どうも おかしん です。Anthropicが2026年5月27日に「Zero Trust for AI agents」を公開しました。
今日は、自分的には久々にゼロトラストの話しよっかなーと思います。自認ゼロトラスト警察の私は、ゼロトラスト関連の記事とか発表を見るとついついしっかり読み込んでしまいます。
さて、「Zero Trust for AI agents」のタイトルだけ見ると、また「AIエージェントにもゼロトラストを適用しましょう」、というだけの話に見えます。しかし中身を読むと、かなり実務寄りです。AIエージェントを、IDを持ち、権限を使い、ツールを呼び、メモリを保持し、時には他のエージェントへ処理を委譲する新しい業務主体として扱っています。
これは「AIを使わせるか、禁止するか」という話ではありません。人間、端末、SaaS、サービスアカウント、APIキーに適用してきたゼロトラストを、AIエージェントという新しい主体にどう広げるか、という話です。
ゼロトラストを製品導入ではなく、業務とリスクに合わせた設計原則として捉える考え方は、ITセキュリティ・ゼロトラスト概論(技術評論社。以下、ゼロトラスト概論)でも整理されています。本稿ではその延長として、AIエージェントを新しい業務主体として見たときに、どこを検証し、どこで止め、何を記録すべきかを考えます。
生成AIを「生産性が上がるかどうか」だけで見ると、こうした主体管理の論点が落ちます。弊社ブログの「生成AIで生産性は上がりません。その根拠を説明します」でも整理されているように、個人の作業短縮と組織成果は分けて考える必要があります。
弊社ブログではこれまで、AIエージェントのゼロトラスト、NHI(Non-Human Identity)、SaaS AIの評価、フロンティアAIによる脅威高速化、NSA ZIGを個別に扱ってきました。この記事ではそれらの前提を踏まえつつ、私の整理として、Anthropicの文書からAIエージェント時代のゼロトラストを読み直してみます。
この記事でわかること
- Anthropicの「Zero Trust for AI agents」が何を問題にしているか
- PDF本文のFoundation / Enterprise / Advancedをどう実務に読み替えるか
- AIエージェントをNHIとして扱い、Least Agencyまで落とすべき理由
- MCP、ツール、メモリ、サプライチェーンで増える攻撃面
- AIが脆弱性発見速度を上げたとき、パッチ運用とSOC運用で詰まるポイント
- AI以前のセキュリティ基盤が弱い組織が、どの順序で確認すべきか
AIエージェントのゼロトラストとは、AIエージェントを人間や端末と同じように、IDを持つ業務主体として台帳に載せ、権限を絞り、ログを残し、高リスク操作に人間の判断を残すことです。特別なAIセキュリティ製品を買う話ではなく、既存のゼロトラストの管理対象を1つ増やす話です。以下、Anthropicの文書に沿って、これを具体化していきます。
Anthropicの記事の要約
Anthropicの問題意識は明確です。フロンティアAIは、脆弱性の発見から悪用までの時間を、数か月から数時間へと圧縮します。守る側もAIで速くなりますが、攻める側も同じように速くなります。さらに、守る側がパッチを出した後に、その差分から攻撃コードを作る速度も上がります。
情報セキュリティでは、時間はリスク評価そのものです。解読に10万年かかるなら無視できるリスクでも、3日で現実化するなら無視できません。フロンティアAIが変えるのは、攻撃や防御の能力だけではなく、この時間感覚です。
この速度変化は、AIエージェントを導入する企業にとって二重の問題です。
1つ目は、AIエージェントが動くインフラ自体もAIで高速化された攻撃にさらされることです。2つ目は、AIエージェントが単なるチャット画面ではなく、目標を解釈し、ツールを選び、複数ステップの操作を実行することです。
従来のアクセス制御は「このユーザーはこのAPIを呼べるか」を見ます。しかしAIエージェントでは、それだけでは足りません。正規の権限を持ったエージェントが、外部入力や汚染されたツール情報に誘導され、許可された操作の範囲内で誤ったことをする可能性があるからです。
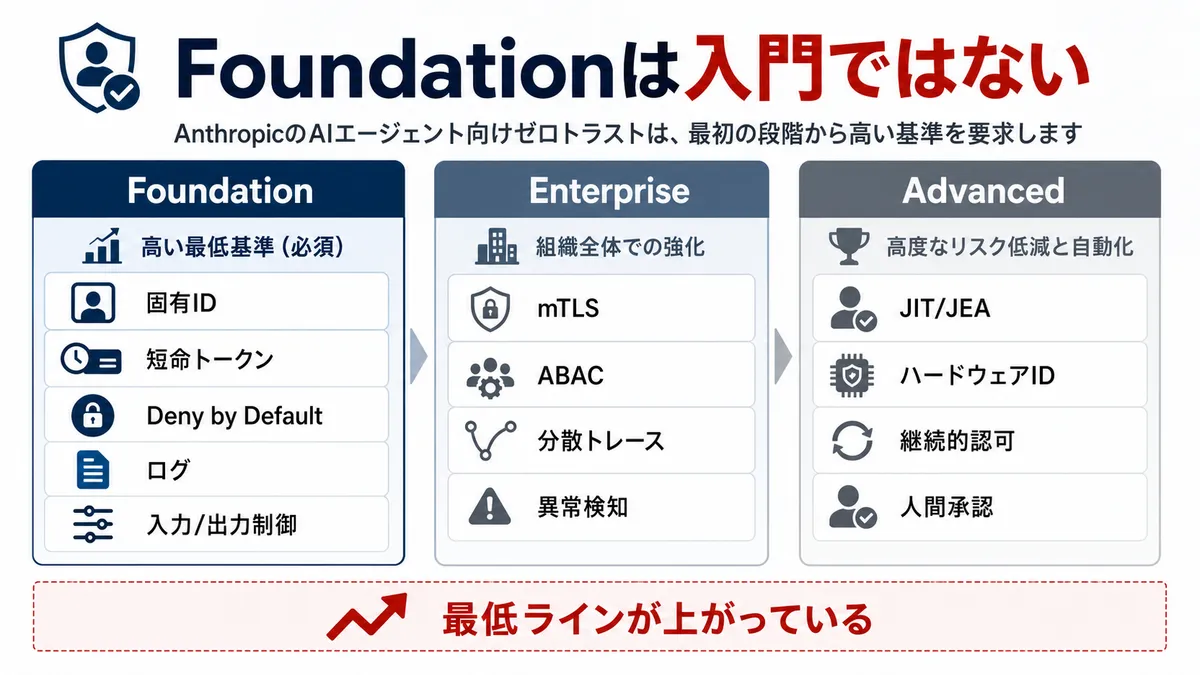
Anthropicのブログ記事は2026年5月27日公開です。その短い紹介部分では、3段階のゼロトラストフレームワークをFoundation / Advanced / Optimizedとして説明しています。一方、PDF本文の実装表ではFoundation / Enterprise / Advancedとして制御が整理されています。両者の名称が食い違っているのはAnthropic側の表記揺れで、PDF本文に「Optimized」という階層は登場しません。本稿では、制御項目が展開されているPDF本文に合わせて、Foundation / Enterprise / Advancedと呼びます。
重要なのは階層名ではありません。Foundationの最低ラインがかなり高く設定されていることです。
Foundationには、エージェントインスタンスごとの暗号学的に検証可能な固有ID、短命トークン、Deny by Default、エージェント単位の隔離、包括的なログ、request ID、自動一次トリアージ、入力検証、出力フィルタリングなどが含まれます。
つまりAnthropicの文書では、短命トークンやエージェントごとの固有IDは「成熟した会社がそのうちやること」ではありません。入口の話です。従来、短命トークンなどは基本的なエンティティ(IDやデバイス)管理をしっかりできた後にやっていく、どちらかというと第二段階目標に近い事柄だったはずです。今までの企業におけるサイバーセキュリティの常識からすれば、かなり高度な要求です。
PDF本文もこれを明言しています。AIによる攻撃の高速化を理由に「Foundationの床は引き上げられた。摩擦を生むだけの制御はもはやFoundationには数えない」とし、さらに「時間が経てばAdvancedがEnterpriseの標準になり、EnterpriseがFoundationになる」とまで書いています。最低限の実装水準は、今後も上がり続ける前提で読むべき文書です。このPDFは単に「AIエージェントにもゼロトラストを適用しよう」という抽象論ではありません。
