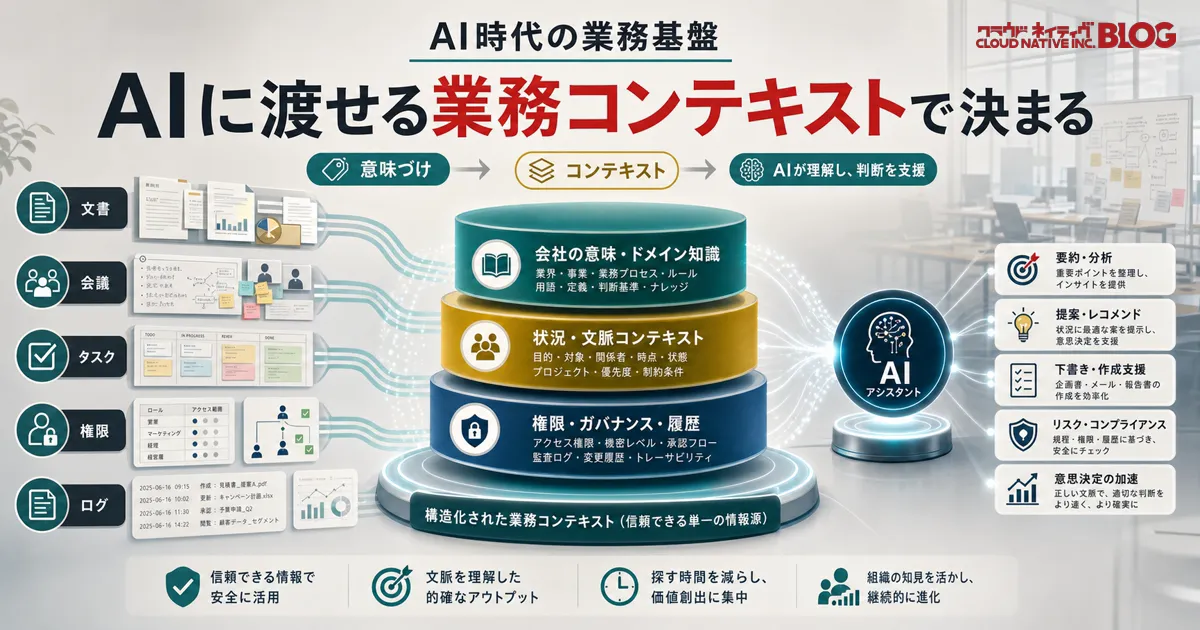
どうも おかしん です。
AI導入でよく起きるのは、「社内データにつながるようにしたのに、回答が浅い」という状態です。
AIが社内文書を検索できる。会議録も見られる。タスクやチケットも探せる。それでも、実務で使うと「そうではなくて、この案件では何を優先すべきかを知りたい」と感じることがあります。
これはモデルだけの問題ではありません。多くの場合、AIに渡している情報が、業務の意味や流れに接続されていないことが原因です。
Microsoft 365 Copilot、Notion AI、Atlassian Rovo、Azure OpenAI、Amazon Bedrock、MCP。入口は会社によって違います。ただ、どの入口を選ぶ場合でも、最後に問われることはかなり似ています。
AI導入で重要なのは、どのモデルを選ぶかだけではなく、AIに何を、どの意味づけで、誰の権限で、どの業務目的のために渡すかです。
この記事では、2026年6月7日時点の公開情報をもとに、「AIが業務コンテキストを扱える状態」とは何かを整理します。
AI導入の本質は、モデル選定だけではない
AI導入の話は、ついモデルやツールの比較から始まりがちです。
- GPTがよいのか
- Claudeがよいのか
- Geminiがよいのか
- Copilotがよいのか
- Notion AIがよいのか
- Rovoがよいのか
もちろんモデルの能力は重要です。推論力、速度、コスト、対応言語、ツール連携、管理機能は無視できません。
ただ、業務でAIを使うときに本当に差が出るのは、モデル単体の賢さだけではありません。モデルに何をどう渡すか。渡した情報をどう意味づけできるか。誰の権限で、どの範囲の情報を、どの業務目的のために使わせるか。ここが弱いと、どれだけ賢いモデルを入れても「それっぽい一般論」で止まります。
これは、AIを使うのが上手い人は、プロンプトではなく進め方を設計しているという話にも近いです。プロンプトの言い回しだけではなく、AIに渡す材料、作業順序、確認ポイント、判断基準を人間側が設計する必要があります。
業務AIでも同じです。
AIに必要なのは、社内データへの入口だけではありません。業務の流れ、過去の経緯、関係者、優先順位、制約、権限、最新状態まで含めた文脈です。
AIに業務コンテキストを渡す方法は、大きく二つあります。一つは、業務データをAIのために外へ集め、RAGやエージェント基盤を別途作る方法です。もう一つは、業務コンテキストがすでに蓄積されている場所で、ネイティブにAIを動かす方法です。Microsoft 365ならCopilot / Work IQ、NotionならNotion AI、AtlassianならRovoが、この後者の方向にあります。
社内データを読めるだけでは、仕事に使えるとは限らない
ここで分けて考えたいのが、「AIが情報へ到達できること」と「その情報を仕事の前提として扱えること」です。
前者は、AIが社内の記録を探しに行ける状態です。社内文書、議事録、メール、チャット、チケット、問い合わせ、顧客情報、プロジェクト情報、ログなどにアクセスできる。これは入口として大事です。
ただ、データにアクセスできるだけでは、良い判断には直結しません。
新人に社内システムの権限を全部渡しても、いきなり良い判断はできません。どの画面を見るべきか、どの情報が重要か、なぜこの案件が止まっているのか、誰に確認すべきか、過去に何を決めたのか、今どの制約が効いているのかが分からないからです。
AIも同じです。
社内文書を検索できても、次のことが分からなければ実務では弱いままです。
- なぜ今この話をしているのか
- これまで何があったのか
- 誰が何を気にしているのか
- どの制約の中で判断するのか
- 次に何を決めたいのか
- そのデータが業務の流れの中で何を意味するのか
たとえば、「来週のA社との定例に向けて、前回の論点と未完了タスクを整理して」とAIに頼む場面を考えます。
