どうもおかしんです。
今日は「ChatGPTやClaudeに個人情報や機密情報を入れてよいのか」という話をします。
この問い自体は、最近よく見かけるようになりました。会社で生成AIを使いたい。けれど、個人情報を入れてよいのか分からない。顧客情報や契約書、ソースコード、社内資料を入れてよいのか分からない。だから、とりあえず「個人情報や機密情報はAIに入れないでください」というルールになる。
気持ちは分かります。雑に使えば危ないですし、個人向けアカウントに何でも入れてよいとは私も思っていません。
ただ、その議論が「AIだからダメ」で止まっているなら、それは少しおかしいと思っています。
なぜなら、これはAIだけの話ではないからです。
私たちはすでに、Google Workspace、Microsoft 365、Box、Salesforce、Slack、AWS、Azure、Google Cloud、GitHubなど、他社が運営するサービスやプラットフォームの上で日々の業務をしています。そこにはメール、顧客情報、契約書、ソースコード、議事録、設計資料、問い合わせ履歴、ログや設定情報まで載っています。
それなのに、AIだけを取り出して「個人情報を入れてはいけない」と言うなら、なぜGmailでは個人情報を送受信してよいのか、なぜBoxには契約書を置いてよいのか、なぜGitHubにはソースコードを置いてよいのか、という説明が必要になります。
この記事で言いたいことは、AIに何でも入力してよい、という話ではありません。
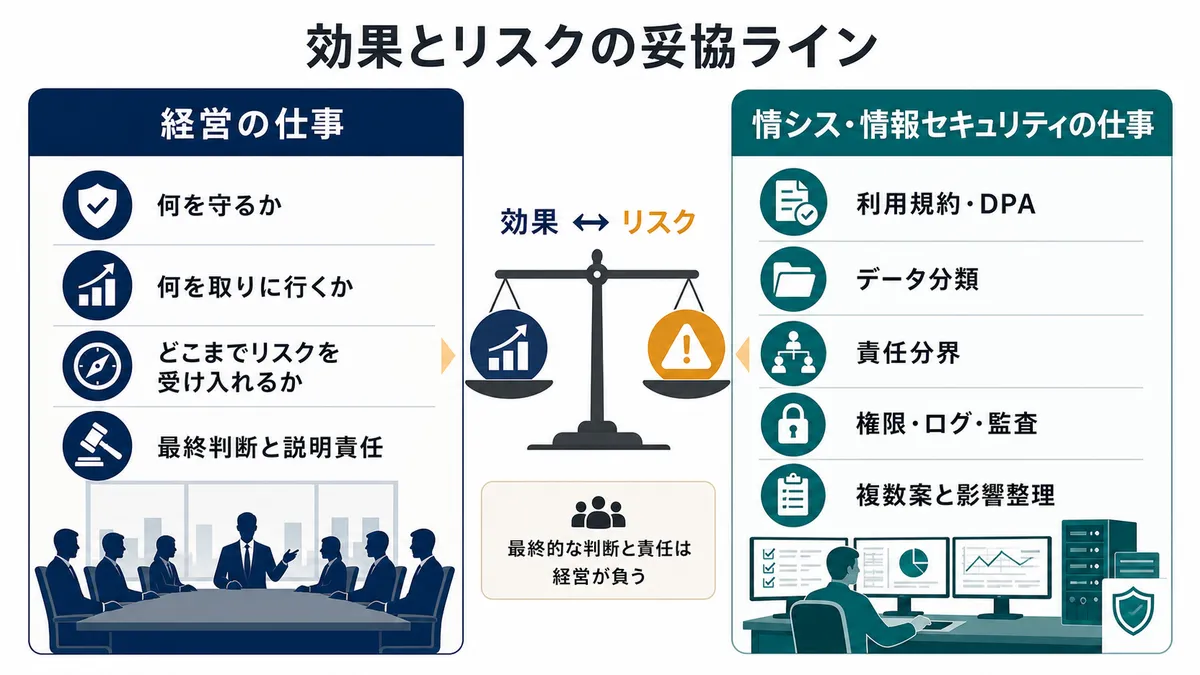
本来考えるべきなのは、AIかどうかではなく、どの業務を、どの外部サービスに、どの契約・責任分界・統制のもとで任せるのかということです。
そして最終的には、そこで得られる効果と受け入れるリスクを天秤にかけて、どこに妥協ラインを引くのかを経営として決める必要があります。
外部サービスは事業を強くするために使う
企業がIaaS、PaaS、SaaSを使う理由は単純です。適切に選定・設定・運用できれば、自社で全部作るよりも速く、安全に、安く、スケールしやすく、専門性の高い機能を使えるからです。
Gmailを使う。Microsoft 365で社内文書を共同編集する。Boxにファイルを置く。Salesforceで顧客管理をする。AWSやAzureでサービスを動かす。GitHubにコードを置く。これらはすべて、業務プロセスの一部を他社の基盤に委ねる判断です。
もし「機密情報を外部サービスに置いてはいけない」と本気で言うなら、クラウドもSaaSもほとんど使えません。フォームで受け付けた名前をスプレッドシートに保存することも、契約書をクラウドストレージで共有することも、顧客とのメールをGmailで送受信することもできなくなります。
でも実際には、多くの企業がそれらを使っています。なぜなら、業務データを置き、処理し、共有し、検索し、活用するために、そのツールを導入しているからです。
データを入れられないITツールには、ほとんど意味がありません。もちろん、何でも入れてよいという意味ではありません。許可された目的、データ分類、契約、統制の範囲で業務データを扱えるからこそ、ITツールには価値があります。
だから論点は、「外部サービスにデータを置くかどうか」ではありません。
論点は、どのデータと業務を、どの条件なら外部サービスに任せられるかです。
セキュリティは「禁止」ではなく「効果とリスクの設計」である
正しい情報セキュリティとは、リスクをゼロにすることではありません。事業効果を得ながら、リスクを許容可能な水準に下げるためにあります。リスクをゼロに近づけた結果、得られる事業効果が減損したり限定的になったりするのは本末転倒です。
もちろん、ミッションクリティカルな領域ではリスクを高く見積もる必要があります。金融、医療、社会インフラ、行政、生命や財産に直結する業務では、一般企業よりも厳しく見るべきです。調査が終わるまで暫定的に禁止する、という判断もあり得ます。
ただし、それは「何も考えずに永久に禁止する」ということではありません。
リスクがあるから禁止、ではなく、得られる効果と受け入れるリスクを見て判断する。業務価値、データの重要度、契約、責任分界、統制、監査、障害時対応、退出戦略を見て、使うか使わないかを決める。
これが本来のセキュリティやガバナンスの考え方だと思っています。
