どうも おかしん です。
Anthropicが2026年5月27日に、Using LLMs to secure source code という記事を公開しました。あわせて、Claudeで脆弱性発見から修正候補の作成までを回す参照実装として、GitHubで Defending Code Reference Harness も公開されています。
タイトルだけ見ると「AIが脆弱性を見つけて直してくれる時代が来た」という話に見えるかもしれません。ただ、公式ブログとリポジトリを読むと、むしろ逆です。
この記事で伝えたいことはシンプルです。AIで脆弱性を見つけることより、見つけた後に検証し、優先順位を付け、修正をレビューできる運用の方が重要になる、という話です。
Claudeや他のAIエージェントにコードを読ませる試みは、セキュリティチームや開発現場で始まっています。問題は、その先です。AIが出した指摘を誰が脆弱性として受け入れるのか。PoCは再現できるのか。修正候補は既存機能を壊さないのか。誤検知だらけのレポートを開発チームへ投げつけていないか。自律実行エージェントに、本番や認証情報へ触れる経路を渡していないか。
ここを設計しないまま「AIでセキュリティレビューを高速化する」と言うと、たぶん現場が詰まります。
先に結論: 発見よりも、発見後の運用が詰まる
Anthropicの公式ブログで一番重要な主張は、発見そのものが並列化しやすくなり、ボトルネックが verification、triage、patching に移っている、という整理です。
2026年5月22日時点の AnthropicのCoordinated Vulnerability Disclosure dashboard では、Anthropicは1,596件の脆弱性を281のOSSプロジェクトへdiscloseし、そのうち97件がpatched upstream、88件がCVEまたはGHSAを取得したと説明しています。ただし、この1,596件はMythos Previewが見つけた脆弱性の総数の一部で、すべてが同じ独立検証を経たわけではなく、false positiveも含み得るとダッシュボード上で明記されています。ここで見るべきなのは「AIが大量に見つけた」という数字だけではありません。候補を見つける、外部研究者や人間がtriageする、maintainerへ報告する、patchされる、という間に大きな落差があることです。
これは企業の中でも同じです。AIエージェントが100件の指摘を出せるようになると、次に詰まるのは次のような作業です。
- 本当に自社の脅威モデル上の脆弱性なのかを判断する
- 再現可能な証拠をそろえる
- 重複や同一根本原因をまとめる
- 影響度と優先度を決める
- 修正候補が本当に安全かを見る
- 開発チームが受け取れる量と形式に整える
つまり、AIによって「見つける力」が上がるほど、セキュリティチームと開発チームには、検証、説明、修正、承認の運用力が求められます。
Anthropicは何を公開したのか
今回見る一次情報は大きく2つあります。
1つ目は、Anthropicの公式ブログ Using LLMs to secure source code です。これは、Claude Opusを使って、脅威モデル作成、脆弱性発見、検証、トリアージ、パッチ作成をどう進めるかを整理した実務ガイドです。
2つ目は、GitHubの anthropics/defending-code-reference-harness です。READMEでは、Claude Code上で使う /quickstart、/threat-model、/vuln-scan、/triage、/patch、/customize などのskillsと、自律的にrecon、find、verify、report、patchを回す harness/ が説明されています。
あわせて、Anthropicはマネージド製品として Claude Security も提供しています。Claude Securityは、コードベースをscanし、findingをvalidateし、review/approve可能なpatchをsuggestするpublic betaとして説明されています。2026年6月6日時点の公式ページでは、Claude Enterprise向けに利用可能とされ、patchは人間のreview and approvalを前提にしています。