AIが会議メモを検索できるだけなら、関連しそうな議事録を並べるところまではできます。けれど、A社が重要顧客なのか、前回誰が何を約束したのか、今期の優先度は高いのか、誰のタスクが遅れているのかが分からなければ、実務で使える整理にはなりません。
SaaS管理でも同じです。「この共有設定は危ないか」とAIに聞く場合、共有リンクや監査ログを見つけるだけでは不十分です。そのフォルダに採用候補者情報が含まれるのか、外部共有が原則禁止なのか、例外承認が必要なのかまで分かって、初めて危険度や是正方法を考えられます。
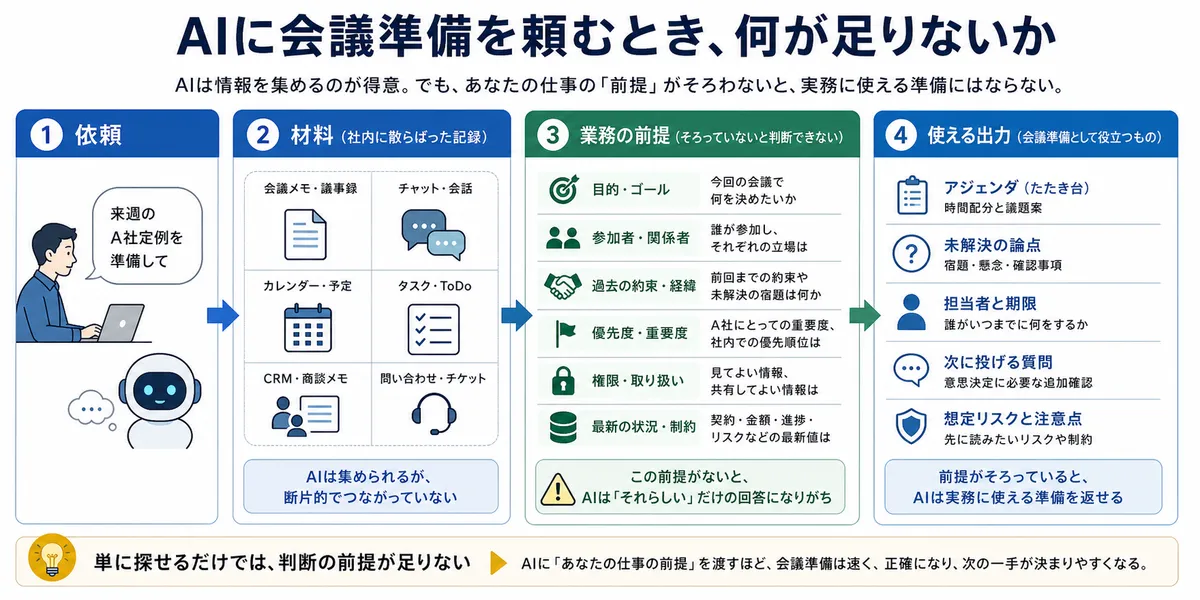
必要なのは、単にファイルや検索結果を渡すことではありません。人が判断するときに確認する目的、関係者、制約、最新状態を、AIにも分かる形で渡すことです。
ここを間違えると、「AIに社内データをつなぎました。でも回答はいまいちです」という状態になります。
AIに渡したい業務コンテキストとは何か
業務コンテキストと言うと少し抽象的ですが、実際にはかなり具体的です。
| 種類 | 例 | AIに渡ると何が変わるか |
|---|---|---|
| 文書 | 規程、手順書、設計書、提案書、FAQ | 会社のルールや過去の説明に沿って答えられる |
| 会議 | 議事録、文字起こし、決定事項、宿題 | なぜその判断になったのかを追える |
| タスク | 担当者、期限、優先度、依存関係 | 次に何を進めるべきか判断しやすくなる |
| プロジェクト | 目的、スコープ、リスク、進捗 | 個別タスクを全体の流れに接続できる |
| 問い合わせ | 過去の質問、回答、未解決事項 | 同じ質問への回答品質が上がる |
| 意思決定ログ | 承認、却下、保留、理由 | 過去の判断基準を再利用できる |
| 人と組織 | 役割、チーム、承認者、関係者 | 誰に確認すべきかが分かる |
| 権限 | 閲覧範囲、編集範囲、機密区分 | 見せてよい情報だけを使える |
| ログ | 実行履歴、参照履歴、操作履歴 | 後から検証しやすくなる |
この一覧を見ると、AI導入はAIだけの話ではないことが分かります。ドキュメント管理、会議運用、タスク管理、プロジェクト管理、問い合わせ管理、ID管理、権限管理、監査ログ、データ分類が全部つながります。
だから、AI導入を「AIツールの契約」だけで進めると苦しくなります。AIに渡す前の業務基盤が荒れていると、AIはその荒れた状態を増幅します。
コンテキストだけでは決まらない
ここまで「AIに渡せる業務コンテキストが重要」と書いてきました。
ただし、コンテキストだけを強調しすぎると、もう一つの誤解が生まれます。会議の目的、関係者、期限、過去の経緯、現在の制約をAIに渡せば、それだけでよい判断ができるのか。私は、そこまで単純ではないと思っています。
たとえば、AIに「A社の更新リスクをまとめて」と頼む場面を考えます。
AIが使える情報として、前回会議の議事録、未完了タスク、問い合わせ履歴、契約書、商談メモ、利用状況レポートがあるとします。これらは大事なコンテキストです。けれど、それだけではまだ判断できません。
そもそも、その会社で「更新リスク」とは何を指すのか。契約終了の可能性なのか、利用縮小の兆候なのか、支払い条件の交渉なのか、競合への乗り換えなのか。営業とCSで「重要顧客」の意味が違うなら、AIは同じ言葉を見ても違う判断をしてしまいます。
ここで必要になるのが、「そもそも会社の中でその言葉やデータが何を意味するのか」をそろえることです。
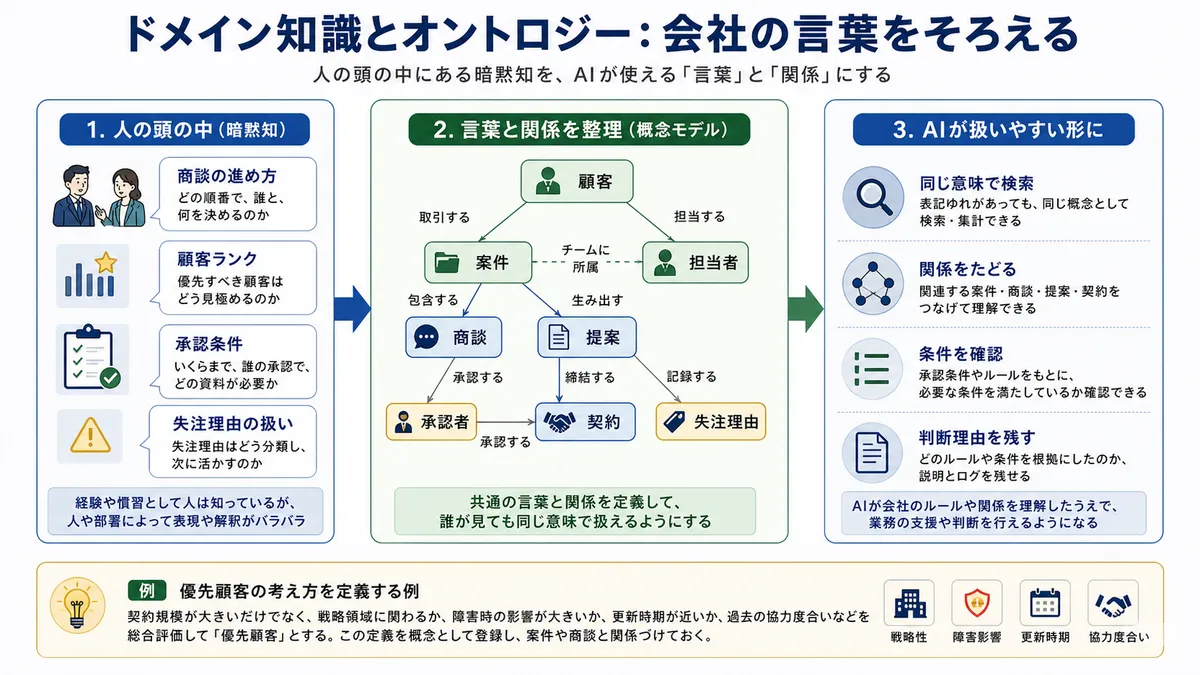
営業、CS、人事、経理、IT運用のような業務領域を、ここではドメインと呼びます。ドメイン知識とは、その領域で人が持っている知識です。営業なら、商談の進め方、顧客ランクの意味、承認条件、失注理由の扱い、契約前後の責任分界などが含まれます。
