シンジです。無料で遊べるワークフローツールn8nで遊んでいます。「会社ブログが公開されたらAIが要約してSNSに告知してくれるやつ」とか、「YouTube動画が公開されたら動画を要約してSNSに告知してくれるやつ」とか、そんな小ネタな自動ツールから作成し始めました。その次に作ったのは、「会社の代表電話に迷惑電話(営業電話含む)がかかってきたら、AIが判断して着信拒否してくれるやつ」とかも作りました。もちろん全て生成AIで。しかしなんとも小粒な自動化ばかりでn8nを活用している感じがあまりしなかったので、自身のSNSでn8nの活用方法を募集したところ、なかなか面白い実例を教えてもらいました。
退勤時に日報を書くとプロジェクトの工数評価をするn8nワークフロー

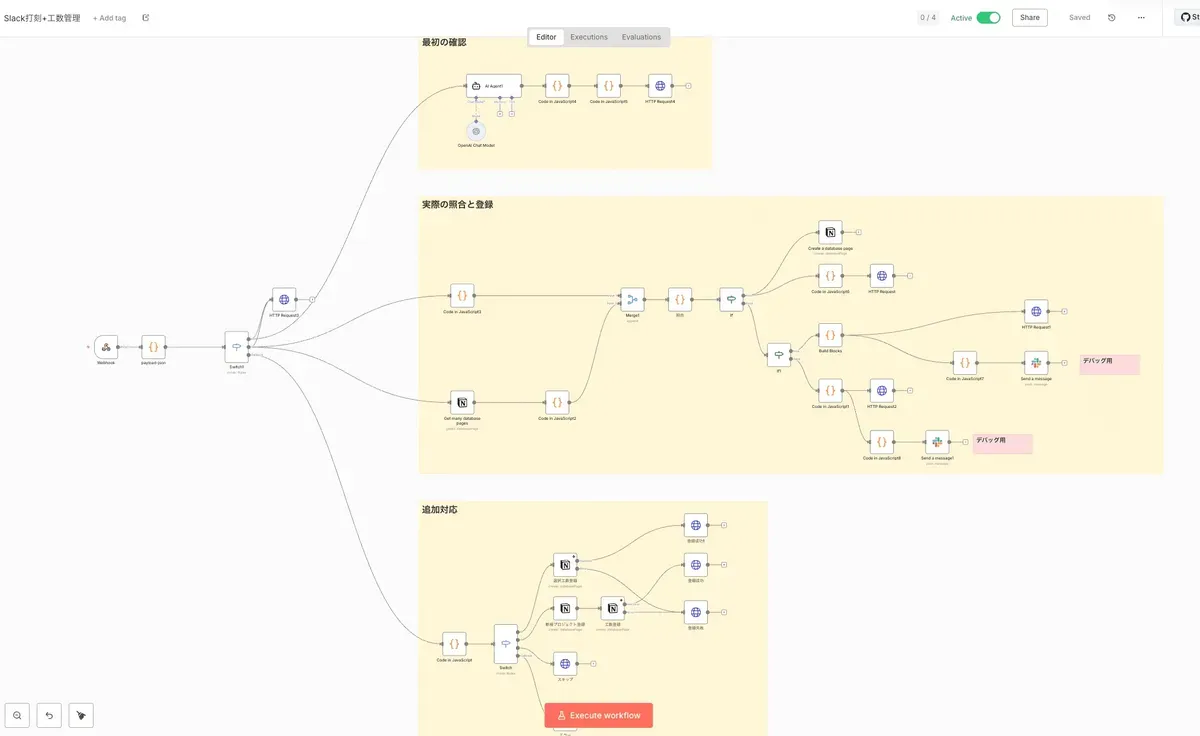
いやこれなかなかおもろいやん!ということで、これにインスピレーションを受けまして、思いつきました。
「退勤後に社員全員の活動履歴を取れるだけのSaaS全部から取得して、AIに投げて業務分析させて、出勤前に前日の1日を振り返って、今日やることを教えてくれるやつ」
を、n8nで作ろうと思ったわけです。やってから気づきましたが、これはもはやn8nではなく、AWS Lambdaとかでやった方がいいですね。
ちなみに某社はn8nで枯れてきたワークフローを、n8nから外してGo言語で書き直して別で動かしてるらしいです。なるほどかしこい。やったから分かるこの賢さ。
というわけでできました
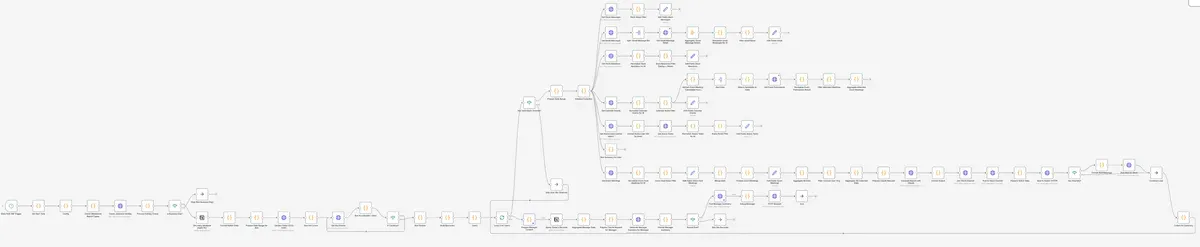
バカでか巨大ワークフローになりました。ここまで巨大になると、n8nでやる必要があるのか甚だ疑問ですが、n8nがおもろいので思わず進めてしまいました。この記事では、最初にこのワークフローの流れを書いて、後半でn8nのおもしろポイント苦労ポイントを書いていこうと思います。
トリガーは毎晩深夜1時に発動
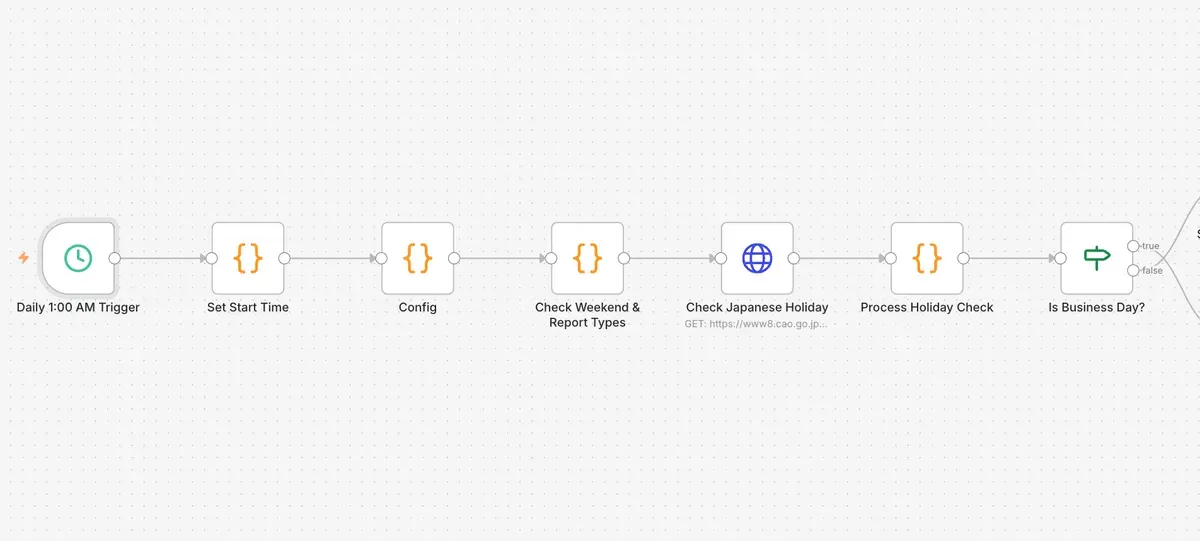
翌朝までに処理が間に合えば何時に開始したっていいんですが、とりあえず深夜1時にしました。処理が発動した時間から過去24時間を処理対象にします。結果的にこの処理、全員分終わるのに24分くらいかかります。最適化する前は6時間とかかかってました。というか、永久に終わらないモードも経験しました(n8nのメモリ不足など)。後半で最適化の話をしています。(書いてる最中にAM2時にしました)(なんとなくです)
土日祝日が会社のお休みなので、内閣府のWebから祝日のcsvをダウンロードして、処理対象日が営業日なのかどうかを判断します。この処理も年1回でいいんですが、まぁいいでしょう。毎回ダウンロードせずに保存したcsvを参照させればいいだけなんですが、瞬殺で処理が終わるのでよしとします。というか、内閣府からCSV持ってきましょうってAIが言ってるのがおもしろくて。