ざっくり分けると、Defending Code Reference Harnessは自社で考えるための公開参照実装で、Claude SecurityはAnthropicが提供するマネージド製品です。この記事では前者を主に読みます。
本稿では、Claude Securityの製品紹介ではなく、公開された参照ハーネスと公式ブログから、企業がAIエージェントへセキュリティ業務を任せる前に何を見るべきかを整理します。
Defending Code Reference Harnessは製品ではなく参照実装
ここは最初に押さえたいです。
Defending Code Reference HarnessのREADMEは、このリポジトリを製品ではなく参照実装として説明しています。また、リポジトリはメンテナンスされず、contributionも受け付けないと明記されています。
つまり、これをそのまま社内へ入れて「AI脆弱性診断基盤ができました」と言うものではありません。
参照ハーネスの自律パイプラインは、C/C++のメモリ脆弱性を見つける構成が中心です。DockerでターゲットをASAN付きにbuildし、gVisorのsandbox内でagentを走らせ、egressをClaude APIに制限する前提になっています。Webアプリの業務ロジック、SaaS設定、ID連携、IaC、クラウド権限などを、何も考えず同じ形で自動検査できるわけではありません。
ただし、参照実装としてはかなり示唆があります。特定のコードや言語に閉じた話ではなく、AIエージェントをセキュリティ業務へ組み込むときの基本設計が見えるからです。
公式ブログのfind-and-fix loopを読む
Anthropicの公式ブログは、AIを使ったコードセキュリティの流れを6ステップで整理しています。
| ステップ | 何をするか | 実務での意味 |
|---|---|---|
| Threat model | 何を脆弱性として扱うかを決める | 信頼境界、守る資産、攻撃者が触れる入力を明確にする |
| Sandbox | agentとPoCを隔離して動かす | 本番、認証情報、外部ネットワークへ影響させない |
| Discovery | モデルに脆弱性候補を探させる | 目的と文脈を渡し、探索を並列化する |
| Verification | exploit可能か独立に確認する | 誤検知とコード上の単なる不具合を減らす |
| Triage | 重複排除、severity、優先度付けをする | 開発チームが扱える短いリストへ変換する |
| Patching | 修正し、PoC再現停止と回帰を確認する | AI生成patchを人間がレビューできる状態にする |
この流れで一番好きなのは、Threat modelとSandboxが最初に置かれている点です。AIにとにかくコードを読ませるのではなく、「何を脆弱性と呼ぶのか」「どの入力を信頼するのか」「どの環境で実行してよいのか」を先に決める。
これは、情シスやセキュリティ担当がSaaSやAIエージェントを扱うときの考え方と同じです。AIエージェントを業務主体として扱うなら、どの権限で、どのツールを、どの環境で、どこまで自律実行できるかを決める必要があります。
参照ハーネスの7段階パイプライン
Defending Code Reference HarnessのREADMEでは、自律パイプラインが7段階で説明されています。ここでは、公式説明を実務向けに読み替えて整理します。
| 段階 | 役割 | 読み取れる設計思想 |
|---|---|---|
| Build | ターゲットをASAN付きDocker imageとしてbuildする | 毎回同じ環境で再現できるようにする |
| Recon | agentがコードを読み、攻撃面を分割する | 並列agentが同じ浅いbugへ収束しないようにする |