ただ、人の頭の中にあるドメイン知識のままだと、AIやシステムは扱いにくいです。そこで、顧客、契約、商談、提案、受注、担当者、決裁者、優先顧客といった概念の意味や関係を整理する必要があります。少し硬い言葉では、これをオントロジーと呼ぶことがあります。
オントロジーという言葉に身構える必要はありません。実務的には、社内で使っている言葉、データ、役割、状態、ルールの意味をそろえることです。
同じことは会議準備でも起きます。AIに「明日の定例会議の準備をして」と頼むなら、「定例会議」がどの顧客の、どの契約に紐づき、誰が参加し、前回どんな宿題が出た会議なのかを理解できる必要があります。
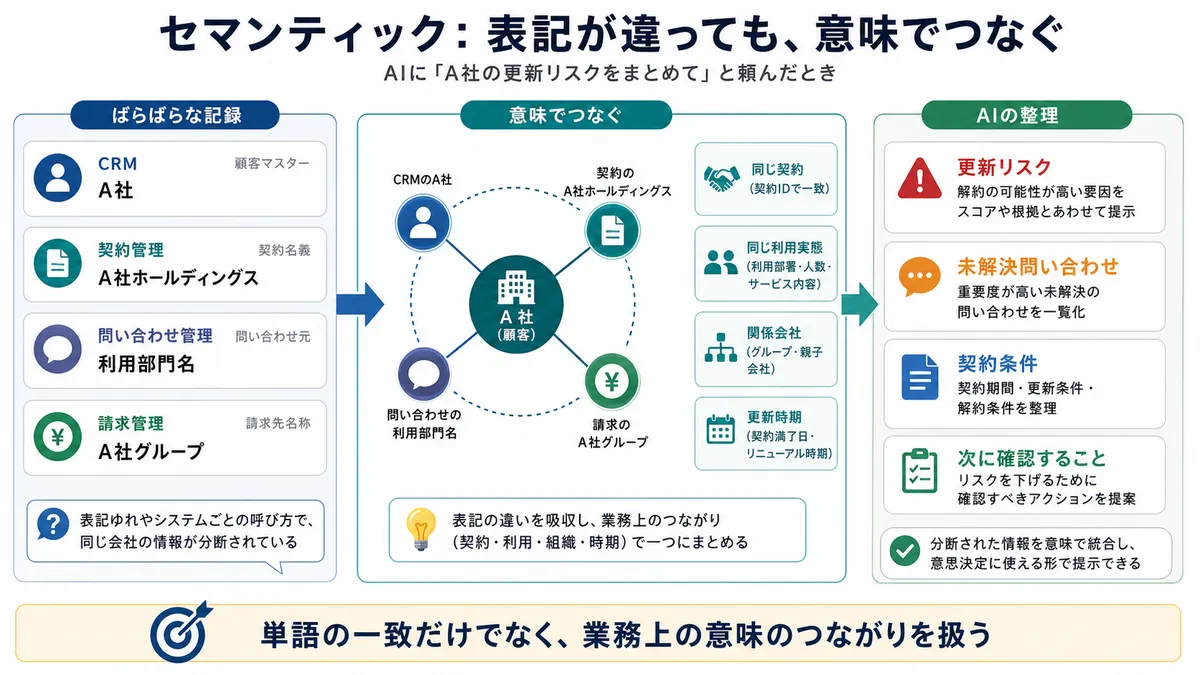
次に大事なのは、表記が違う記録を業務上の意味でつなげられるかです。
CRMでは「A社」、契約管理では「A社ホールディングス」、問い合わせ管理では利用部門名で記録されているかもしれません。文字列が一致していなくても、同じ契約や利用実態に関係する情報としてつなげられるか。こうした「文字列として一致しているか」ではなく、「意味としてどうつながっているか」を扱う考え方が、セマンティックという観点です。
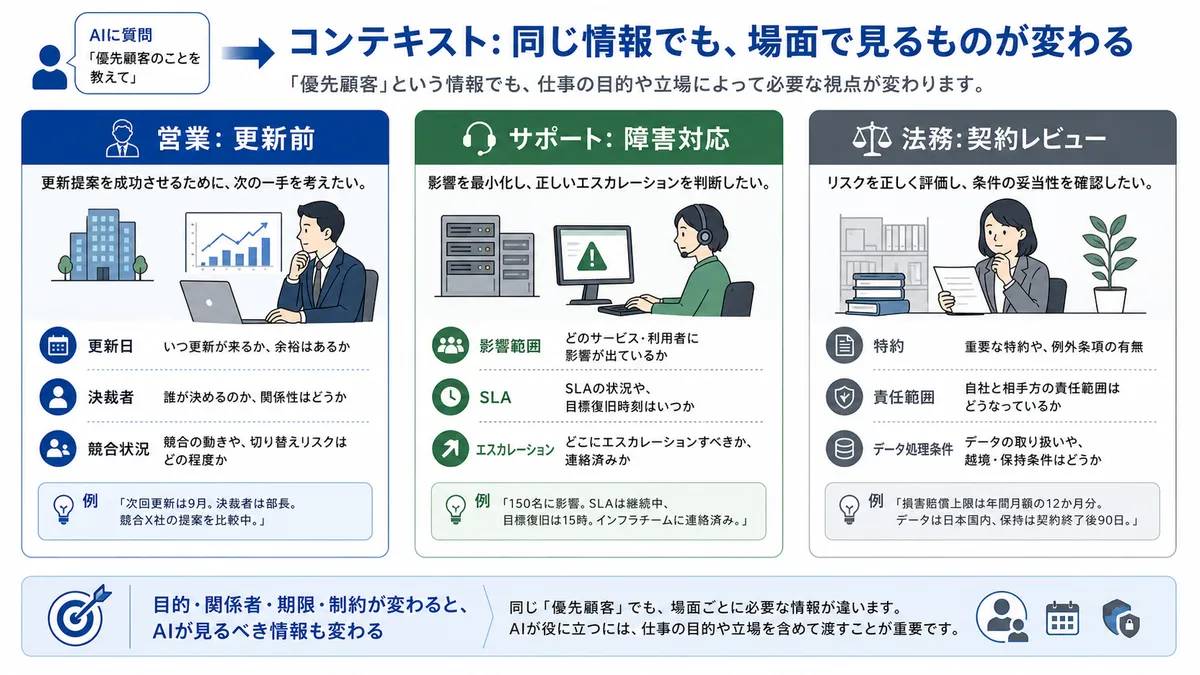
最後に、同じ言葉でも場面によって扱いが変わります。同じ「優先顧客」でも、営業の四半期末、サポートの障害対応、法務の契約レビュー、CSのオンボーディングでは見るべき情報が違います。これがコンテキストです。
営業がAIに聞くなら、次回更新日、決裁者、競合状況が重要かもしれません。サポートの障害対応なら、影響範囲、SLA、暫定回避策、エスカレーション先が重要です。法務の契約レビューなら、特約、責任範囲、データ処理条件を見るべきです。
整理すると、AIに必要なのは三つです。
- ドメイン知識: 営業、CS、人事、経理、IT運用などの業務領域で人が持つ知識
- 意味づけ: 社内の言葉、データ、役割、状態、ルールの関係をそろえること
- コンテキスト: 今この場面で、誰が、何の目的で、どの制約のもとで情報を使うか
会社の言葉と関係性がそろっていないと、AIは言葉の意味を誤解します。場面ごとのコンテキストがないと、AIは一般論で答えます。
だから、社内検索基盤やRAGを作るときも、単に文書をベクトル化するだけでは足りません。用語、関係、権限、最新性、業務フロー、判断条件をどう扱うかを考える必要があります。
意味づけをどこで維持し、業務コンテキストをどこに蓄積するか
ここまで来ると、情シスや経営者が考えるべき問いはかなり具体的になります。
AIをどれにするかの前に、社内の言葉、役割、状態、ルールの意味づけをどこで維持し、日々の業務コンテキストをどこに蓄積するかを決める必要があります。
もう少し実務的に言うと、次の問いです。
- 社内の言葉、役割、状態、ルールの意味はどこでそろえるのか
- 会議、チャット、文書、タスク、意思決定ログはどこに残すのか
- それらは誰の権限で読めるのか
- 古い情報、未承認情報、機密情報をどう区別するのか
- AIが参照した履歴や実行した操作をどこで追うのか
- コストをユーザー、部署、用途、エージェント単位でどう見るのか
ここで、Microsoft 365のような業務基盤に仕事の流れを寄せるメリットが見えてきます。ここでいう業務基盤とは、メール、予定、会議、チャット、ファイル、人、組織、ID、権限、ログまでを同じ管理単位で扱えるものです。
こうした基盤に業務が集まっていれば、AIのために別途「文脈の置き場」を作るコストを減らせます。これは単なるライセンス費用の話ではありません。接続を作るコスト、権限を同期するコスト、検索インデックスを保つコスト、ログを突き合わせるコスト、例外処理を運用するコストを減らせる、という意味です。