私が特に重要だと思ったのは、次の5点です。たとえば、社内ナレッジを読んでSlackへ投稿するエージェントを想像すると分かりやすいです。読む、要約する、投稿する、記録する、止める、のすべてが設計対象になります。
1つ目は、Foundationが単なる入門ではないことです。静的APIキーや共有サービスアカウントはもはやFoundationとして弱い扱いで、短命トークン、暗号学的に検証可能な固有ID、Deny by Default、エージェント単位の隔離が入口に置かれています。
2つ目は、Least PrivilegeだけでなくLeast Agencyが必要になることです。AIエージェントの危険は、広い権限だけでなく、広い裁量にもあります。どのツールで、どの頻度で、どこまで自律実行できるかまで絞ります。
3つ目は、MCP、ツール、モデル、依存ライブラリ、メモリまで含めてサプライチェーンとして扱っていることです。AI-BOMやOpenSSF Scorecardまで話が広がります。詳細は後述の攻撃面の節で扱います。
4つ目は、観測すべき対象が「何をしたか」だけではないことです。どの入力からどの判断に至ったのかを追える、トレースと説明可能性の話です。
5つ目は、防御側もAIを使う前提で、dwell time(異常発生から人間が気づくまでの時間)とcoverage(調査対象になったアラートの割合)を測れと言っていることです。詳細は後述のAgentic SOARの節で扱います。
AIエージェントのゼロトラストは、AI利用ルールではなく主体管理の話
多くの会社では、AIガバナンスが「入力してはいけない情報」「利用してよいAIサービス」「生成物の確認ルール」から始まります。もちろんそれは必要です。
ただしAIエージェントでは、論点が変わります。
AIエージェントは、利用者の代わりにSaaSへアクセスし、チケットを更新し、コードを生成し、プルリクエストを作り、メールやSlackに投稿し、データを読みに行きます。APIキー、OAuthトークン、サービスアカウント、MCPサーバー、RAG、メモリを組み合わせて動きます。
この時点で、AIエージェントは人間の補助UIではありません。業務システム上の主体です。
したがって見るべきものは、チャットログだけではありません。
- agent_id
- owner
- allowed_tools
- credential
- approval_policy
- memory_scope
- data_access_scope
- output_destination
- audit_log
- kill_switch
このあたりが管理対象になります。
管理プレーンを操作できるエージェントは特権主体
特に注意したいのは、AIエージェントが管理プレーンに触る場合です。ここでいう管理プレーンは、IdP、MDM、SaaS管理画面、CI/CD、バックアップ、AI管理基盤のように、権限変更、端末操作、ポリシー変更、ログ確認、復旧操作を行える制御面です。
AIエージェントがこれらを操作できるなら、それは通常の業務ユーザーより強い特権主体です。便利な自動化として見るだけでは足りません。PIM/JIT、フィッシング耐性MFA、複数管理者承認、操作ログ、変更通知、バックアップ復旧手順まで含めて設計する必要があります。
AIエージェントの制御面は、Anthropic文書の用語をそのまま並べるだけでなく、弊社ブログのAIエージェントにゼロトラストを適用するでも扱った4層に引き寄せると整理しやすいです。ここは当社クラウドネイティブとして考える実装整理です。
| 層 | 見ること |
|---|---|
| Agent OS | エージェントの目的、許可された行動、禁止された行動、ポリシー |
| AgentMesh | エージェント、MCP、外部ツール、SaaS APIをつなぐIDと通信経路 |
| Agent Runtime | 実行環境、tool call、メモリ、権限、停止、隔離 |
| Agent SRE | 監査証跡、誤実行時の復旧、障害対応、継続的改善 |
これは、特定ベンダー製品を購入しようという話ではありません。AIエージェントを業務に入れるなら、どの層で検証し、どの層で止め、どの層で復旧するかを決める必要がある、という話です。
「誰が使ったか」だけでは足りません。「どのエージェントが、どの権限で、どのツールを、どの入力に基づいて、何の判断で、どこへ出力したか」まで追えないと、統制としては不完全です。
AIエージェントはNHIを爆発させる
NHI、つまりNon-Human Identityは、人間ではない主体のIDです。サービスアカウント、APIキー、OAuthアプリ、CI/CDのトークン、Bot、RPAなどが該当します。
AIエージェントは、このNHIを一気に増やします。
Claude Code、GitHub Copilot、Cursor、SaaS内蔵AI、RPA、社内Bot、MCPサーバー、社内ナレッジ検索エージェント。これらはそれぞれ、どこかで認証情報を使います。人間のブラウザ操作を少し便利にするだけならまだしも、外部SaaSへの書き込み、ファイル操作、デプロイ、権限変更、顧客通知まで扱うなら、NHIとして棚卸ししないと危険です。
ここでありがちな問題は、共有サービスアカウントと静的APIキーです。
「静的APIキーは全部即日禁止」と言うだけでは現実的ではありません。既存システムやSaaS連携の都合で、すぐには変えられないものもあります。ただしAnthropicのFoundation基準で読むなら、長寿命で広い権限を持つAPIキーは、少なくとも既知のギャップとして扱うべきです。
つまり「今は残っているが、リスクを認識し、所有者、用途、権限、保管場所、ローテーション、失効手順を台帳化している」という状態にする必要があります。できるところから、短命トークン、スコープ分割、エージェントごとの固有ID、証明書ベースの認証へ移行する。これがAIエージェント時代のNHI管理です。
ゼロトラストは製品名ではなく設計原則である
ゼロトラストは、NIST SP 800-207でも整理されているように、製品名ではありません。「導入しました」と言える箱ではなく、何を信頼せず、どのアクセス要求をどの文脈で検証し、何を拒否し、何を記録するかを決め続ける設計原則です。実装時には、アクセスごと、操作ごとの検証、拒否、記録の運用仕様へ落とします。