この考え方は、AIに限った話ではありません。NIST Cybersecurity Framework 2.0の公開発表でも、サイバーセキュリティは財務や評判などと並ぶエンタープライズリスクとして扱うべきものだと説明されています。つまり、セキュリティは現場の禁止リストではなく、組織として意思決定するための経営・ガバナンスの論点です。
そして、禁止には禁止のリスクがあります。
会社として正規の利用経路を用意しなければ、従業員は個人アカウントや未承認サービスを使いやすくなります。AIであれば個人のChatGPTやClaude、クラウドストレージであれば個人のGoogle DriveやDropbox、チャットであれば未承認のツールに流れるかもしれません。
その結果、組織は利用実態を把握しづらくなります。テナント内のログ、監査、教育、DLPは効きにくくなり、CASBやSWGで検知できる場合があっても、正規利用より統制は限定されます。
一律禁止は、見かけ上は安全そうに見えます。けれど、実際にはシャドーITやシャドーAIを増やし、むしろ統制不能な状態を作ることがあります。
この「禁止だけでは統制にならない」という話は、弊社ブログのIPA「情報セキュリティ10大脅威 2026」をゼロトラスト目線で再解釈した記事でも触れています。
妥協ラインを決めるのは経営の仕事である
この記事で一番伝えたいのは、ここです。
AIに個人情報を入れてよいか、コネクタをどこまで許可するか、社内データをどこまでAIから参照できるようにするか。これらは単なる機能設定やセキュリティ設定の話ではありません。
得られる効果と、受け入れるリスクの妥協ラインをどこに引くかという、経営判断の話です。
たとえば、AIをGoogle Drive、Box、Slack、GitHub、Microsoft Graphなどに接続するとします。接続先を広げ、権限を広げ、読み書きできる範囲を広げれば、AIはかなり便利になります。社内資料を横断して探せる。過去の議事録から文脈を拾える。顧客対応の下書きが速くなる。コードやissueをまたいで調査できる。人間が探すよりも速く、広く、深く業務データを扱えるようになります。
一方で、それはリスクと背中合わせです。
権限設計が雑なままAIを接続すれば、本来は見えていても業務上ほとんど見ていなかった大量のデータを、AIが一気に横断するかもしれません。誤った共有設定、過剰なOAuthスコープ、外部送信、ログ不足、誤回答、意図しない機密情報の露出が問題になるかもしれません。
リスクを下げようと思えば、接続先を絞る、読み取り専用にする、社外秘データを除外する、人間承認を必須にする、エージェント実行を禁止する、といった対策ができます。ただし、そこまで絞れば、当然ながら得られる効果も小さくなります。
逆に、効果を最大化しようと思えば、接続先を広げ、検索範囲を広げ、業務フローへの書き込みや自動実行まで許可することになります。その場合、業務改善のインパクトは大きくなりますが、事故が起きたときの影響も大きくなります。
つまり、ここには常にトレードオフがあります。
「ここまでリスクを低減させるなら、得られる効果はこの程度にとどまる」
「逆に、得られる効果をここまで引き上げるなら、リスクはこの程度まで大きくなる」
この妥協ラインをどこに引くかを決めるのは、最終的には経営陣やリスクオーナーの仕事です。CIOやCISOがいるなら、彼らが経営責任の中で判断に関与するべきです。いないのであれば、CEOを含む経営陣が判断するべきです。
これくらいのリスクなら、得られる効果を取りに行って事業を大きくする方が重要だ。そう経営陣が判断したなら、その判断は経営の責任です。万が一事故が起きたとしても、それは経営として引き受けるべきリスクです。逆に、その判断によって事業が伸びたなら、リスクを取る判断が事業上の成果に結びついたといえます。ただし、事業成果が出たとしても、法令、契約、権利保護、説明責任を満たした範囲でリスクを受容できていたかは別途検証すべきです。その判断の妥当性は結果だけではなく、事前に定めたリスク許容度、統制、継続的な監視に照らして評価されるべきです。
何事も、ノーリスクで得られるものはありません。
だからこそ、経営は「何を守り、何を取りに行くのか」を決める必要があります。ITやセキュリティの議論を、現場の禁止リストで終わらせてはいけません。
情シス・情報セキュリティの仕事は判断材料を出すことである
では、情シスや情報セキュリティ担当部門の仕事は何でしょうか。
それは、経営に代わって事業リスクを勝手に決めることではありません。専門知識に基づいて、経営が判断できる材料を揃えることです。