対象ユーザーの詳細情報を取得する

Notionのデータベースページに対象ユーザーの一覧が記載されています。このユーザー一覧を作成するノードも最初はあったのですが、弊社の場合そんなしょっちゅう入退社がなくあまり更新しないので、別で切り出しました。
続いてさっそく、Boxのデータを取りに行くフローがあるのですが、本来の理想的な流れは、「対象ユーザー1人を絞る」→「1人分のクラウドの活動履歴を取りたい」わけですが、Boxに限っては1人分だけとるということが仕様上できなかったので、先に全イベントを取得しておいて、取得したデータから1人分だけを抽出するという流れになっています。これもAIの指示通りです。
従業員全員分のデータとったら1人ずつ処理する
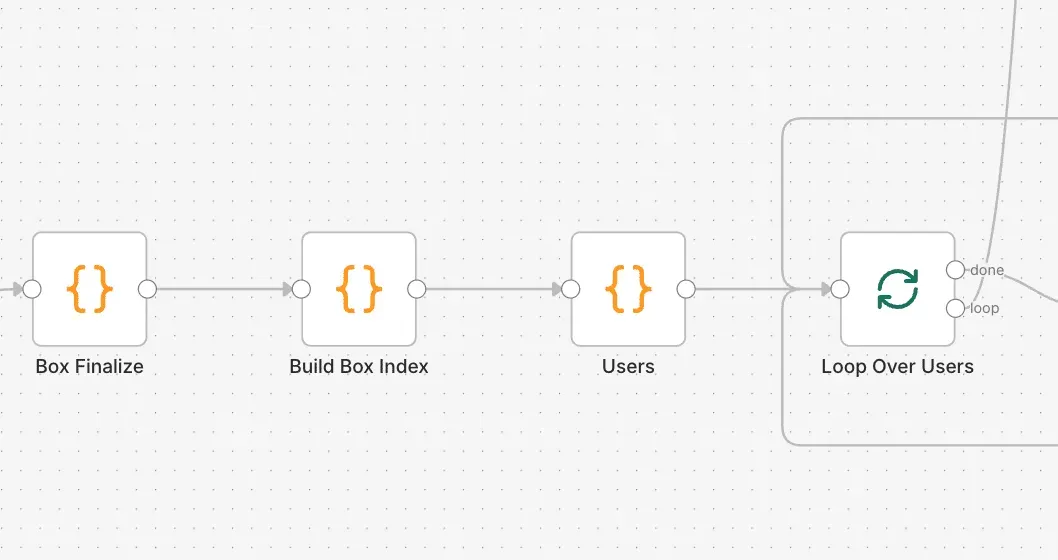
Loopノードに入ると、全員分の処理が終わるまでひたすらループ処理します。
クラウドサービスの活動履歴を取得する
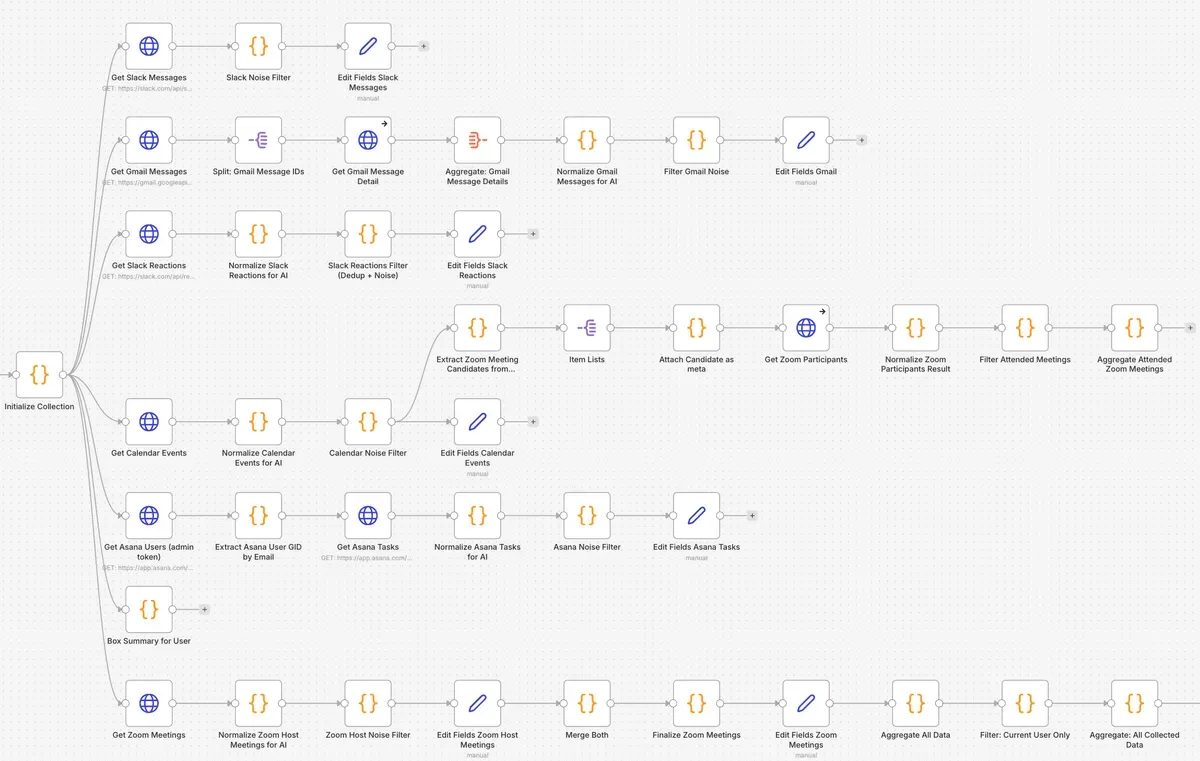
クラウドサービスといってもたくさんありましてですね、どこのなんのデータを取るかということなのですが、これも生成AIに聞いたところ、目的に沿うようなデータが取れるのはこれだよということで、Slack(投稿とリアクション)、Gmail、Google カレンダー、Asana、Box、Zoomのデータを取ることになりました。Notionとか他のSaaSの活動履歴も取りたかったのですが、そもそもそんな履歴をSaaS側が取ってないとか、APIがないとかで、結果的にここまで絞られました。それでも結構な情報量があります。
SlackやGmailなどのテキスト中心のデータは、ノイズが混ざります。相づち打ってたり、Gmailでは広告メールとか営業メールとかが混ざります。これをフィルタリングして処理するノードも追加しています。
Slackについてはプライベートチャンネルのデータも取得していることに加えて、Gmailも各個人が何を書いてるのか分からんので、個人情報や機微情報がAIに渡されないように、これらのデータがあった場合はそぎ落としてから次のノードに渡す処理も加えています。
なんだかシンジ、いろいろ考えて設計しているやん、といった空気があるかもしれませんが、生成AIがそうしようと言ってきたのをそのままコピペしてるだけです。わたし何も考えていません。
画像では一番下のZoom処理のところだけ後半まで繋がっていますが、ほかは途中で切れてます。これは、処理だけしてデータを後から参照する形にしているからです。線を繋ぐとまともに動かなくなります。