| Find | 複数agentが malformed input を作り、crashを探す | 発見は並列化するが、証拠としてPoCを残す |
| Verify | 別agentがfresh containerでcrashを再現する | 発見agentの会話や思い込みから独立させる |
| Dedupe | 既報bugや重複と比較する | 量ではなく、根本原因単位で扱う |
| Report | exploitability analysisを書く | 開発者が判断できる構造化レポートにする |
| Patch | 修正候補を作り、build、再現停止、回帰、re-attackを確認する | patchは自動適用ではなく、検証済みdraftとして扱う |
ここで重要なのは、発見agentと検証agentが分離されていることです。発見したagentの推論をそのまま信じるのではなく、別のgrader agentがfresh containerでPoCを再現します。渡すのは基本的にPoCであり、発見agentの思考過程ではありません。
これはセキュリティレビューとしてかなり自然です。見つけた人と、再現確認する人を分ける。報告した人の熱量ではなく、証拠で判断する。AIエージェントでも同じです。
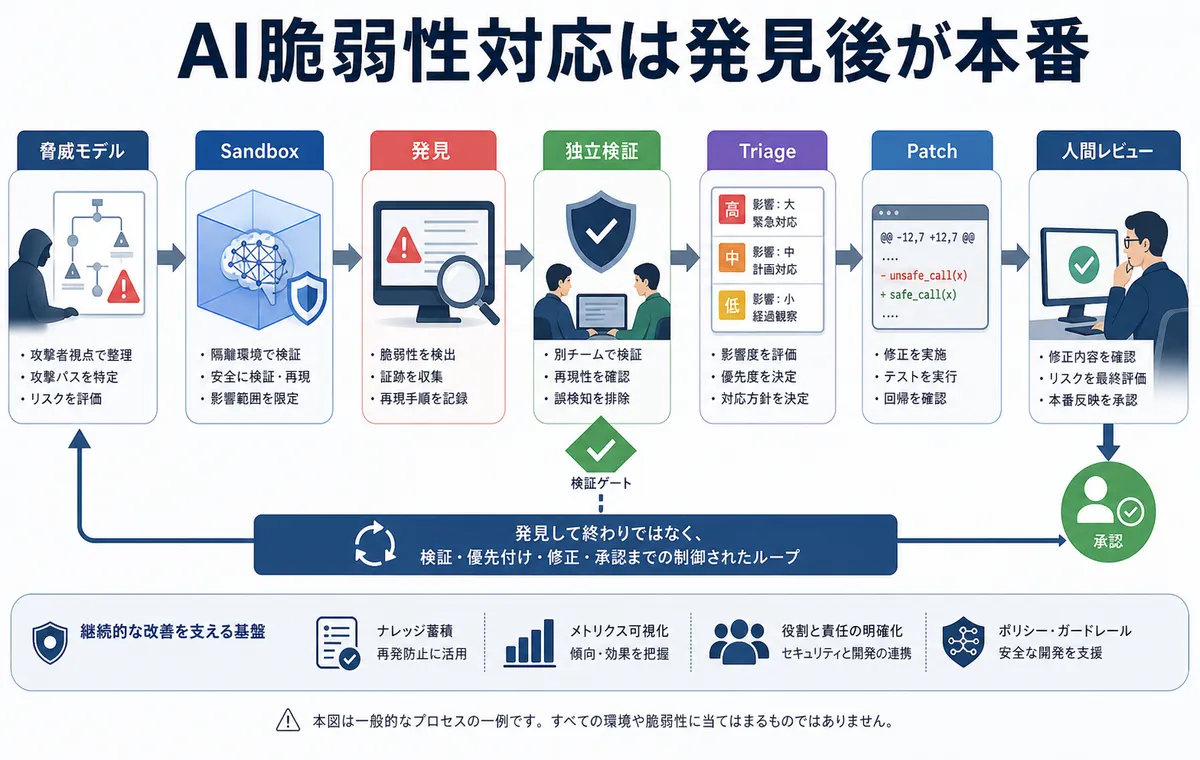
この図で言いたいのは、発見の右側を分けて見ることです。検証、triage、patch、人間レビューを別のゲートとして置くと、AIの出力をそのまま開発チームへ流すのではなく、扱える証拠と判断に変換できます。
実務で見るべき5つの統制点
この参照ハーネスから、企業側が見るべき統制点を5つに分けて整理します。
1. 脅威モデルを先に作る
AIが誤検知する理由の多くは、コードの読み間違いだけではありません。どの入力が信頼されているのか、どの経路が外部から到達可能なのか、どの構成が本番で有効なのかを知らないからです。
たとえば、SQL injectionのように見えるコードがあったとしても、そこに到達できるのが管理者だけなのか、認証なしの外部ユーザーなのかでseverityは変わります。逆に、モデルが内部向けだと思い込んだAPIが実際には外部公開されていれば、見逃しになります。
AIにコードを読ませる前に、少なくとも次を決めておくべきです。
- 守る資産
- 外部から到達できる入口
- 信頼する入力と信頼しない入力
- 過去に起きた脆弱性の型
- 自社では脆弱性として扱わないもの
- severityを上げる条件、下げる条件
これは、巨大な文書を作れという話ではありません。最初は THREAT_MODEL.md のような軽い形でよいと思います。大事なのは、AIにも人間にも同じ判断基準を読ませることです。
2. サンドボックスはpromptではなく構成で強制する
公式の docs/security.md はかなりはっきり書いています。モデルは、実際にアクセスできる能力を使います。だから、制約はpromptではなくcodeとconfigurationで強制すべきです。
「ネットワークには出ないでください」「本番には触らないでください」とpromptに書くだけでは弱いです。実際にネットワーク経路があれば、agentはそれを使うかもしれません。ローカルに ~/.aws、~/.ssh、.env が見えていれば、意図せず読めてしまうかもしれません。
参照ハーネスでは、自律パイプラインを bin/vp-sandboxed で起動し、各agentをgVisor container内に閉じ込め、egressをAPIに制限する設計が説明されています。普通のDockerやprivileged containerではなく、より強い隔離を使う理由は、agent自身とターゲットコードの両方が予期しない動きをし得るからです。
MacやWindowsで軽く試したくなる気持ちは分かります。ただ、自律実行でターゲットコードをbuildしてcrashさせるなら、ローカル端末を作業場にしない方がよいです。Linux VM、throwaway環境、認証情報なしの分離環境を用意する。ここは面倒でも飛ばさない方がよいと思います。