AnthropicのPDFも同じ書き方をしています。PDF本文は、エージェントのIDと認証、アクセス制御と権限管理、可観測性と監査、行動監視と対応、入力検証と出力制御、完全性と復旧、AIガバナンスという7つのカテゴリごとに、Foundation / Enterprise / Advancedの3階層で制御を実装表に整理しています。
Foundationでは、暗号学的に検証可能な固有ID、短命トークン、RBAC、Deny by Default、エージェント単位の隔離、ログ、入力検証、出力フィルタリングが入ります。
Enterpriseでは、mTLS、ABAC、動的権限、サンドボックス、改ざん困難な監査証跡、分散トレーシング、ベースライン学習、統計的な異常検知、自動封じ込めの準備が入ります。
Advancedでは、ハードウェアにバインドされたcredential、ハードウェアバックドIDとattestation、継続的認可、JIT/JEA、confidential computing、リアルタイムSIEM相関、provenance chain、文脈を見た行動分析、人間承認を組み込んだ高リスク操作の制御が入ります。
ここで大事なのは「何のベンダーを入れるか」ではありません。AIエージェントが侵害された、誘導された、誤作動した、過剰な権限を使った。そのときに、被害をどこで止められるかです。
攻撃を「面倒にする」だけの対策はAI時代に弱くなる
Anthropic文書で特に良いと思ったのは、対策を「impossible」と「tedious」で分けているところです。
tediousは、日本語にすると「退屈な」「単調で骨が折れる」「うんざりするほど面倒な」という意味です。難しくて不可能、というより、時間と根気があればできるが、人間にとっては面倒で嫌になる、というニュアンスです。
AnthropicのPDFでは、制御を評価するときに「その攻撃を成立しなくしているのか、それとも単に面倒にしているだけなのか」を問え、という設計テストとして出てきます。ここでいうimpossibleは、全ての攻撃を完全に消すという意味ではなく、特定の攻撃経路を設計上成立しにくくする、という意味で読むべきです。
PDFがtedious側の例として挙げているのは、追加のpivot hop、レート制限、非標準ポート、SMSベースのMFAのような「摩擦」に依存する対策です。これらは攻撃者の手間を増やしますが、硬い境界ではありません。AI支援攻撃では、面倒な反復作業のコストが下がります。人間がやるにはだるい作業を、AIは粘り強く回せます。Anthropicは、agentic attackersにはほぼ無制限の忍耐と、ほぼゼロに近い試行コストがある、という前提で見ています。
つまり、tediousな対策は「無意味」ではありません。時間を稼ぐ、雑な攻撃を減らす、検知までの猶予を作る、という価値はあります。ただし、それを中核の防御として数えてはいけない。PDFでも、AIにより攻撃速度が上がった結果、Foundationの床は上がり、摩擦だけの制御はFoundationに入らないと整理されています。
一方で、短命トークン、FIDO2、ハードウェアバインド、署名検証、存在しないネットワーク経路、Deny by Default、権限の未付与は、特定の攻撃経路そのものを狭めます。もちろん、それで全ての攻撃が消えるわけではありません。だから複数の境界を重ね、残るリスクをログ、検知、復旧で見る必要があります。
AIエージェントの統制でも同じです。
「危ない操作の前に警告を出す」だけでは弱いです。エージェントがそもそもそのツールを呼べない。呼べても特定のスコープしか扱えない。高リスク操作は人間承認なしに実行できない。外部送信先はallowlist以外に出せない。メモリには保持期間と検証がある。ここまで落とす必要があります。
これは厳しすぎる話ではありません。AIエージェントが実行主体になるなら、これが普通の業務設計になります。
AIエージェント特有の攻撃面
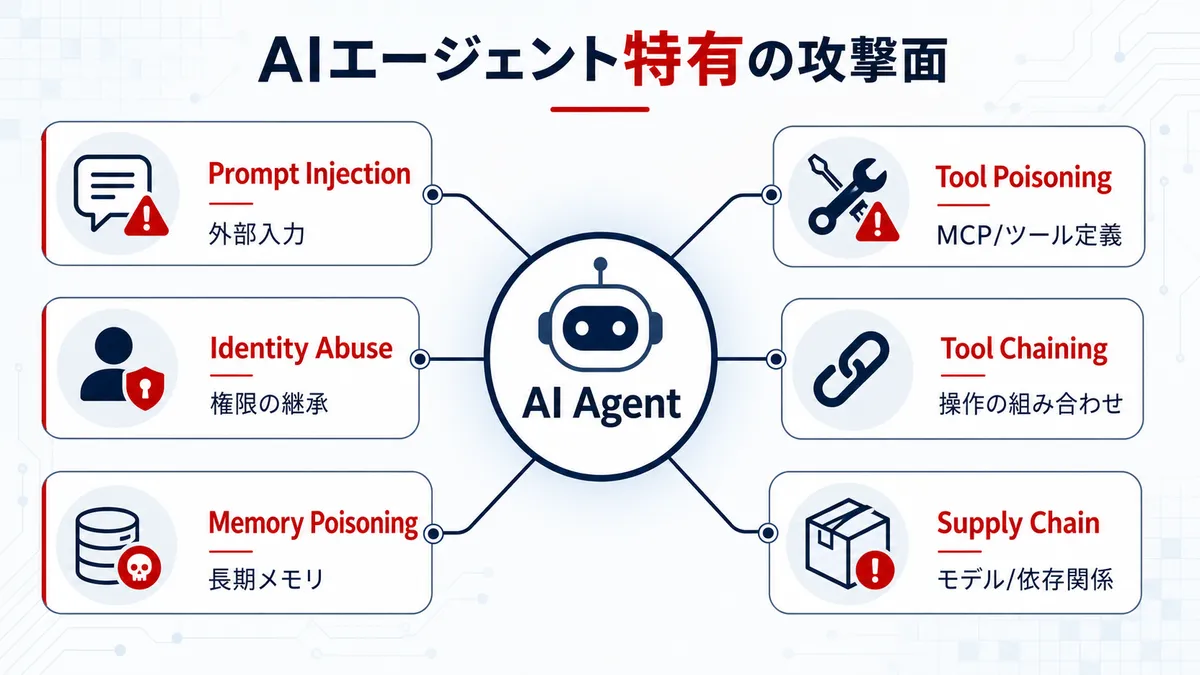
AIエージェントのセキュリティを考えるとき、プロンプトインジェクションだけに寄せると見誤ります。OWASP Top 10 for Agentic Applicationsでは、エージェント固有の攻撃面がツール、ID、メモリ、通信経路まで広がっていることが整理されており、Anthropic PDFの脅威分類もこのOWASPの整理を参照して書かれています。もちろんプロンプトインジェクションは重要ですが、それは入口の1つです。
Prompt Injection
外部のWebページ、メール、PDF、チケット、チャット、RAGデータに含まれる文章が、エージェントへの命令として解釈される問題です。人間にとってはただの文章でも、エージェントにとっては操作指示に見える場合があります。
PDFでは、直接入力による攻撃だけでなく、外部データに埋め込まれた間接的な攻撃を重く見ています。ユーザー本人は悪意ある命令を見ていないのに、エージェントがWebページやメールや文書からそれを読み、正規の依頼として実行してしまうからです。
対策は、入力を命令として扱わない境界設計、信頼できない入力のラベル付け、ツール実行前のポリシー判定、出力先の制限です。形式チェックや長さ制限だけでは足りません。非信頼入力を明示的に区切る、既知の攻撃パターンを弾く、外部コンテンツを別コンテキストで処理する、といった多層の対策が必要になります。
Tool Poisoning
MCPサーバー、プラグイン、ツール定義、schema、descriptor、metadataが汚染される問題です。エージェントはツールの説明を読んで、どのツールを使うか判断します。ツール説明そのものが攻撃面になります。
PDFでは、正規のツールが後から悪意あるものへ差し替えられるrug pullや、MCPサーバーが正規サービスを装ってメールなどを盗むケースにも触れています。ここは実務上かなり重要です。エージェントにとってツール説明はUIであり、API仕様であり、判断材料でもあります。人間が見落としたmetadataの一文が、エージェントには命令として効く可能性があります。
したがって、MCPサーバーやツールは「便利そうだから追加」ではなく、署名、出所、更新履歴、要求権限、通信先、ログ、停止手順を確認してから入れる必要があります。可能なら自社でホストし、検証したコードをimmutableな環境に載せます。そのうえで、manifest、schema、metadataの差分レビュー、egress制御、実行権限の制限、更新承認、ロールバック手順まで運用に入れるのが現実的です。