ここで見たいのは、「業務コンテキストをAIのために外へ持ち出す」のか、「業務コンテキストがある場所でAIを動かす」のかです。前者は自由度が高い一方で、権限、最新性、意味づけ、ログを自社で再構築する必要があります。後者はプラットフォームの制約を受けますが、日々の業務で生まれる文脈に近い場所でAIを動かせます。
一方で、Google Workspace、Slack、Notion、Jira、Box、Salesforce、各種SaaSが混在している場合、業務コンテキストは自然には一か所に集まりません。この場合は、「どこを主たる業務コンテキストの置き場にするか」と「どこまで横断接続するか」を設計しないと、AIごとに別々の文脈を見て、別々の答えを出す状態になります。
大事なのは、AIのために後から文書を整理することではありません。日々の業務を進めるだけで、AIが扱える形でコンテキストが蓄積されるようにすることです。
たとえば、会議をしたら議事録と決定事項が残る。決定事項からタスクが作られる。タスクには担当者、期限、依存関係、関連文書が紐づく。問い合わせには顧客、製品、影響範囲、回答、未解決理由が残る。承認や却下には理由が残る。こういう業務設計があると、AIは後から文脈をたどれます。
逆に、会議は口頭、決定はチャットの流れ、タスクは各自のメモ、問い合わせは属人対応、承認理由は残らない、という状態では、AIに渡す以前にコンテキストが存在しません。
入口が違っても確認すべきことは同じ
Notionを使うか、Microsoft 365を使うか、Atlassianを使うか、内製するか。入口は会社によって違います。
ただ、確認すべきことはかなり共通しています。製品名を見る前に、この表を見たほうが判断しやすいです。
| 確認項目 | 見ること | 放置すると何が起きるか |
|---|---|---|
| 業務コンテキストの所在 | 文書、会議、タスク、問い合わせ、意思決定ログがどこにあるか | AIが断片的な情報だけで答える |
| 意味づけ | 社内の言葉、役割、状態、ルールがそろっているか | 同じ言葉を部門ごとに違う意味で扱う |
| 権限 | AIが誰の権限で何を読めるか | 見えてはいけない情報が検索しやすくなる |
| データ分類 | 個人情報、機密情報、顧客情報、契約情報をどう扱うか | AI利用の可否判断が都度属人化する |
| 最新性 | 古い文書、未承認文書、ドラフトをどう扱うか | 古い前提や未承認情報で判断する |
| ログ | 何を参照し、何を生成し、何を実行したか追えるか | 誤回答や過剰実行を後から検証できない |
| コスト | ユーザー課金、クレジット課金、API課金、エージェント実行回数を管理できるか | 業務に組み込んだ後に費用が読めなくなる |
| 停止手順 | 誤動作、情報漏えい、過剰実行時に止められるか | 便利なエージェントほど止めにくくなる |
これは、AIに個人情報を入れてはいけない、で思考停止していないかでも書いた話につながります。AIを禁止するか許可するかだけではなく、どのサービスに、どの契約で、どの用途で、どのデータを、どの管理策とセットで使うかを決める必要があります。
コストも重要です。AIエージェントが増えると、利用量は人間のチャット回数だけでは測れなくなります。スケジュール実行、トリガー実行、ツール呼び出し、検索、推論、外部API呼び出しが積み上がります。AIが安く使える時代は長くは続かないでも書いたように、AIのコストは「今安いから大丈夫」ではなく、業務に組み込んだ後の継続費用として見たほうがよいです。
入口別に見る業務コンテキストの置き場
入口を選ぶときは、AI機能の有無だけでなく、自社の意味づけと業務コンテキストがどこに自然に残るかを見ます。
| 組織の状態 | 第一候補 | 見るべき強み | 注意点 |
|---|---|---|---|
| Microsoft 365中心 | Microsoft 365 Copilot / Work IQ | メール、予定、会議、ファイル、人、チャット、権限、ログが同じテナントにある | 既存の権限設計が荒いと問題も見えやすくなる |