サービスの利用規約、DPA、サブプロセッサ、データ保持、学習利用、管理者権限、監査ログ、OAuthスコープ、コネクタの接続範囲、DLPやCASBでできる制御、事故が起きたときの影響。こうした論点を読み解き、事業側が得たい効果と並べて説明する。
大事なのは、「危険です」や「問題ありません」で終わらせないことです。
「ここまで絞ればリスクは下がるが、現場で得られる効果は限定的になる」
「ここまで広げれば効果は大きくなるが、権限設計とログ監査を強化しないと危ない」
「このデータ分類までは標準ルールで許可できるが、この領域は個別承認にした方がよい」
こうした形で、経営が選べる選択肢に落とし込む。これが、ビジネスにおける情シス・情報セキュリティの大事な仕事だと思っています。
経営判断のために整理すべき材料
ここで、情報システムやセキュリティ担当部門が、経営に判断を仰ぐために整理すべき材料をまとめます。
細かいチェックリストを作る前に、まず次の形に落とし込むのがよいと思います。
1. 何を得たいのか
まず、得られる効果を言語化します。
- 開発速度を上げたい
- 提案書や顧客対応の品質を上げたい
- 社内ナレッジを探しやすくしたい
- 問い合わせ対応を速くしたい
- 情シスやバックオフィスの定型作業を減らしたい
- 人手不足を補いたい
ここが曖昧なままでは、リスクだけが目立ちます。何を良くしたいのか、どの業務にどれくらい効くのかを出す必要があります。
2. どこまで使わせると効果が出るのか
次に、効果を出すために必要な利用範囲を整理します。
- チャットだけでよいのか
- ファイルアップロードを許可するのか
- Google DriveやBoxなどのストレージに接続するのか
- SlackやTeamsに接続するのか
- GitHubやJiraなどの開発基盤に接続するのか
- 読み取りだけか、書き込みや自動実行まで許可するのか
ここを絞ればリスクは下がりますが、得られる効果も下がります。逆に広げれば、得られる効果は大きくなりますが、リスクも大きくなります。
3. そのとき何が起きると困るのか
次に、具体的なリスクを整理します。
- 個人情報や機密情報が外部に出る
- 本来見てほしくない社内データをAIが横断する
- 誤った回答が顧客対応や意思決定に使われる
- AIエージェントが誤って書き込みや外部送信をする
- ログが残らず、あとから説明できない
- 契約上、再委託や外部処理が認められていないデータを扱う
抽象的に「危ない」と言うのではなく、何が起きると困るのかを具体化する必要があります。
4. どこまでリスクを下げられるのか
次に、リスク低減策を整理します。
- 法人向けプランや商用条件を使う
- SSO、MFA、SCIMで組織管理する
- 入力禁止データを定義する
- コネクタの接続先を限定する
- OAuthスコープを絞る
- 読み取り専用から始める
- 社外送信や書き込み実行に人間承認を入れる
- 監査ログを残す
- CASB/SWG/DLPで未承認利用を検知する
- 例外承認フローを用意する
ここで重要なのは、対策を増やすほどリスクは下がりますが、スピードや使いやすさも下がることです。つまり、対策そのものにもコストがあります。
5. 最後に、どの案を選ぶのか
最後に、経営が選べる形にします。
たとえば、次のような並べ方です。
- 案A: チャットのみ許可。リスクは低いが、効果は限定的。
- 案B: 組織管理されたAIで、社内文書のアップロードまで許可。効果は中程度。個人情報や高機密情報は除外。
- 案C: Google DriveやBoxなどのコネクタを読み取り専用で許可。効果は大きいが、権限設計とログ監査が必須。
- 案D: エージェントの書き込みや外部送信まで許可。効果は最大化しやすいが、誤操作や情報漏えい時の影響も大きい。
こうして、効果とリスクを並べたうえで、どの案を選ぶのかを経営に判断してもらう。
これが本来のガイドライン策定だと思います。
判断材料を具体化する観点
ここから先の論点は、「やっぱり危ないから使わない方がよい」という話ではありません。効果を取りに行くために、情シス・情報セキュリティが経営へ渡す判断材料を具体化する話です。
サービスモデルごとに責任分界は変わる
外部サービスを評価するときは、まずサービスモデルを見る必要があります。
IaaS、PaaS、SaaSでは、自社とベンダーの責任分界が違います。AIサービスはこれらの提供形態にまたがりますが、そこにAI固有の責任分界も加わります。