3. 検証agentを独立させる
AIが出した脆弱性候補は、まず疑うべきです。
ここでいう「疑う」は、AIを信用しないという感情論ではありません。セキュリティの証拠として扱うなら、再現性、到達性、補償統制、影響範囲を確認する必要がある、という話です。
参照ハーネスでは、find agentとgrader agentを分けています。graderはfresh containerでPoCを再実行し、crashが本当に起きるかを見る。発見agentの推論を読ませすぎると、検証agentが追認してしまう可能性があるため、渡す情報を絞ります。
人間の運用でも同じです。AIが出したfindingを、別の観点で再現する。可能なら別モデル、別agent、別担当者で見る。特にHigh以上のfindingは、反証するつもりで読む。これをしないと、誤検知の山が開発チームへ流れます。
4. Triageを開発チームに押し付けない
AIで発見が増えると、開発チームへ渡すレポートの品質が重要になります。
「このコードが危険そうです」という長いレポートを大量に渡しても、現場は動けません。必要なのは、重複が畳まれ、根本原因が説明され、再現手順があり、severityの理由があり、修正優先度が分かる短いリストです。
Anthropicの公式ブログでも、triageはalert fatigueを防ぐための工程として扱われています。これはかなり大事です。セキュリティチームがAIで大量のfindingを出せるようになるほど、開発チームの信頼を失うリスクも上がります。
自社で試すなら、まず「AIが何件見つけたか」ではなく、次を見た方がよいです。
- confirmed findingの割合
- 重複除去後の件数
- High以上のうち人間が同意した件数
- 修正候補が受け入れられた件数
- 既存scannerやbug bounty backlogを減らせた件数
- 開発チームがレビューに使った時間
発見数だけをKPIにすると、雑なセキュリティレポートを増やすインセンティブになります。
5. Patchは自動適用ではなく、人間が読むdraftにする
参照ハーネスの docs/patching.md では、patch stageがverification ladderを持っています。Buildできるか、元のPoCが止まるか、既存テストが通るか、fresh find agentが再攻撃しても抜けないかを見る、という流れです。
ここまでやっても、生成patchは人間レビュー前提です。公式ドキュメントでも、patch.diffは強いdraftとして扱うべきで、新しい問題がないことや根本原因が完全に消えたことまでは保証しないと説明されています。
これは現実的です。AI生成patchには、よくある失敗があります。
- crash地点だけを塞ぎ、根本原因を残す
- 正常な入力まで拒否する
- 既存の依存関係や業務仕様を壊す
- 関係ないrefactorを混ぜる
- エラーを握りつぶして見かけ上crashを止める
AIがpatchを書けることと、そのpatchを本番へ入れてよいことは別です。セキュリティpatchは、機能修正であると同時に、障害や新しい脆弱性を作る可能性もあります。人間のownerが読み、必要なら小さく直し、テストとrollback手順をそろえてから入れるべきです。
自社で試す前のチェックリスト
ここまでを、自社で試す前の確認項目に落とします。
| 観点 | 確認すること | なぜ必要か |
|---|---|---|
| 対象 | どのrepo、どの依存関係、どの脆弱性classを見るか | 対象が曖昧だと発見数だけが増える |
| 脅威モデル | 守る資産、信頼境界、到達可能な入口を文書化しているか | AIと人間の判断基準をそろえる |
| 実行環境 | 認証情報なし、外部到達制限あり、再現可能なsandboxか | agentとターゲットコードの暴走を閉じ込める |
| 検証 | findingを別agentまたは人間が再現確認するか | 誤検知と過剰severityを減らす |
| Triage | 重複、severity、owner、期限を整理するか | 開発チームが扱える形にする |