Tool Chaining
1つ1つのツール呼び出しは正規でも、組み合わせるとデータ漏えいや意図しない更新につながる問題です。
例えば、社内ドキュメントを読むツール、要約するツール、外部に投稿するツールが別々に許可されているとします。単体では問題なく見えても、組み合わせると機密情報を外へ送れるかもしれません。
このため、ツール単体のallowlistだけでなく、データ分類、出力先、操作順序、高リスク操作の承認を合わせて見る必要があります。
もう1つ見落としやすいのがresource exhaustionです。エージェントはループできます。人間なら途中で面倒になって止めるAPI呼び出しや検索や再試行を、延々と続けられます。DoSや請求増につながるため、レート制限だけでなく、支出上限、実行回数、異常な反復の検知、回路遮断まで考える必要があります。
Identity and Privilege Abuse
ここはNHI管理と直結します。AIエージェントは、サービスアカウント、OAuthトークン、MCPサーバー、APIキーを使って動くため、権限の継承や委譲の失敗がそのまま事故になります。
PDFでは、上位エージェントがworker agentへ過大な権限を渡してしまうunscoped privilege inheritance、低権限エージェントが高権限エージェントを動かすconfused deputy、過去セッションのcredentialや安全な文脈がメモリ経由で持ち越されるmemory-based privilege retentionが挙げられています。これは「IDを発行したか」だけでは防げません。誰の意図で、どの権限を、どの時間だけ、どの操作に使えるのかまで切る必要があります。
Memory Poisoning
エージェントのメモリやRAGに悪意ある情報が残り、将来の判断に影響する問題です。
チャット1回の攻撃なら、そのセッションを閉じれば終わるかもしれません。しかしメモリに残る場合、攻撃は将来に持ち越されます。保持する情報、保持期間、更新権限、削除方法、信頼度、出典を管理しないといけません。
PDFでは、メモリに認証情報や過去の安全な文脈が残り、別セッションから引き出されるリスクも扱っています。これは単なる情報漏えいではなく、権限の持ち越しです。前の安全なセッションで得た秘密や判断材料を、後の攻撃者が利用できるなら、セッション境界は破れていると考えるべきです。
Agent間通信
複数のエージェントが連携する場合、低権限のエージェントが高権限のエージェントを動かす経路ができます。これは古典的なconfused deputy問題に近いです。
人間の世界では「この依頼は誰から来たか」「承認者は誰か」を見ます。エージェント間通信でも、送信元ID、権限、目的、リクエストID、承認状態を見ないといけません。
Supply Chain and Dependency Risks
PDFでかなり紙幅が割かれているのが、このサプライチェーンの論点です。
AIエージェントのサプライチェーンは、従来のアプリケーションより動的です。モデル、fine-tuningデータ、RAGデータ、MCPサーバー、プラグイン、ツール、依存ライブラリ、agent personaが実行時に組み合わさります。静的なSBOMだけでは足りず、AI-BOMやモデル由来、学習データ、ツール提供元、更新経路まで見る必要があります。
たとえば、依存ライブラリの脆弱性だけでなく、悪意あるAIモデル、汚染されたfine-tuningデータ、RAGへの汚染データ投入、MCPサーバーのなりすましが攻撃面になります。エージェントは外部ツールを「読んで」判断するので、コードとして実行されるものだけでなく、説明文やschemaも攻撃対象です。
実務では、少なくとも次を確認したいです。
- 利用しているLLMモデル、MCPサーバー、プラグイン、主要ライブラリを台帳化しているか
- 提供元、更新者、署名、リリース履歴、脆弱性対応の履歴を見ているか
- OpenSSF Scorecardなどで依存関係の健全性を見ているか
- 複数のHTTPクライアントやJSONパーサーなど、重複依存を減らせるか
- 脆弱性が見つかったとき、実際に到達可能なコードかを見て修正優先度を決められるか
- 小さく未保守の依存を、標準ライブラリや保守済み依存へ寄せられないか
- どうしても外す場合、使っている範囲だけを限定実装し、レビューとテスト対象にできるか
これは開発チームだけの仕事ではありません。情シスやセキュリティ担当が、AIエージェントの導入審査で見る項目になります。
Agentic SOARは何を自動化し、何を自動化しないべきか
Anthropic文書は、Agentic SOARにも触れています。ここは誤読しやすいところです。
大事なのは、人間を外してAIに防御判断を全部任せることではありません。PDFで自動化すべきとされているのは、証拠収集、ログの相関、一次トリアージ、ドキュメント作成です。
一方で、封じ込めの判断、外部開示、顧客通知は、人間の判断を残すべきとされています。私はここに、影響範囲の仮説出し(自動化する側)と、法務判断・規制当局対応(人間に残す側)も加えて運用するのが現実的だと考えています。
AIで攻撃が速くなるなら、防御側も人間がログを1つずつ開く前提では間に合いません。だから一次調査は自動化する。しかし、止める判断まで自動化しすぎると、別の事故になります。
実務的には、まず1つのアラート種別だけで試すのが良いと思います。たとえば「AIエージェントが通常使わないSaaS APIを呼んだ」「高リスクツール呼び出しが連続した」「外部送信と社内データ参照が短時間に連続した」などです。
このとき、AIにやらせることは次の範囲にします。
- 関連ログを集める
- agent_id、user_id、tool_call、request_idを束ねる
- 直近の設定変更を確認する
- 類似アラートを探す
- 影響範囲の候補を出す
- 人間が判断するための要約を作る
これだけでも、初動はかなり速くなります。
さらにPDFでは、Agentic SOARを単なる一次トリアージで終わらせていません。MITRE ATT&CKに対して検知coverageを対応づけ、Atomic Red Teamのような小さな検証で「今のログで実際に見えるか」を確認し、5件同時インシデントを想定した机上演習を行い、緊急変更手順を事前に決めるところまで踏み込んでいます。AIで発見件数が増えるなら、SOCも脆弱性管理も、1件ずつ丁寧に回す前提を見直す必要があります。