n8nでは1つのノードから複数の線を出力で伸ばすと、どの順番で処理されるかがマジで謎なので、いろいろやった結果、Zoomの処理が一番最後になっていたので、結果的にそうなっただけです。
取得したデータ全部まとめた後に生成AI向けに作り直す
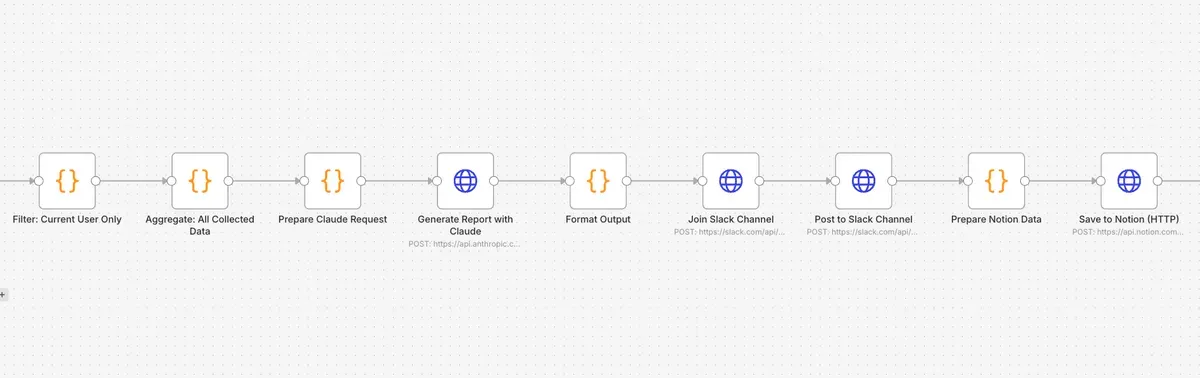
Claudeを使って全アクティビティに加えてプロンプトを投げて、その結果をSlack投稿用に成形してSlackに投げています。途中でその結果をNotionに記録していますが、元々このNotionの記録から週報と月報も作ろうとしていたのですが、Claudeに投げるデータがでかすぎるのと、日々の指示に加えて毎週のサマリーを出されても、なんかこうピンとこなかったので削除しました。現在はこのNotionのデータは、後半で処理するマネージャー向けサマリーの生成用データになります。
ここで投げているプロンプトはこんな感じです(もちろんこれも生成AIが作成しています)
あなたは業務分析アシスタントです。以下の入力データ「のみ」を根拠に、日次レポートを生成してください。
# 重要ルール(厳守)
- 入力に無い事実は作らない。推測が必要な場合は「仮説」と明記し、根拠(どの入力に基づくか)を1行で添える。
- 数値は入力値をそのまま使う。合算する場合は「算出式」を明記する。
- 個人情報・機微情報(メール本文・添付・Boxのフルパス等)は出力しない。必要なら「概要」へ丸める。
## 対象者情報
- 名前: ${data?.display_name || "不明"}
- 対象日(JST): ${data?.targetDate || "不明"}
## メトリクス(事実)
- Slack: メッセージ ${data?.metrics?.slackMessages || 0} / リアクション ${data?.metrics?.slackReactions || 0}
- Gmail: メール ${data?.metrics?.emails || 0}
- Calendar: 会議 ${data?.metrics?.meetings || 0}(${data?.metrics?.meetingHours || 0}時間)
- Zoom: 会議 ${data?.metrics?.zoomMeetings || 0}(${data?.metrics?.zoomHours || 0}時間)
- Asana: タスク ${(data?.metrics?.asanaCompletedTasks || 0) + (data?.metrics?.asanaActiveTasks || 0)}(完了 ${data?.metrics?.asanaCompletedTasks || 0})