たとえばIaaSで仮想マシンを使うなら、OS、ミドルウェア、ネットワーク設定、IAM、ログ、暗号化、脆弱性管理など、自社側で見るべき範囲が大きくなります。PaaSなら、基盤インフラやOS、ランタイムの一部はベンダーに任せられますが、アプリケーションのコードや設定、データ、接続設定、権限管理は自社の責任として残ります。
SaaSでは、基盤やアプリケーション運用の多くをベンダーに任せる一方で、契約、データ分類、テナント固有の設定、アクセス権、共有設定、監査ログ、DLP、保持設定などを見る必要があります。
AIサービスでは、そこにさらに、プロンプトやファイルがモデル学習に使われるか、入力や出力がどのくらい保持されるか、外部モデル提供者やサブプロセッサに何が渡るか、コネクタやエージェントがどこまで権限を持つか、といった論点が加わります。
AWSのShared Responsibility Modelや、Microsoftのクラウドにおける責任分担、Google Cloudのshared responsibility / shared fateの考え方を見ると分かる通り、クラウドでは「ベンダーが全部守る」わけでも「自社が全部抱える」わけでもありません。
英国NCSCのCloud security shared responsibility modelでも、クラウド利用はアウトソーシングと同じく、クラウド提供者と利用者の共同責任であり、サービスモデルによって責任範囲が変わると説明されています。特に、サービスが自社のセキュリティ要件を満たすか、どのデータを保存するか、どのように設定するかは利用者側の責任として残ります。
AIでも責任分界を見る必要があります。
どこまでがベンダー責任で、どこからが自社責任なのか。それを見ずに「AIだからダメ」と言っても、実務上はほとんど意味がありません。
本当に見るべき判断軸
AIに限らず、外部ITサービスに業務やデータを載せるときに、経営判断の材料として見るべき項目があります。
まず、事業効果です。
何が速くなるのか。何が安くなるのか。品質や顧客価値がどう上がるのか。人手不足をどう補えるのか。意思決定や開発や顧客対応がどう改善するのか。
ここを見ないままセキュリティだけで議論すると、だいたい禁止に寄ります。なぜなら、使わないことだけを考えれば、そのツール由来のリスクは発生しないからです。
でも、使わないことで失う事業効果もあります。競合がクラウドやSaaSやAIで業務を速くしている中で、自社だけが使えない。現場が使いたいのに正規ルートがない。結果として未承認利用が増える。これも事業上のリスクです。
次に、業務重要度とデータ分類です。
その業務が止まったら何が起きるのか。代替手段はあるのか。復旧目標はどうか。扱うデータは公開情報なのか、一般社内情報なのか、機密情報なのか、個人情報なのか、要配慮個人情報なのか、認証情報なのか。
そして、契約と規約です。
DPAはあるのか。利用規約はどうなっているのか。SLAはあるのか。サポートはどうか。サブプロセッサは誰か。サブプロセッサ変更通知はあるのか。契約終了時にデータは削除されるのか。データの所有権や二次利用はどう扱われるのか。
さらに、技術的・運用的な統制です。
SSO、SCIM、MFA、最小権限、管理者アクセス、共有設定、監査ログ、eDiscovery、SIEM連携、CASB/SWG、DLP、バックアップ、エクスポート、ベンダーロックイン、退出戦略。
こうしたものを見て初めて、「このサービスにこのデータを載せてよいか」「どこまでリスクを下げると効果が失われるか」「どこまで効果を取りに行くとリスクが増えるか」を経営に説明できます。
AIはこの大きな流れの中にある。ただし固有リスクがある
AIは外部サービス利用の一部です。けれど、従来のSaaSと完全に同じではありません。
AIにはAI固有の論点があります。
プロンプトやファイルがモデル学習に使われるのか。入力、出力、フィードバック、添付ファイル、会話履歴がどのくらい保持されるのか。API、チャットアプリ、コーディングエージェント、コネクタで条件は違うのか。外部モデル提供者やサブプロセッサへ何が渡るのか。Web検索や外部ツール連携で社外へ何が送信されるのか。
さらに、最近はAIがGoogle Drive、Box、Slack、GitHub、Microsoft Graphなどに接続するようになっています。そうなると、AIは単なるチャット画面ではありません。ユーザーの権限を引き継いで大量のデータを読み、場合によってはファイルを作り、チケットを更新し、コードを書き、外部へ送信するエージェントになります。