| Google Workspace + Slack + Notionに文書やタスクが集まっている | Notion AI + Notion | 文書、議事録、DB、タスク、外部コネクタをNotionに集めやすい | 重要な業務データがNotion外に多いと限界がある |
| Jira / Confluence中心 | Atlassian Rovo / Teamwork Graph | チケット、仕様、問い合わせ、開発文脈をつなぎやすい | 非Atlassian領域との接続設計が必要 |
| SaaSがばらばら | Azure OpenAI / Bedrock / MCP / 社内検索基盤 | 横断接続や個別要件に合わせやすい | 権限、ログ、分類、最新性、費用管理を自社で設計する |
| 機密性が非常に高い | 個別設計 / 閉域 / 限定用途 | 要件に合わせて範囲を絞れる | SaaS内蔵AIだけでは要件を満たせない可能性がある |
Microsoft 365中心ならWork IQ / Copilotに寄せるのが自然
Microsoft 365中心の会社では、業務コンテキストのかなりの部分がMicrosoft 365側にあります。メールはOutlook、予定はExchange / Outlook、会議はTeams、ファイルはSharePoint / OneDrive、チャットはTeams、IDはMicrosoft Entra IDにある。こういう会社では、AIのために文脈を集め直すコストを下げやすくなります。
Microsoft 365 Copilotのアーキテクチャ説明では、CopilotはMicrosoft 365 service boundary内で動作し、Microsoft Graphにアクセスしてgroundingを行うと説明されています。ただし、Copilotがテナント全体を無制限に見られるわけではなく、アクセスはサインインしているユーザーの権限にスコープされます。
たとえば「来週のA社定例の準備」をする場合、予定はOutlook、会議はTeams、資料はSharePoint、関係者はEntra ID、過去のやり取りはTeamsやメールにあります。AIのために別々のSaaSから集め直す部分が少ないほど、接続、権限同期、ログ確認の運用コストを下げやすくなります。
さらに、Microsoftは2026年6月2日にWork IQ APIsを発表しています。2026年6月7日時点では、一般提供は2026年6月16日予定です。公開情報ベースでは、Work IQはメール、予定、会議、チャット、ファイル、人、コラボレーションパターン、業務システムから、組織がどう動いているかの意味理解を作るものとして説明されています。
Work IQ APIsは、Chat、Context、Tools、Workspacesの領域を持ちます。これは、AIが「検索して答える」段階から、「業務文脈を理解し、必要な道具を使い、途中状態を持ちながら作業する」段階へ移っていることを示しています。
もちろん、Microsoft 365 Copilotが現場のすべての作業に最適とは限りません。ライセンス費用やユーザーごとの使い勝手は別に評価が必要です。また、Microsoft 365側の権限設計が荒い場合、AI導入によって「見えてはいけない情報が検索しやすくなる」問題が表面化します。SharePoint、Teams、OneDrive、メール、グループ、外部共有、ゲスト、秘密度ラベル、監査ログは、Copilot導入前に見直したほうがよいです。
Google Workspace + Slack + Notionなら、Notionも自然な入口になる
Google Workspace + Slack + Notionのような構成の会社では、Notionも自然な入口になります。理由は、Notionが文書、データベース、プロジェクト、議事録、ナレッジ、簡単なワークフローを同じ場所に寄せやすいからです。