- Box: 操作 ${data?.metrics?.boxEvents || 0}
## プロジェクト
${projectNamesArray.join(", ") || "未分類"}
## 工数(入力値)
- Asana見積: ${data?.metrics?.asanaEstimatedHours || 0}時間
- 推定実工数: ${data?.metrics?.meetingHours || 0}時間(会議時間のみ。他の作業時間は不明)
※推定実工数の内訳や算出式が不明な場合は「不明」と書くこと(勝手に補完しない)。
## 詳細(要約用素材)
### Slackメッセージ(最新10件)
${slackSummary}
### カレンダー予定
${calendarSummary}
### Asanaタスク
${asanaSummary}
### Box(上位の操作だけ。フルパスやファイル名は原則出さず、種類と件数中心)
${boxSummary}
### Zoom会議(参加した会議)
${zoomSummary}
# タスク判定ルール(JST基準)
- 「今日やるべき」: due_date が対象日以前 AND 未完了
- 「今週」: due_date が対象日〜対象日の6日後の範囲 AND 未完了
- 「残タスク」: 未完了すべて(期限なしは「期限なし」分類)
※due_date が無いタスクは「期限なし」に分類する。
# 出力要件(Slack mrkdwn形式 - 厳守)
- 【重要】Markdown の # 見出しは使用禁止。Slackでは表示されない。
- 【重要】太字は **text** ではなく *text* を使う(アスタリスク1つ)
- 【重要】イタリックは _text_ を使う(アンダースコア)
- 見出しは太字(*見出し*)で表現する
- 表は必ずコードブロックで整形(\`\`\`)
- 文章は簡潔に。長くなる場合は箇条書き中心。
- フォーマルなトーン。
- 「本日」「今日」という表現は使わず、具体的な日付(${data?.targetDate || "対象日"})を使う
# 出力フォーマット(この順序で、条件を満たすセクションのみ出力)
1) *${data?.targetDate || "対象日"}のサマリー*
- 必須。事実中心 3-4行で出力。
2) *プロジェクト別工数*
- 条件: 見積もり時間(Asana見積)が1時間以上 OR プロジェクトごとの実績が明確な場合のみ出力
- 見積もりが0時間かつ実績内訳が不明な場合は、このセクション全体を省略する
- 出力する場合は表形式(Project | 見積 | 実績 | 差分 | 根拠メモ)