この場合、通常のSaaS利用よりも、権限、ログ、承認、実行範囲を細かく見る必要があります。
つまり、AIは「クラウドやSaaSと同じだから何でもよい」わけではありません。
ただし、「AIだから一律禁止」でもありません。
クラウドやSaaSと同じように責任分界と契約と統制を見つつ、AI固有のリスクも追加で見る。それが現実的な整理だと思います。
NIST AI Risk Management Frameworkも、AI製品・サービス・システムの設計、開発、利用、評価に信頼性の観点を組み込むためのリスク管理フレームワークです。さらにNISTは生成AI向けのProfileも公開しており、生成AI固有のリスクを識別し、組織の目的や優先順位に合わせて管理するための材料を示しています。ここでも、結論は「AIだから禁止」ではなく、リスクを識別、測定、管理することです。もちろん、許容できないリスクであれば停止や回避も選択肢になります。
「学習されない」と「保存されない」は違う
AIの話で特に混同されやすいのが、「学習されない」と「保存されない」です。
これはまったく別の話です。
モデルの学習に使われないとしても、プロンプトや出力が一定期間保存されることはあります。監査や不正利用検知、障害調査、eDiscovery、管理者監査のために保持されることもあります。
たとえばOpenAIのAPI data controlsでは、API endpointごとに保持条件が分かれています。多くのendpointではabuse monitoringログが最大30日保持され得ますが、endpointによっては保持なし、削除まで保持、削除後30日など扱いが異なります。Responses APIはデフォルトまたはstore=trueの場合にapplication stateが少なくとも30日保持されると説明されています。Assistants、threads、vector stores、filesなどは削除まで保持され得るものがあります。Zero Data RetentionやModified Abuse Monitoringもありますが、申請・承認制であり、すべての機能で自由に使えるわけではありません。
Anthropicの組織データ保持に関する説明でも、APIの入力・出力は原則30日以内に削除される一方で、ポリシー違反としてフラグされた入力・出力は最大2年、trust and safety分類スコアは最大7年、フィードバック関連データは5年保持され得るなどの例外があります。また、Claude for WorkやClaude Enterpriseなど、会話やcoding sessionを保存して継続利用する商用プロダクトでは、プロダクト体験のためにそれらが保持され、削除後にバックエンドから削除されるまでの期間もあります。
Microsoft 365 CopilotのEnterprise data protectionやCopilotのprivacy and protectionsでは、プロンプト、応答、Microsoft Graph経由のデータは基盤モデルの学習には使われないと説明されています。一方で、Copilotの対話データはMicrosoft 365サービス内に保存され、監査、eDiscovery、retention policyの対象になり得ます。
Box AIのFAQでは、Boxもモデル提供者もBoxから受け取ったデータを学習に使わず、Box AIのクエリや応答を保存しないと説明されています。一方で、活動ログは記録されます。また、Box AIには履歴を扱う機能もあるため、対象機能、設定、保持期間は個別に確認する必要があります。
だから、「学習に使われないから安全」と短絡してはいけません。
見るべきなのは、学習利用、保持、管理者アクセス、監査ログ、削除、サブプロセッサ、外部連携を含めた全体です。
主要AIサービスでは「学習利用しない」方向が見えるが、それだけでは足りない
公開日現在、この記事で確認した主要な法人向けAIサービスや商用条件を見ると、顧客データをモデル学習に使わない、または明示的なオプトインが必要、という説明が増えています。
たとえばOpenAIのEnterprise Privacyでは、ChatGPT Business、ChatGPT Enterprise、APIのビジネスデータを、明示的に共有しない限りモデル学習に使わないと説明されています。
