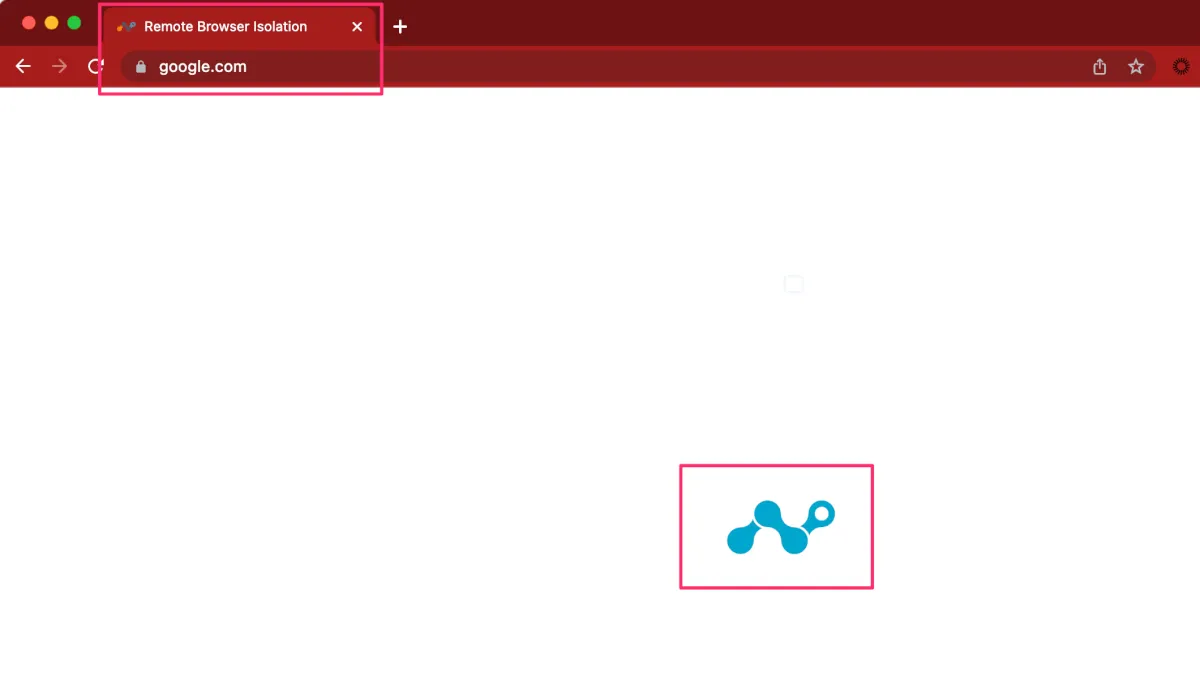
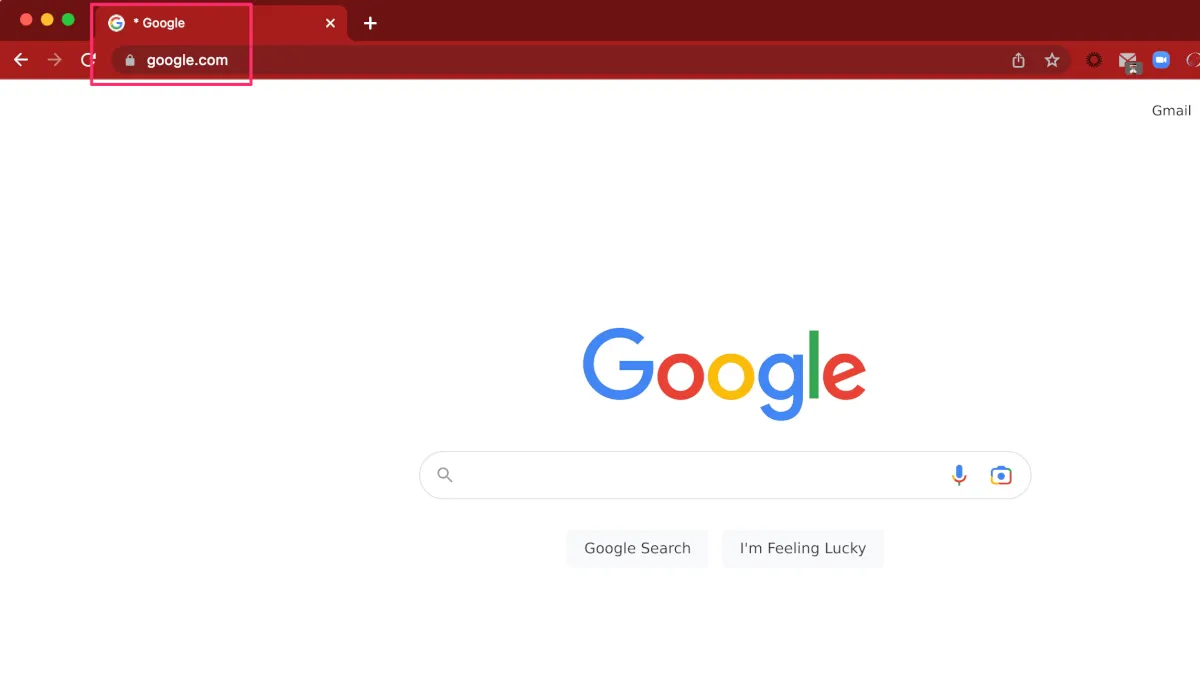
その後、Googleの画面が開きましたが、タブには分離されていることを示す*が表示されています。RBIが動作していることを確認できました。
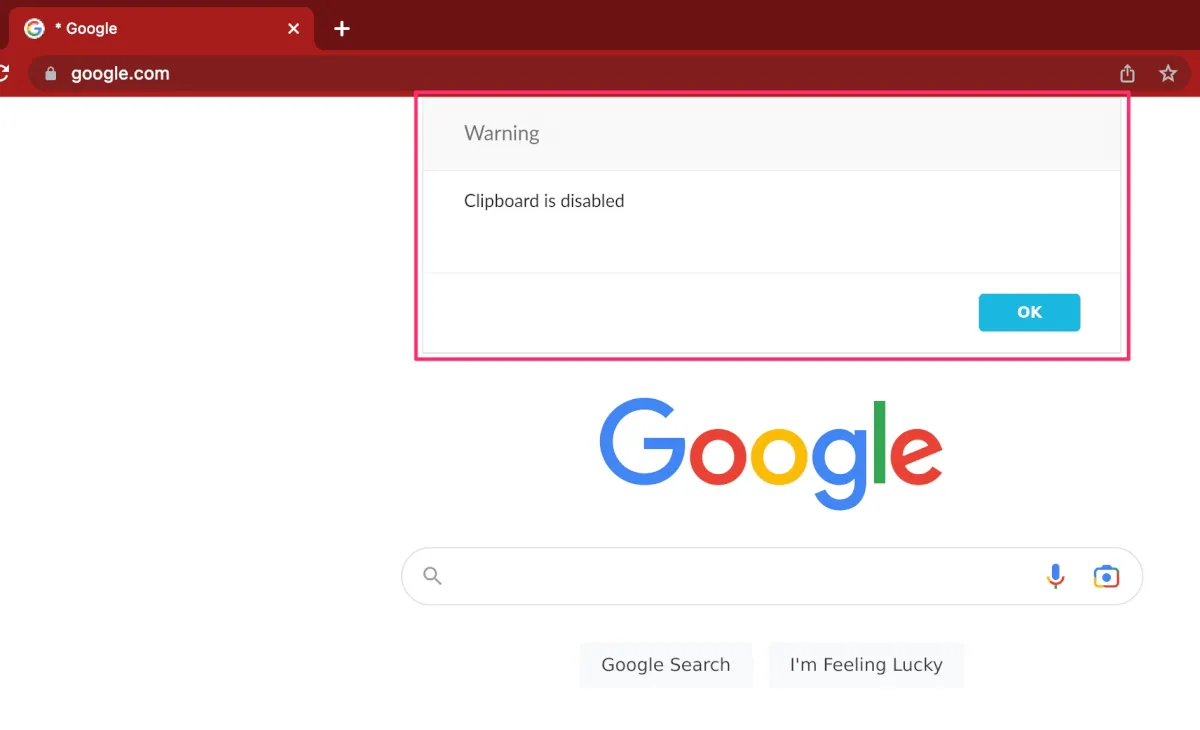
今回の設定ではコピー・ペーストを許可していないため、貼り付けしようとしたら下記のようにポップアップが表示されてブロックされました。
まとめ
NetskopeのRBI機能を使ってみました。従業員のデバイスを保護するためにURLベースのWebアクセス制御をすることはあると思いますが、グレーな場合のみ分離するターゲットRBIは、業務を止めることなくかつパフォーマンスを損なわず非常にちょうどいい解決策の1つだと思います。
ぜひ使ってみてください。