3) *${data?.targetDate || "対象日"}にやるべきだったタスク*
- 条件: due_date情報を持つタスクが1件以上ある場合のみ出力
- due_date情報がないタスクしかない場合は、このセクション全体を省略する
4) *今週のタスク*
- 条件: due_dateが今週の範囲内にあるタスクが1件以上ある場合のみ出力
- 該当タスクがない場合は、このセクション全体を省略する
5) *残タスク*
- 条件: 未完了タスクが1件以上ある場合のみ出力
- 未完了タスクがない(完了タスクのみ)場合は、このセクション全体を省略する
6) *AIからのアドバイス*
- 必須。最大3点。各点は「観察(事実)→提案→期待効果」の順。太字は *text* 形式で。
# 重要な注意
- 「判定不可能」「情報がありません」などのメッセージでセクションを埋めるのは禁止
- データがないセクションは見出しごと完全に省略すること
- 省略したセクションについて言及しないこと対象者が働き過ぎ、タスク処理漏れのとき、さらにそれを通知する
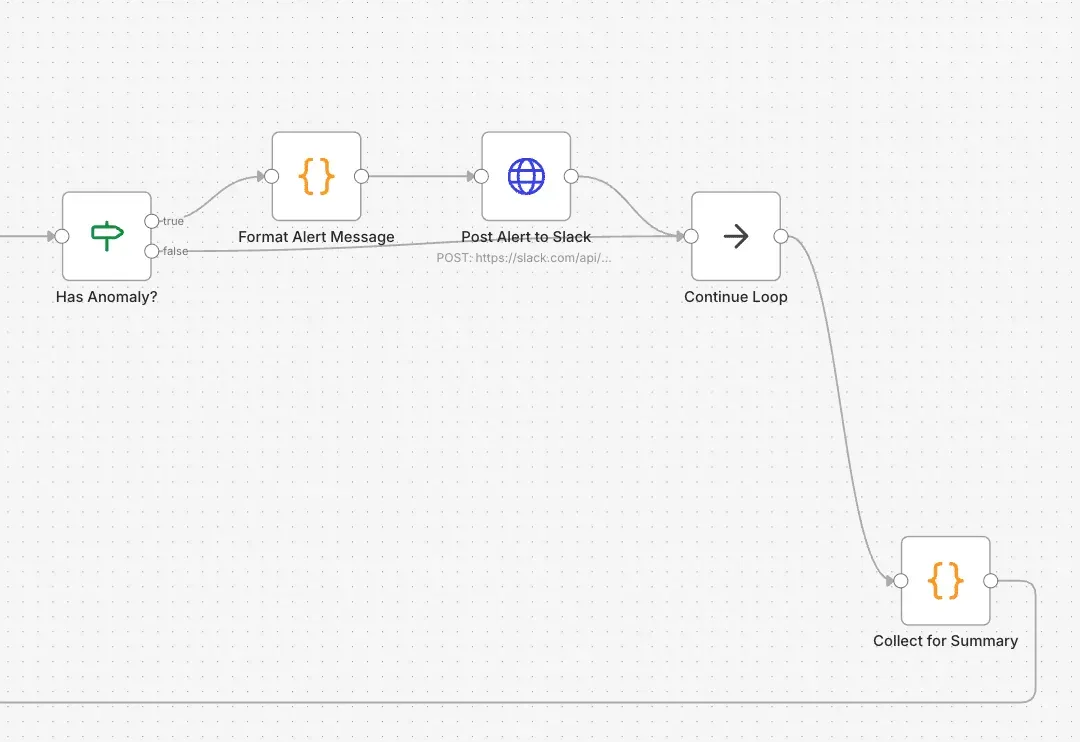
実働時間が長すぎたりすると追加で教えてくれます。また、見積もり工数と実績値が乖離している場合も教えてくれます。ここで1人分の処理は終了して、次の人に行きます。
全員分終わったら、マネージャー向けのサマリーを出力する
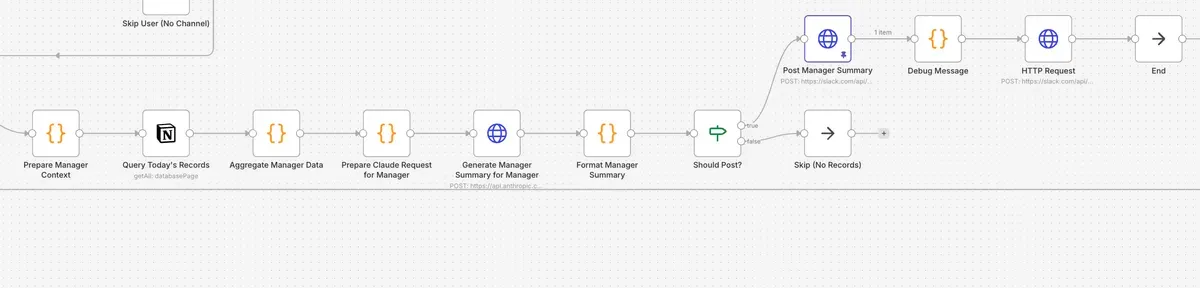
Notionに保存された全員分のデータを参照して、マネージャーがやるべきことを教える内容を生成して、Slackに投稿します。
そのときのプロンプトはこれです。
# 役割定義
あなたは組織開発と業務改善の専門家であり、マネージャーの右腕として機能するAIアシスタントです。従業員の日次活動データを分析し、マネージャーが即座に行動できる具体的で詳細なインサイトと推奨アクションを提供してください。
# 入力データ
以下に、${data.dashboard.totalEmployees}名の従業員の日次活動サマリーを提供します。
## 対象日: ${data.targetDate}
## 組織全体サマリー
- 総従業員数: ${data.dashboard.totalEmployees}名
- 平均稼働時間: ${data.dashboard.avgEstimatedHours}時間
- 平均会議時間: ${data.dashboard.avgMeetingHours}時間
- 平均タスク完了数: ${data.dashboard.avgTasksCompleted}件
- 総タスク完了数: ${data.dashboard.totalTasksCompleted}件