PDFで良いのは、防御AIにも同じゼロトラストを要求しているところです。防御用エージェントだから信頼してよい、とはなりません。SIEMを読み、セッションを止め、認証情報を失効し、ネットワーク隔離を提案または実行できるエージェントは、攻撃者から見れば非常に価値の高い権限主体です。
したがって、Agentic SOARを入れるなら、防御エージェントにも同じゼロトラスト原則を適用します。PDFが明示するのは、最小権限、実行範囲の制限、明確な承認・エスカレーション経路、ログとトレースによる監査です。実行基盤としては、本編で見てきた固有IDと短命トークンの仕組みの上に乗せます。高影響の封じ込めは人間承認を残し、低影響で高確度な作業から自動化する。最初から全アラートを任せるのではなく、誤検知が多いが影響範囲を読みやすいルールを1つ選び、人間レビューとの一致率を見て広げるのが現実的です。
Project Glasswingが示す、次のボトルネック
冒頭で述べた「速度」の論点は、Anthropicが2026年4月7日に発表したProject Glasswingと、2026年5月22日の初期アップデートを見ると、より具体的になります。
Project Glasswingは、Claude Mythos Previewを使って重要ソフトウェアの脆弱性を防御側が先に見つけ、修正するための取り組みです。発表ページには、AWS、Apple、Google、Microsoftなど、Anthropic自身を含む12のローンチパートナーが列挙されており、加えて重要ソフトウェアを構築・維持する40超の追加組織へアクセスを広げています。Claude Mythos PreviewとProject Glasswingの全体像、参加企業、ビッグテック依存の論点は、弊社ブログのClaude Mythos 完全考察にもまとめています。
初期アップデートでは、参加パートナーの多くが各社で数百件のhigh/criticalな脆弱性を見つけ、全体では1万件超に達したことが示されています。Anthropic自身も1,000超のOSSプロジェクトをスキャンし、23,019件のうち6,202件をhigh/critical推定として扱っています。
ここで重要なのは件数の大きさだけではありません。進捗の制約が「見つける速度」から「検証、開示、修正」に移った、という整理です。AIが大量に見つけた脆弱性を、どれだけ速く検証し、開示し、パッチにできるか。さらにその先には、利用者側がパッチを展開しきれるかという問題も残ります。昨日まで「もう少し先でよい」と見ていた対応が、いきなり現在の課題になる。AI時代のパッチ運用は、この時間圧縮を前提にしないといけません。
これは企業のパッチ運用にもそのまま効きます。AIによって発見と再現が速くなるほど、月次の脆弱性管理会議、手動の影響調査、属人的な例外承認、ロールバック手順なしの緊急適用では追いつきません。必要になるのは、資産台帳、依存関係台帳、重要度に応じた緊急変更ルート、パッチ検証の自動化、未適用資産の追跡、そして「今すぐ当てられないもの」を仮想パッチ、設定変更、一時隔離、認証情報失効、監視強化、バックアップ復旧で守る設計です。
つまりProject Glasswingは、AIエージェントのゼロトラストから少し外れた話に見えて、実は同じ方向を向いています。侵害前提で被害を限定するだけでなく、脆弱性が大量に見つかる前提で運用を詰まらせないこと。ここまで含めて、AI時代のゼロトラストだと考えた方がよいです。
PDFの8フェーズ実装ワークフローを読み替える
PDFの後半は、かなり実装寄りです。AnthropicはAIエージェント導入を8つのフェーズで整理しています。私なりに、日本企業の情シス・セキュリティ担当が使える形に読み替えると、次のようになります。
Phase 1: 要件を決める
最初に決めるのは、使うAIやツールではありません。規制要件、業務目的、制約、関係者です。セキュリティ、法務、コンプライアンス、業務部門が、何のためにエージェントを使い、何をさせないかを合わせます。どこまでのリスクを許容するかは、Foundation / Enterprise / Advancedのどの階層を目指すかの判断にも直結します。
ここが曖昧なまま始めると、「便利そうだからMCPを足す」「現場が勝手にSaaS AIを使う」「後からログが足りないと気づく」という流れになります。シャドーAIの問題も、ここで扱うべきです。
SaaS内蔵AIを使う場合は、本文データだけでなく、メタデータ、ログ、モデル改善利用、保持期間、削除、オプトアウト可否も確認します。プランやテナント、トライアル状態によって設定可否が変わることもあるため、「AI機能を使うか」だけでなく「どのデータ利用を止められ、どれは止められないか」まで要件に入れるべきです。
最近ではAtlassianが、既存顧客のデータを全ての顧客向けのAI学習に使う発表を行ったりしています。

Phase 2: サプライチェーンを見る
AI-BOM、モデル由来、MCPサーバー、プラグイン、依存ライブラリ、ベンダーの脆弱性対応を見ます。特にMCPは、通常のAPI連携より一段慎重に扱うべきです。エージェントの判断材料になる説明文、schema、metadataまで含めて信頼境界になるからです。
この段階では、次のような問いを置くと進めやすいです。
- そのMCPサーバーは誰が作り、誰が更新しているのか
- 署名、リリース履歴、脆弱性対応、通信先、egress先を確認したか
- 自社でホストできるか
- manifest、schema、metadataの変更差分をレビューできるか
- 更新時に検証、承認、ロールバックができるか
- モデルやRAGデータの出所を説明できるか
- ベンダーやFOSS提供元は、AIで短縮されるexploit timelineにどう備えているか
- FOSSなら、コード、メンテナンス状況、コミュニティ、OpenSSF Scorecardなどを直接評価したか
Phase 3: エージェント境界を定義する
ここは本文全体の中心です。エージェントごとに、許可する操作、禁止する操作、人間承認が必要な操作、アクセスできるデータ、外部送信先、失敗時のblast radiusを定義します。
「顧客対応を支援する」では粗すぎます。「顧客レコードを読む」「要約を作る」「返信案を下書きする」は許可するが、「送信する」「削除する」「返金する」「権限を変更する」は人間承認にする、くらいまで落とす必要があります。