AnthropicのCommercial Termsでも、Customer Contentをモデルの学習に使わないとされています。Claude Codeについても、Claude Codeのdata usageで、商用条件下のTeam、Enterprise、APIでは、顧客がモデル改善目的で明示的に提供する場合などを除き、コードやプロンプトを生成モデルの学習に使わないと説明されています。
Google WorkspaceのAI privacyページでは、Gmailなどを含むGoogle Workspaceの顧客データについて、許可なく人間がレビューしたり、顧客ドメイン外で生成AIモデルのトレーニングに使ったりしないと説明されています。
Microsoft 365 Copilotは、ユーザーが権限を持つMicrosoft 365データをMicrosoft Graph経由で参照し、テナント境界や既存権限を前提に動きます。プロンプトや応答、Microsoft Graph経由のデータは基盤モデルの学習に使われないと説明されています。
Box AIも、ユーザー権限のあるコンテンツだけを使い、Boxもモデル提供者もBoxから受け取ったデータを学習に使わないと説明しています。ただし、Boxのサブプロセッサ一覧やBox AIの対応モデルを見ると、AI/MLサブプロセッサや顧客が有効化するモデルの確認は必要です。
ここから言えるのは、「この記事で確認した主要な法人向けAIサービスでは、顧客データを勝手に学習利用しない方向が見える」ということです。
しかし、それは「何を入れても安全」という意味ではありません。
プラン、契約、設定、APIかアプリか、コネクタを使うか、エージェント実行をするか、管理者が何を見られるか、ログがどこまで残るかによって、判断は変わります。
ここで見ているのは、AI固有論点の例です。判断枠組み自体は、クラウドやSaaSと同じく、契約、責任分界、データ分類、保持、監査、管理者制御を確認することにあります。
データ分類と用途でルールを作る
では、どういうルールにすればよいのでしょうか。
私は、AIだけのルールではなく、クラウド、SaaS、AIを含む外部サービス利用全体のルールとして考えた方がよいと思っています。
たとえば、データ分類は次のように分けられます。
- 公開情報: 公開Web、公開資料、公開済みプレスリリース
- 一般社内情報: 社内手順、議事録、業務メモ
- 社外秘・機密情報: 提案書、設計資料、契約書、ソースコード
- 個人情報: 氏名、メールアドレス、問い合わせ履歴、顧客担当者情報
- 要配慮個人情報・高リスクデータ: 健康情報、法令上の要配慮個人情報、公平性上のセンシティブ属性、大量の顧客データベース
- 認証情報・秘密情報: パスワード、APIキー、秘密鍵
- 特別な高機密情報: 未公開M&A、インサイダー情報、再委託不可の顧客データ
公開情報であれば、多くのサービスで扱いやすいでしょう。一般社内情報も、組織管理されたサービスであれば許可しやすい。社外秘や機密情報は、契約、アクセス制御、ログ、保持、共有設定を確認したうえで条件付きにする。個人情報は、まず利用目的の範囲内かを確認する。個人データに該当する場合は、委託、第三者提供、外国第三者提供、保持、越境移転なども確認し、用途を限定する。
一方で、認証情報や秘密鍵は原則として入力禁止にすべきです。要配慮個人情報、大量個人データ、公平性上のセンシティブ属性を含む高リスクデータ、未公開M&A、インサイダー情報、再委託不可の顧客データなどは、原則禁止または個別承認にするべきです。
用途も分ける必要があります。
保存、処理、共有、検索、要約、翻訳、コード生成、顧客対応、外部送信、書き込み系エージェント実行ではリスクが違います。
社外へ出す回答、顧客対応、契約文面、書き込み系エージェント実行は、人間レビューや承認を必須にする。逆に、社内資料の要約や翻訳のような用途では、許可されたサービスとデータ分類の範囲内で使いやすくする。
そうやって、「許可サービス」「許可データ」「許可用途」「必要な管理策」を組み合わせて決めるべきです。
個人情報と機密情報は同じではない
個人情報と機密情報は、混ぜて考えない方がよいです。
個人情報には、利用目的、本人通知や公表、要配慮個人情報などの論点があります。さらに、個人データとして扱う場合には、委託、第三者提供、外国第三者提供、委託先監督などの論点が加わります。ここは個別事情によって変わるため、この記事では適法・違法を断定しません。法務確認の論点として扱うべきです。