Notion AIは、Notion Agent、Custom Agents、AI Meeting Notes、Enterprise Search(Beta)などを、Notionのワークスペースや接続アプリの文脈と組み合わせて使う方向に進んでいます。Notion AI Connectorsを使えば、Slack、Google Drive、GitHubなど外部アプリの情報も検索対象にできます。
たとえばNotionにプロジェクトDB、議事録、意思決定ログ、タスクが集まっている会社なら、「このプロジェクトの遅延理由を整理して」と聞いたときに、AIはページ単体ではなく、関連する会議、担当者、未完了タスク、過去の判断をたどりやすくなります。
もう少し業務寄りに見ると、Notion DBにSaaS導入相談や社内問い合わせが入り、Custom AgentがNotion内の社内ルールや過去事例を読み、Notion Workersのtoolが決まった計算や検証を行い、分類、返信案、Next Actionを返す、という形が考えられます。Notion Workersは、Notionを拡張するNode/TypeScriptプログラムで、外部データ同期、Custom Agentsが呼べるtools、Webhook受信に使えるものとして説明されています。
この例で大事なのは、NotionフォームやDBが入口で、Custom AgentがNotion内の文脈を読み、WorkersがAIに任せたくない確定処理を担当する、という分担です。これをNotionの外で組むなら、Notionの情報を別途RAG化し、権限と最新性を保ち、Notion APIやMCPで検索し、別のAI APIで推論し、Notion APIで書き戻す構成になります。もちろん作れますが、Notionに業務コンテキストが集まっているなら、まずNotion上でAIを動かせないかを見る方が自然です。
もちろん限界もあります。Notionのコネクタは、公式ヘルプでも情報検索や要約に向いており、複雑な計算やデータ分析のためのものではないと説明されています。また、接続設定にはNotionワークスペースオーナー権限と接続先アプリ側の管理権限が必要です。
価格や管理面も見なければいけません。Notionのpricingページでは、Notion AIはBusiness / Enterprise向けに位置づけられ、Custom AgentsはNotion creditsを使う形で説明されています。EnterpriseではLLM providersのzero data retention、SCIM、監査ログ、DLP/SIEM連携なども説明されています。
つまり、Notion AIは「Notionに情報が集まっている会社」ではかなり自然です。逆に、重要な業務コンテキストがNotionにほとんど存在しない会社で、Notion AIだけを入れても効果は限定的です。
Jira / Confluence中心ならAtlassian Rovoも候補になる
Jira、Confluence、Jira Service Management、Loomなどを業務の中心にしている会社では、Atlassian Rovoも候補になります。
Rovoの公式ページでは、チーム、仕事、アプリを横断してコンテキストを引き出し、判断やワークフローを支援するAIとして説明されています。さらにTeamwork Graphは、Atlassian Cloud Platformのdata intelligence layerとして説明され、Jira、Confluence、JSM、Loom、接続されたサードパーティツールの情報をつなげる役割を持っています。
Atlassian中心の会社では、JiraのIssue、Confluenceの仕様書や手順書、Jira Service Managementの問い合わせ、プロジェクトやチームの文脈が自然に残ります。Rovoは「AIチャットを追加する」よりも、「チケット、ナレッジ、プロジェクト文脈をAIが扱えるようにする」選択肢として見たほうがよいです。