- 総会議数: ${data.dashboard.totalMeetingsCount}件
- 総Slackメッセージ数: ${data.dashboard.totalSlackMessages}件
- 総メール送信数: ${data.dashboard.totalEmailsSent}件
- 総Box活動数: ${data.dashboard.totalBoxActivities}件
## 警告・注意が必要な状況
- 異常フラグ該当者: ${data.alerts.anomalyCount}名
${JSON.stringify(data.alerts.anomalyEmployees)}
- 会議時間5時間超: ${data.alerts.highMeetingCount}名
${JSON.stringify(data.alerts.highMeetingEmployees)}
- 会議時間8時間超(即時介入必要): ${data.alerts.criticalMeetingCount}名
${JSON.stringify(data.alerts.criticalMeetingEmployees)}
- 稼働状況不明(タスク0・会議少・Slack少): ${data.alerts.lowActivityCount}名
${JSON.stringify(data.alerts.lowActivityEmployees)}
## プロジェクト別稼働状況(上位10件)
${JSON.stringify(data.projectSummary)}
## 高パフォーマー(タスク完了数上位)
${JSON.stringify(data.topPerformers)}
## 従業員個別サマリー
${JSON.stringify(data.employeeSummaries)}
# 出力フォーマット(Slack mrkdwn形式)
以下の形式でSlack投稿用の詳細なマネージャーサマリーを出力してください。
🏢 *組織活動サマリー(${data.targetDate})*
*エグゼクティブサマリー*
組織の当日の状態を5行程度で詳細に表現。主要な懸念点、ポジティブな点、注目すべきトレンドを含める。
*📊 組織ダッシュボード*
\`\`\`
総従業員数: XX名
平均会議時間: X.X時間
総タスク完了: XX件(平均X.X件)
総会議数: XXX件
Slack活動: XXX件
Box活動: X,XXX件
\`\`\`
*🚨 異常フラグ該当者*
Critical(即時対応必要): 該当者全員の名前を列挙
→ 各人の状況と推測される原因を1行で補足
Warning(注意観察): 該当者全員の名前を列挙
→ 各人の状況と推測される原因を1行で補足