また、1つの万能エージェントに全部やらせるより、機能ごとにエージェントを分けた方が安全な場合があります。ただし、分けた全エージェントに同じ認証情報を渡したら意味がありません。固有IDと固有credentialが前提です。
Phase 4: プロンプトインジェクションに備える
直接入力だけでなく、Web、メール、PDF、チケット、RAGから来る間接入力を非信頼として扱います。外部コンテンツをシステム命令と混ぜないこと、信頼できない入力を区切ること、既知の攻撃パターンや符号化されたpayloadを弾くことが必要です。
PDFでは、入力分離に加えて、MicrosoftのSpotlightingのように非信頼コンテンツを明確に区切る手法(間接インジェクションの成功率を50%超から2%未満に低減)や、Anthropicのconstitutional classifiersのように入出力を別のAI分類器で監視する手法(テストでジェイルブレイク試行の95%をブロック)、攻撃対象面そのものの縮小も挙げています。ここは「プロンプトをうまく書く」話ではなく、外部データを命令として扱わせないための境界設計です。
ただし、入力フィルタだけで守れると思わない方がよいです。入力がすり抜けても、ツール実行、出力先、外部送信、権限変更で止める設計にします。
Phase 5: ツールアクセスを守る
Tool allowlistは、エージェント側だけでなく、エージェントの外側でも enforcement する必要があります。エージェントが壊れても、ツール側が短命トークンや証明書で呼び出し元を検証し、許可されていない操作を拒否する状態が望ましいです。
また、ツール呼び出しのparameter validationも重要です。正規ツールでも、想定外の引数で呼ばれれば事故になります。PDFは、想定範囲を超える引数や不審な内容を実行前に拒否し、検証をエージェント側とツール側の両方で行うべきとしています。実務に落とすなら、送信先、クエリ範囲、ファイルパス、削除対象、件数、金額、実行回数あたりが検証対象になります。
Phase 6: 認証情報を守る
静的APIキー、共有サービスアカウント、設定ファイルに埋め込まれたsecretは、AI支援攻撃ではすぐ見つかる前提で扱います。Foundationの基準は、短命でスコープされたトークンです。Enterpriseでは証明書ベース、AdvancedではハードウェアにバインドされたcredentialやJIT/JEAが見えてきます。
現実には、一気に全部を変えるのは難しいです。だからこそ、静的キーを「例外」ではなく「既知ギャップ」として台帳化します。所有者、用途、権限、保管場所、ローテーション、失効手順、移行予定を残す。これがない静的キーは、管理されていないリスクです。
Phase 7: メモリを守る
AIエージェントのメモリは、便利機能ではなく永続化された判断材料です。セッション分離、ユーザー分離、保存内容の出典、hash、改ざん検知、保持期間、削除手順が必要になります。
特にRAGや長期メモリでは、「いつ、どこから、どの条件で追加された情報か」を追えないと、毒入りの文脈を取り除けません。疑わしいメモリを隔離し、既知の正常状態へ戻せるよう、versioned memoryやrollbackの考え方を入れるべきです。
Phase 8: 測るものを決める
最後に、何を測るかです。PDFではdwell timeとcoverageを最初に測れ、という整理が出てきます。これは実務的です。
dwell timeは、異常が発生してから人間が気づくまでの時間です。coverageは、発生したアラートのうち実際に調査できた割合です。PDFでは、critical systemでは1時間以内の検知を目標にする考え方も出ています。AIで初動調査を自動化するなら、まずこの2つが改善しているかを見るべきです。
加えて、説明可能性も重要です。あるエージェントの操作について、どの入力がきっかけで、どのツールを選び、どのデータを読み、誰が承認し、どこへ出力したかを説明できるか。金融、医療、公共、個人情報を扱う領域では、ここが監査対応そのものになります。
もう1つ見るべきなのが、behavioral conformanceとdriftです。通常時のtool usage、出力傾向、判断分布をベースライン化し、少しずつ違うツールを選ぶ、出力の性質が変わる、メモリ汚染やサプライチェーン由来のゆっくりした逸脱が起きる、といった変化を検知します。単発のアラートだけでは、こうしたずれは拾いにくいです。
日本企業がまず確認すべき順序
ここで読者としては疑問が残るはずです。
そもそもAI云々の以前に、人間のID管理、端末管理、SaaS管理、ログ、脆弱性管理が弱い組織が、AIエージェントのゼロトラストだけを先にやる意味はあるのでしょうか。
私の答えは、AIだけを優先しても意味は薄いです。
AIエージェントのゼロトラストは、従来の情報セキュリティやゼロトラストの土台の上に乗るものです。人間のアカウントが共有され、MFAが弱く、端末状態が見えず、SaaSの外部共有やOAuthアプリが未管理で、ログも見ていないなら、AIエージェントだけを綺麗に管理しても全体の穴は塞がりません。
ただし、これはAIを後回しにしてよいという意味でもありません。AIエージェントやSaaS AIは、既存の弱点を増幅します。共有APIキー、広すぎるOAuthスコープ、野良SaaS、管理外データ、ログ不足がある状態でAIにツール実行を渡すと、それらの弱点が一気に使える経路になります。
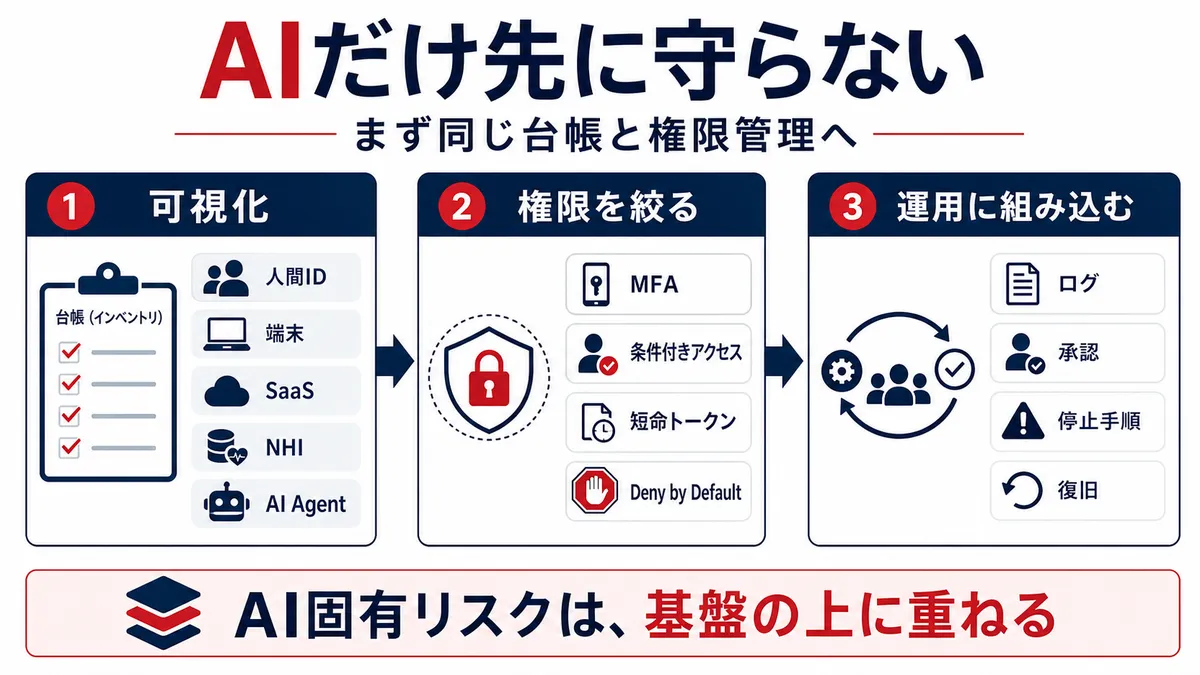
なので優先順位は、「AI専用の高度な対策を先に買う」ではありません。ゼロトラストを実務へ落とす考え方に沿って、人間、端末、SaaS、NHI、AIエージェントを同じ管理面で棚卸しし、まず被害範囲を決めることです。AIエージェントは別枠の未来技術ではなく、既存のID、権限、データ、ログの未成熟を映す鏡として扱うべきです。
最初に、AI以前の基盤とAI/NHIを同じ台帳に載せる
- IdP、MDM、主要SaaS、管理者アカウント、共有アカウント、外部共有、OAuthアプリを一覧化する
- 重要SaaSと重要データのownerを決める
- 人間アカウントのMFA、管理者権限、退職者/異動者の棚卸し状態を確認する