Atlassianのサポートドキュメントでも、Rovo SearchはJiraやConfluenceなどのAtlassianアプリと、Google DriveやSlackのような接続アプリの結果を組み合わせると説明されています。同じページでは、Rovoがユーザー権限を尊重し、ユーザーがすでにアクセスできるものだけを見られると説明されています。
また、Teamwork Graph connectorの権限同期では、接続先のサードパーティアプリで制限されたデータは、そのアプリ側でアクセス権を持つユーザーだけがRovoで見たり使ったりできると説明されています。
ここでも論点は同じです。AIに何を接続できるかだけでなく、どの権限で、どの業務文脈として扱うかが重要になります。
SaaSがばらばらなら、内製・接続基盤は責任分界から考える
現実には、すべてがNotion、Microsoft 365、Atlassianのどれかにきれいに寄っている会社ばかりではありません。Google Workspace、Slack、Notion、Asana、Jira、Box、Salesforce、HubSpot、GitHub、Zendesk、ServiceNow、自社DB、DWH、BI、社内ポータル、各部門SaaSが混在している会社も多いはずです。
この場合、特定SaaSのAIだけで全体最適を狙うのは難しくなります。Azure OpenAI、Amazon Bedrock、MCP、社内検索基盤、データ基盤などを組み合わせて、必要な業務コンテキストをAIに渡す発想が必要になります。
ただし、内製すれば自由になるわけではありません。むしろ、自由度が高いほど責任も増えます。
ばらばらなSaaSで難しいのは、データが分散していること自体ではありません。権限、最新性、意味づけ、ログ、コストの責任も分散していることです。
たとえば、Slackの会話、Notionの議事録、Jiraのチケット、Salesforceの商談、Boxの契約書を横断してAIに渡すとします。このとき、AIは単に検索結果を集めればよいわけではありません。Slackの会話は誰が見られるのか。Notionの議事録は正式な決定なのか、下書きなのか。Jiraのステータスは業務上どの状態を意味するのか。Salesforceの商談金額は最新なのか。Boxの契約書は誰に見せてよいのか。参照履歴をどこで監査し、APIやエージェント実行のコストを誰が見るのか。
この設計を自社で引き受けるなら、内製基盤は強い選択肢です。逆に、そこまで運用できないなら、Microsoft 365、Notion、Atlassianのように、業務の発生場所とAIの文脈利用が近いプラットフォームへ寄せるほうが現実的です。
Azure AI SearchのRAG解説では、RAGの課題として、クエリ理解、複数データソースアクセス、トークン制約、応答時間、セキュリティとガバナンスが挙げられています。特にセキュリティでは、ユーザーやエージェントが認可されたコンテンツだけを取得できるように、細かなアクセス制御が必要だと説明されています。
Amazon Bedrock Knowledge Basesでも、RetrieveAndGenerate APIはナレッジベースから取得した情報をcontext informationとしてプロンプトに追加し、LLMの回答を生成すると説明されています。つまり、内製基盤でもやっていることは、AIに必要な情報を探し、整え、権限を見て、コンテキストとして渡すことです。