*🚨 即時対応が必要な事項*
*1. 会議負荷超過者への緊急介入*
対象者(8時間超):
該当者それぞれについて以下の詳細を記載:
- 名前: XX.X時間(担当案件名)
- 推測される負荷の原因
- 健康面・モチベーションへの影響リスク
- 具体的な軽減策の提案
*2. 異常フラグ対象者へのフォローアップ*
対象者それぞれについて:
- 名前(フラグ種別)
- 観察された異常パターン
- 推測される背景要因
- 推奨されるアプローチ
*⚠️ 今週中に対処すべき組織課題*
*課題1: 会議過多による生産性低下*
- 事実: ${data.alerts.highMeetingCount}名が5時間超の会議に参加
- 該当者: 全員の名前をカンマ区切りで列挙
- 影響分析: 会議時間が長いことによる具体的な業務への影響
- 推奨施策:
1. 具体的な施策(実施方法、期待効果を含む)
2. 具体的な施策(実施方法、期待効果を含む)
3. 具体的な施策(実施方法、期待効果を含む)
*課題2: タスク管理の標準化*
- 事実: タスク完了0件の人数と割合
- 該当者: 全員の名前をカンマ区切りで列挙
- 影響分析: タスク管理されていないことの具体的なリスク
- 推奨施策:
1. 具体的な施策(実施方法、期待効果を含む)
2. 具体的な施策(実施方法、期待効果を含む)
*課題3: プロジェクト負荷の偏り*
- 事実: 上位プロジェクトでの負荷集中状況
- 影響を受けているメンバー: 名前と担当プロジェクト
- 推奨施策: 具体的なリソース再配分案
*📈 組織強化の機会*
*高パフォーマーへの感謝と活用*
該当者それぞれについて:
- 名前: XX件完了(担当案件名)
- 特筆すべき成果や働き方の特徴
- 組織への横展開ポイント
- 推奨される評価・フィードバック方法
*横展開すべきベストプラクティス*
- 具体的な事例1: 誰の何がどう優れているか
- 具体的な事例2: 誰の何がどう優れているか
*📋 マネージャー向け詳細アクションプラン*
*【優先度: 高】本日中に実施*
□ *会議負荷超過者との1on1面談*
対象者: 該当者全員の名前
所要時間: 各15-20分
話すべきポイント:
- 現在の業務状況と体調確認
- 会議が多い原因の把握(必須出席か、代理可能か)
- 明日以降で延期・キャンセル可能な会議の特定
- 必要に応じて他メンバーへの業務分散を提案
期待する成果: 翌日の会議時間を50%削減する具体的計画
□ *異常フラグ該当者への状況確認*
対象者: 該当者全員の名前
所要時間: 各10-15分
話すべきポイント:
- 業務の進捗状況と困っていること
- 期限超過タスクの原因と対策
- サポートが必要な領域の特定