- Claude Code、GitHub Copilot、Cursor、SaaS内蔵AI、RPA、Bot、MCPサーバーを一覧化する
- 各AIエージェントのownerを決める
- 各AIエージェントが使うAPIキー、OAuth接続、サービスアカウントを台帳化する
- 利用しているMCPサーバー、プラグイン、主要ライブラリ、RAGデータソースを台帳化する
- SaaS内蔵AIの本文データ、メタデータ、モデル改善利用、ログ保持、オプトアウト可否を確認する
- 静的APIキー、共有認証情報、長寿命トークンを既知ギャップとして分類する
- 読み取り、書き込み、削除、外部送信、権限変更、支払い、顧客通知を高リスク操作として分類する
- 各エージェントのblast radiusを文章で説明できるようにする
この段階の目的は、禁止ではなく可視化です。AIだけを見るのではなく、AIが使う人間ID、SaaS、NHI、データ、ログのつながりを見る必要があります。見えていないものは守れません。
次に、人間とNHIの権限を絞る
- 主要SaaSと管理者アカウントにMFA、条件付きアクセス、PIM/JITを適用する
- 常時管理者、共有アカウント、退職者/異動者アカウント、不要なOAuthアプリを減らす
- 共有サービスアカウントをやめ、可能な範囲でエージェントごとの固有IDに分ける
- 静的APIキーを短命トークンへ移行する計画を作る
- Tool allowlistを作り、Deny by Defaultに寄せる
- ツール引数のparameter validationを、エージェント側とツール側の両方に入れる
- 外部送信、削除、権限変更などの高リスク操作には人間承認を入れる
- 管理プレーン操作にはPIM/JIT、複数管理者承認、変更通知、復旧手順を組み合わせる
- ログにagent_id、request_id、tool_call、input_source、output_destination、approvalを残す
- 設定ファイル、MCP allowlist、権限設定をversion controlとレビュー対象にする
この段階では「何でもできる人間」「何でもできるNHI」「何でもできるエージェント」を同時に減らします。AIの性能より先に、失敗したときの被害範囲を決めるべきです。
そのうえで、AI固有のメモリ、MCP、一次トリアージに入る
- Memory、RAG、外部入力の保持期間と削除手順を決める
- MCPサーバー、plugin、toolの出所、更新者、権限、通信先、署名、ロールバック手順を確認する
- エージェントの通常行動ベースラインを作る
- dwell timeとcoverageを測り、異常検知から人間認知までの時間を短くする
- 1つのアラート種別でAgentic SOAR風の一次トリアージを試す
- 5件同時インシデントを想定した机上演習を行う
ここまで来て初めて、AIエージェント固有のメモリ、MCP、tool poisoning、agent間通信、Agentic SOARへ本格的に踏み込めます。AI以前の基盤が弱い組織は、まず従来の情報セキュリティとゼロトラストの立て直しに取り組み、そのうえでAI固有リスクを上に重ねるのが現実的です。
自社の人間ID、端末、SaaS、NHI、AIエージェント、MCPの棚卸しがまだなら、まずそこからです。ゼロトラストは大きな構想に見えますが、実際の入口は台帳、owner、権限、ログです。
まとめ
Anthropicの「Zero Trust for AI agents」は、新しい理論を作っている文書というよりは、既存のゼロトラスト原則をAIエージェントの実装単位へ落とした文書です。
これはAI時代の現代において非常に重要な考え方です。
AIエージェントは、便利なAI機能ではなく、IDを持ち、権限を使い、ツールを呼び、メモリを持つ業務主体です。だからゼロトラストの対象は、人間、端末、SaaS、NHIに続いて、AIエージェントまで広がります。
これから重要になるのは「AIを禁止するか」ではありません。「侵害されても、誘導されても、誤作動しても、被害を限定できる設計で使えるか」です。
攻撃者がAIを使うことによってリスクが迅速に訪れるなら、守る側もAIを使って、棚卸し、ログ相関、一次トリアージ、影響範囲の確認を迅速にする必要があります。人間が判断すべきところは残しつつ、人間が毎回集めなくてよい証拠はAIに集めさせる。この分担を設計することも、AI時代のゼロトラストの一部です。
そのために最初にやることは、難しいAIセキュリティ製品を買うことではありません。人間ID、端末、SaaS、NHI、AIエージェントを同じ台帳に載せ、権限を絞り、ログを残し、高リスク操作に人間の判断を残すことです。
AIエージェント時代のゼロトラストは、人間だけのものではありません。
FAQ
AIエージェントのゼロトラストとは何ですか
AIエージェントを、ID、権限、ツール、メモリ、ログを持つ業務主体として扱い、アクセスごと、操作ごとに文脈を評価し、最小権限にし、侵害前提で被害範囲を限定する考え方です。
AIエージェントはNHIとして扱うべきですか
扱うべきです。AIエージェントがAPIキー、OAuthトークン、サービスアカウント、MCPサーバーなどを使って業務システムへアクセスするなら、人間ではない主体として棚卸し、owner、権限、ローテーション、失効手順を管理する必要があります。
MCPサーバーのセキュリティでは何を見るべきですか
出所、管理者、更新履歴、署名、通信先、要求権限、ツール定義、schema、metadata、ログ、停止手順を見ます。MCPサーバーはエージェントの判断材料と実行経路になるため、通常の外部ライブラリやSaaS連携よりも強く管理すべきです。
プロンプトインジェクション対策だけでは十分ですか
不十分です。プロンプトインジェクションは重要ですが、Tool Poisoning、Tool Chaining、Memory Poisoning、Agent間通信、NHIの権限過多も同時に見なければいけません。
Agentic SOARでは何を自動化すべきですか
証拠収集、ログ相関、一次トリアージ、影響範囲の候補出し、調査メモ作成を自動化するのが現実的です。事業影響の大きい封じ込め、顧客通知、外部開示、法務判断は人間の判断を残すべきです。
参考資料
- Anthropic, Zero Trust for AI agents, 2026-05-27: https://claude.com/blog/zero-trust-for-ai-agents