Model Context Protocolのアーキテクチャでは、サーバーがtools、resources、promptsなどのcapabilitiesを公開し、AIアプリケーションが接続されたサーバーの機能を使う構造が説明されています。MCPは、AIと外部ツールやデータソースをつなぐうえで便利です。ただし、MCPを足せば業務コンテキストが自動的に整うわけではありません。どのMCPサーバーを許可するか、どの権限で動かすか、どのデータを読ませるか、ログをどう取るかを設計しないと、AIエージェントの攻撃面が広がります。
このあたりは、弊社ブログのAnthropicが発表したゼロトラスト「Zero Trust for AI agents」解説でも整理しています。AIエージェント、MCP、ツール、権限、ログは、AI活用の便利さと同時に管理すべき対象です。
FAQ
AIに社内データを接続すれば十分ですか
十分ではありません。社内データへアクセスできても、AIが業務の目的、優先順位、関係者、過去経緯、制約を理解できなければ、実務に合う回答にはなりにくいです。データ接続は入口であり、出力品質を左右するのは意味づけとコンテキスト設計です。
Notion AIとMicrosoft 365 Copilotはどう使い分ければよいですか
自社の業務コンテキストがどこにあるかで考えるのがよいです。文書、議事録、タスク、プロジェクトDBがNotionに集まっているならNotion AIは自然です。メール、会議、ファイル、Teams、SharePoint、OneDrive、Entra IDが中心ならMicrosoft 365 Copilot / Work IQが自然です。
バラバラなSaaSを使う会社はどうすればよいですか
まず、全社一括ではなく1つの業務フローを選んで棚卸しするのがよいです。たとえば会議準備、問い合わせ対応、契約レビュー、インシデント対応などです。そのうえで、必要な文書、会議、タスク、権限、最新性、ログ、コストがどこにあるかを確認します。Azure OpenAI、Amazon Bedrock、MCP、社内検索基盤、データ基盤を使う場合は、その責任を自社で設計する範囲が広がります。
AIに業務コンテキストを渡すときのリスクは何ですか
主なリスクは、過剰な情報参照、権限設計の不備、古い情報の利用、機密情報や個人情報の扱い、操作ログ不足、コストの暴走です。AIに便利な文脈を渡すほど、ガバナンスも同時に強くする必要があります。
まとめ
AI導入の本質は、モデル選定だけではありません。
もちろんモデルは重要です。けれど、業務でAIを使うなら、成果を左右するのは、モデルに何をどう渡すかです。
社内文書、会議、タスク、プロジェクト、問い合わせ、意思決定ログ。これらが散らばり、権限も曖昧で、最新性も分からず、判断基準も残っていない状態では、AIは強い味方になりにくいです。
逆に、業務コンテキストが整っている会社では、AIは単なる文章生成ツールではなくなります。検索し、要約し、関係者を見つけ、過去の判断を参照し、次のアクションを提案し、場合によっては承認された範囲で実行する存在になります。
入口は一つではありません。Microsoft 365でも、Notionでも、Atlassianでも、内製基盤でもよいです。ただし、どの入口を選んでも、最後に見るべきものは同じです。
AIに渡せる業務コンテキストを整えること。
すでに特定の業務基盤にコンテキストが濃く残っているなら、まずはその場所でAIを動かせないかを考える。横断要件や高度な制御が必要なら、RAG、MCP、API連携、内製エージェント基盤を検討する。この順番で見ると、AI導入は製品比較ではなく、業務コンテキストの置き場と実行場所を決める話になります。
AI導入を始めるなら、まず全社の棚卸しから始めなくてもよいと思います。会議準備、問い合わせ対応、契約レビュー、インシデント対応など、1つの業務フローを選ぶ。そこに必要な文書、会議、タスク、判断基準、権限、最新性、ログ、コストがどこにあるかを書き出す。
その小さな棚卸しをすると、自社のAI導入で本当に足りないものが見えてきます。モデルなのか、検索なのか、権限なのか、ログなのか。それとも、そもそも業務コンテキストが残る働き方になっていないのか。