個人情報保護委員会の生成AIサービスの利用に関する注意喚起でも、個人情報を含むプロンプトを入力する場合には利用目的の達成に必要な範囲かを確認し、本人同意なく個人データを入力して応答出力以外の目的で取り扱われる場合は法違反となる可能性があるため、機械学習利用などを確認するよう求めています。
また、個人情報保護委員会のクラウドサービス提供事業者向け注意喚起を見ると、クラウドサービス提供事業者が個人データを「取り扱う」のか、契約やアクセス制御上「取り扱わない」と整理できるのかによって、提供、委託、外国第三者提供の考え方が変わり得ることが分かります。取り扱わないと整理できる場合でも、自社の安全管理措置として契約条項やアクセス制御などの確認は残ります。
DPAがあるから終わり、ではありません。提供先国、体制整備、サブプロセッサ、継続的情報提供、委託先監督などを見る必要があります。
一方で、機密情報は別の観点です。
個人情報ではないから自由に外部サービスへ載せてよい、というわけではありません。契約上の守秘、営業秘密、顧客契約の再委託可否、未公開情報、認証情報、ソースコードなどの分類で見ます。
つまり、「個人情報かどうか」だけを見ても足りません。
データの種類、契約上の制約、業務上の重要度、漏えい時の影響を見て判断する必要があります。
エージェントとコネクタは別枠で考える
AIを語るうえで、通常のチャットとエージェントやコネクタは分けるべきです。
ChatGPTやClaudeにテキストを貼り付けて要約させるのと、AIがGoogle Drive、Box、GitHub、Slack、Microsoft Graphに接続し、ユーザー権限で検索し、ファイルを読み、チケットを更新し、コードを書き、外部へ送信するのでは、リスクが違います。
エージェントやコネクタでは、少なくとも次を見ます。
- 接続先SaaSの棚卸し
- OAuthスコープと管理者承認
- 読み取り専用か、書き込み可能か
- 最小権限になっているか
- 自動実行前に人間承認が必要か
- 社外送信前にレビューが入るか
- ツール実行ログが残るか
- 権限過多のデータを発見し、是正できるか
特に怖いのは、AIそのものよりも、AIに渡している権限です。
人間が本来見られないデータをAIが見てしまうのも問題ですが、人間が見られるものの、実際には普段見ていなかった大量のデータをAIが一気に横断してしまうことも問題になります。既存SaaS側の権限設計が雑なままAIコネクタを入れると、その雑さが一気に表面化します。
シャドーIT、シャドーAI対策は「禁止」だけでは足りない
外部サービス利用のルールを作るとき、一律禁止だけではうまくいきません。
未承認SaaSも、個人クラウドストレージも、個人ChatGPTも、禁止だけで消えるわけではありません。むしろ、業務上の必要があるのに正規の道がなければ、現場は勝手に道を作ります。
だから、やるべきことは「禁止」だけではありません。
許可されたサービスを整備する。SSOでログインさせる。CASBやSWGで未承認サービスを検知する。DLPで持ち出しを制御する。ログを残す。例外申請を用意する。違反時には罰するだけでなく、正規ルートへ誘導する。教育する。定期的に利用状況を見直す。
AIでも同じです。
個人アカウント利用を抑えたいなら、業務上の需要を確認し、会社として使えるAI、例外申請、代替手段、教育、検知の仕組みを用意する方が統制しやすくなります。使えるAIや代替手段を用意せずに「AIは禁止」とだけ言うのは、現場から見ると、業務改善の道を閉ざしているだけに見えます。
英国NCSCのSaaSを安全に利用するためのガイダンスでも、セキュリティのためにアプリケーションを過度にロックダウンすると、ユーザーがシャドーITへ流れる可能性があると説明されています。これはAIでも同じで、使える正規ルートと統制をセットで設計しないと、禁止はかえって統制不能を生みます。
関連記事のIPA 10大脅威 2026の記事では、AIリスクを「AIを悪用した攻撃」「AIを対象とする攻撃」「運用・法的リスク」に分けて整理しました。この分類は、今回の話にもそのまま使えます。未承認AIの利用は、運用・法的リスクであると同時に、ログや権限が効かないシャドーITの問題でもあります。
ガイドライン策定者は、まず一次情報を読んでほしい