- Anthropic, Zero Trust for AI Agents: A security framework for deploying autonomous AI agents in the enterprise: https://cdn.prod.website-files.com/6889473510b50328dbb70ae6/6a1611a04085d7cd3dadc924_Claude-eBook-Zero-Trust-for-AI-Agents-05182026.pdf
- Anthropic, Claude Project Glasswing, 2026-04-07: https://www.anthropic.com/project/glasswing
- Anthropic, Project Glasswing: An initial update, 2026-05-22: https://www.anthropic.com/research/glasswing-initial-update
- NIST SP 800-207, Zero Trust Architecture: https://csrc.nist.gov/pubs/sp/800/207/final
- NSA, Zero Trust Implementation Guidelines (ZIG): https://www.nsa.gov/Cybersecurity/ZIG/
- OWASP, Top 10 for Agentic Applications: https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
- 齊藤愼仁, ITセキュリティ・ゼロトラスト概論――本質を理解し現代的なITインフラを理解するために, 技術評論社, 2025: https://www.amazon.co.jp/dp/4297149702/
関連する弊社記事
- AIエージェントにゼロトラストを適用する: https://blog.cloudnative.co.jp/articles/ai-agent-zero-trust-implementation/
- Claude Mythos 完全考察|Project Glasswing 12社限定が加速させるビッグテック依存の構造: https://blog.cloudnative.co.jp/articles/claude-mythos-accelerate-big-tech-dependency/
- NHI(Non-Human Identity)管理が一気に立ち上がってきた件: https://blog.cloudnative.co.jp/articles/nhi-non-human-identity-management/
- SaaSに搭載されたAIがまともかどうか評価する: https://blog.cloudnative.co.jp/articles/evaluating-ai-features-in-saas/
- AtlassianがJira・ConfluenceのデータをAI体験改善に利用へ、オプトアウト可否と情シスの対処法: https://blog.cloudnative.co.jp/articles/atlassian-data-contribution-ai-optout/
- 生成AIで生産性は上がりません。その根拠を説明します: https://blog.cloudnative.co.jp/articles/generative-ai-productivity-paradox-explained/
あとがき
何においてもそうなのですが、「時間」というリソースは非常に重要な意味を持ちます。解読に10万年かかるパスワードのリスクはほぼ0とみなせるけど、3日で解読できるパスワードのリスクは全くもって無視できない。
量子コンピュータや、フロンティアAIは情報セキュリティの文脈における「時間」というリソースの感覚値を大きく狂わせてきます。
昨日まで、「これはもうちょい先で良い」と思ってたことが、喫緊の課題として降ってくるわけです。ヒリつきますね。
だけど、対応する我々もAIを使うことができます。しっかりAIを使っていかないとAIによるリスクに対応するのは難しいと思います。
ではまた。
関連記事
AIエージェントを新しい業務主体としてゼロトラストで統制するという本稿のテーマを、NHI管理・継続的認可・AI時代の脆弱性対応といった隣接論点へさらに深掘りしたい方へ、弊社ブログの関連記事を紹介します。
- AIエージェントにゼロトラストを適用する — OWASP Agentic Top 10と実装アプローチ:本稿で参照したAgent OS/AgentMesh/Agent Runtime/Agent SREの4層整理を、OWASP Agentic Top 10と突き合わせて実装手順まで踏み込んだ記事で、Anthropic文書の読み替えを具体的な統制設計に落とすときの土台になります。
- NHI(Non-Human Identity)管理が一気に立ち上がってきた件:本稿が一節を割いて論じた『AIエージェントはNHIを爆発させる』という論点の前提となる、サービスアカウント・APIキー・OAuthトークンなど非人間IDの棚卸しと管理の全体像を解説しています。
- CrowdStrikeのSGNL買収($740M)— AIエージェント時代の『Continuous Identity』が変えるゼロトラスト認可:本稿がAdvancedティアで触れた継続的認可・JIT/JEAという方向性を、CrowdStrikeのSGNL買収という実際の市場動向とContinuous Identityの概念から裏づける記事で、AIエージェント時代の認可がどこへ向かうかを補強します。
- AnthropicのDefending Code Reference Harnessを読む AIに脆弱性対応を任せる前に必要なこと:本稿のProject Glasswingの節で論じた『見つける速度から検証・開示・修正へボトルネックが移る』問題を、AIに脆弱性対応そのものを任せる際の前提条件という角度からさらに掘り下げています。
- AIエージェントが決済する時代のIDと権限制御:本稿が高リスク操作(送信・削除・返金・権限変更)に人間承認を残せと論じたLeast Agencyの考え方を、AIエージェントが決済を行う具体シナリオでIDと権限制御に落とし込んでいます。