| Patch | build、PoC停止、回帰、再攻撃、人間レビューを見るか | 自動修正による事故を避ける |
| 証跡 | transcript、PoC、report、patch、判断理由を保存するか | 監査、再現、後続改善に使う |
| 権限 | agentが使うAPI key、OAuth、MCP、CI権限を棚卸ししているか | NHIと管理プレーンのリスクを制御する |
この表を見ると、AI導入というより普通のセキュリティ運用に見えると思います。実際、そうです。AIエージェントは新しい道具ですが、企業で安全に使うために必要なのは、資産、ID、権限、ログ、承認、復旧を説明できる状態です。
最初の一手としては、対象repoを1つに絞るのがよいです。そのうえで、THREAT_MODEL.md、認証情報を持たない分離実行環境、findingの採否基準、patch承認者を先に決めます。いきなり全社のコードへ広げるより、小さく一周して、検証とtriageにどれだけ人手がかかるかを測る方が現実的です。
この点は、弊社ブログの NHI管理の記事 や、AIエージェントが決済する時代のIDと権限制御 ともつながります。AIエージェントがコードを読み、コマンドを実行し、patchを作り、CIやPRへ接続するなら、それはただのチャットではありません。権限を持った業務主体です。
既存のAIエージェント統制とどうつなげるか
Defending Code Reference Harnessを読むと、AIエージェントのセキュリティは「プロンプトインジェクション対策」だけでは足りないことが分かります。
もちろん、prompt injectionは重要です。参照ハーネスでも、ターゲット由来のtraceやreport、build/test outputがpatch promptに入るため、<untrusted_data> のような境界で扱う説明があります。ただし、それはmitigationであって保証ではありません。
本当に見るべきなのは、もっと地味なところです。
- agentが読めるファイル
- agentが実行できるコマンド
- agentが出られるネットワーク
- agentが持つcredential
- agentが接続するMCPや外部ツール
- agentが作ったdiffを誰が承認するか
- agentの実行ログを誰が確認するか
これは ゼロトラストの基本思想 でいう、業務、データ、資産、アイデンティティを前提に、リスクを受容可能な水準へ下げるための設計原則に近い話です。AIだから特別なのではなく、AIが業務主体として動くから、既存の統制対象が広がるということです。
私が今回の参照ハーネスを読んで面白いと思ったのは、AI活用の話なのに、最終的にはかなり古典的なセキュリティ運用へ戻ってくるところです。再現環境を作る。証拠を残す。別の人が検証する。重複を整理する。小さなpatchを作る。人間がreviewする。ログを残す。
地味ですが、ここを飛ばすとAIの速度に運用が負けます。
まとめ
AnthropicのDefending Code Reference Harnessは、AIで脆弱性を自動的に見つけて直す万能ツールではありません。むしろ、AIにセキュリティ業務を任せるなら、どれだけ周辺の運用設計が必要かを見せる参照実装です。
読むべきポイントは、次の5つです。
- 脅威モデルを先に作る
- サンドボックスをpromptではなく構成で強制する
- 発見agentと検証agentを分ける
- Triageを開発チームへ丸投げしない
- Patchは自動適用ではなく、人間が読むdraftにする
AIによって脆弱性発見は速くなります。ただし、速く見つけるだけでは守れません。守るためには、何を脆弱性と呼ぶか、どう再現するか、誰が優先度を決めるか、どう直すか、どこで人間が止めるかを設計する必要があります。
情シスやセキュリティ担当が見るべきなのは、AIスキャナの派手さではなく、その周囲にある地味な運用です。ここを先に整えておくと、AIエージェントは単なるノイズ発生源ではなく、セキュリティチームと開発チームの仕事を前に進める道具になります。