AIに個人情報を入れてよいのか。
この問いに答える前に、まず一次情報を読んでほしいです。
利用規約、DPA、商用条件、プライバシー、セキュリティ資料、サブプロセッサ一覧、データ保持、管理者機能、監査ログ、学習利用、外部連携、リージョン、削除条件。
これらを読まずに「AIに個人情報を入れてはいけない」と決めるのは、セキュリティというより思考停止です。
もちろん、調査が終わるまで暫定的に止めることはあります。規制業種や高リスク業務で慎重に進めるのも当然です。
日本でも、経済産業省と総務省のAI事業者ガイドライン第1.2版では、AI利用者がAIシステム・サービスを利用する際、提供者からの情報を踏まえ、AIの性質、利用態様、便益、リスクを認識し、適正な範囲・方法で使うことが重要だと整理されています。ログ管理体制、利用中の定期的な確認、異常操作時の報告体制にも触れられており、ここでも一律禁止ではなく、リスクベースで利用条件と管理策を設計していく方向性と読めます。
ただし、永続的に禁止するにせよ許可するにせよ、少なくとも次の10項目は評価し、組織として決めるべきです。
- 許可するサービス
- 禁止するデータ
- 条件付きで許可するデータ
- 許可用途と禁止用途
- 必要な管理策
- 例外承認の流れ
- ログと保持条件
- コネクタやエージェントの承認
- 利用者教育
- 見直し頻度
これらを評価せず、決めるべきことを決めないまま「AIだからダメ」とだけ言うのは、Google WorkspaceやMicrosoft 365やBoxを使うときに本来やるべき判断を、AIのところだけ放棄しているように見えます。
そして、これらの評価と決定は、担当者が自分たちだけで抱え込むためのものではありません。経営に判断してもらうための材料です。
まとめ
AI利用の目的は、事業を強くすることです。
ただし、それはAIに限りません。IaaS、PaaS、SaaS、AIを含む外部サービスは、業務とデータを他社の基盤に載せることで、事業を強くするための選択肢です。
個人情報や機密情報を扱うなら慎重であるべきです。そこは間違いありません。
でも、慎重であることと、一律禁止は違います。
禁止するにも、許可するにも、事業効果、データ分類、契約、責任分界、統制、監査、退出戦略を見て、説明できるルールにするべきです。
そのうえで、どこまでリスクを下げ、どこまで効果を取りに行くかを経営として決めるべきです。
AIに個人情報を入れてはいけない、で思考停止していないか。
この問いは、AIの話であると同時に、企業が外部サービスやプラットフォームに業務を載せるとはどういうことか、という問いでもあります。
だからこそ、AIだけを特別扱いするのではなく、クラウド、SaaS、AIを含めて、リスクベースで考えた方がよいと思っています。
AIガイドライン策定やAI活用支援について
クラウドネイティブでは、生成AIの業務利用、AIガイドライン策定、SaaSやクラウドの統制設計を支援しています。
AIを禁止するのではなく、事業効果とリスクの両方を見ながら、組織として使える状態にしたい場合は、AI活用支援をご覧いただくか、お問い合わせください。
関連記事
AIガイドラインを「禁止」で終わらせず、データ分類・契約・コネクタ権限まで具体化したい方は、次の記事も判断材料になります。
- Box AIは本当に「閉域」か|Copilot・Geminiとの三者比較で社内ルールを設計する:本記事の「学習されない」と「保存されない」は違うという論点を、Box AI・Copilot・Geminiの実条件で突き合わせ、社内ルールに落とし込む実例です。
- Notion AIでAnthropicモデルが一時無効化された件を整理する:SaaSに組み込まれたAIが依存する外部モデル提供者・サブプロセッサのリスクを、実際に起きた可用性インシデントで具体的に理解できます。
- Microsoft 365 CopilotのCopilot CoworkでClaude Fable 5を利用する方法と注意点:本記事で挙げたMicrosoft 365 Copilotや外部モデル提供者への論点を、M365 Copilot上で外部モデル(Claude)を使う新機能とその注意点という製品レベルの具体例で確認できます。
- AI時代の業務基盤は、モデルではなく『AIに渡せる業務コンテキスト』で決まる:コネクタや権限を「どこまで広げると効果が出るか」を決める前提として、AIに渡す業務コンテキストの設計から考えたい読者向けの一本です。