期待する成果: 各人の課題を明確化し、サポート計画を策定
*【優先度: 中】今週中に実施*
□ *会議5時間超メンバーのスケジュール分析*
対象者: 該当者全員の名前
所要時間: 30分(カレンダー分析)
実施内容:
- 来週の会議予定を確認
- 必須/任意参加の仕分け
- 30分以上の会議で短縮可能なものを特定
- 代理出席可能な会議をリストアップ
期待する成果: 各人の来週会議時間を20%削減
□ *高パフォーマーへの感謝とナレッジ共有依頼*
対象者: 該当者全員の名前
所要時間: 各5-10分(Slack DMまたは口頭)
伝えるべきポイント:
- 具体的な成果への感謝
- 効率的な働き方のコツをチームに共有してほしい旨
- 次回チームMTGでの5分間共有を依頼
期待する成果: ベストプラクティスの組織的な横展開
*【優先度: 低】来週以降に計画*
□ *全社向けタスク管理研修の企画*
対象者: タスク完了0件のメンバー(優先)+ 希望者
所要時間: 企画30分、研修60分
内容:
- Asanaの基本操作とベストプラクティス
- 日次タスク設定の習慣化方法
- 高パフォーマーの活用事例紹介
期待する成果: 2週間後のタスク登録率80%達成
□ *会議効率化ルールの策定と展開*
実施内容:
- 30分会議をデフォルトにするルール提案
- アジェンダ必須ルールの導入
- 議事録テンプレートの整備
期待する成果: 翌月の平均会議時間を1時間削減
# 制約条件
- 推測ではなく、提供されたデータに基づく事実のみを根拠とすること
- 個人への批判ではなく、組織としての改善機会として表現すること
- *最重要*: 「XX名」という人数だけの表記は禁止。必ず該当者全員の実名を列挙すること
- *最重要*: 異常フラグ、会議超過、タスク未完了など、すべての項目で該当者名を省略せず全員記載
- *最重要*: アクションは具体的に。「1on1実施」だけでなく「何を話すか」「何分かけるか」「期待する成果」まで記載
- 従業員の実名をそのまま使用すること(匿名化しない、太字にしない)
- 出力はSlack mrkdwn形式(太字は *テキスト* だがセクション見出しのみに使用)
- 絵文字を適切に使用すること
- フッターや署名は絶対に出力しないこと
- 「詳細は」「自動生成」などの文言は出力しないこと
- 出力は十分に詳細であること。短くまとめすぎないこと。さらにここに、チームや組織の概念を加えて、誰々の上司はこの人だから、このチームのサマリーはこの人に送る、とかも作れるのですが、とりあえずいったんまとめて生成にしてます。投稿自体はパブリックチャンネルなので誰でも見られます。とりあえず役員だけチャンネルに招待しておきました。
実際に投稿された個人の活動履歴

これ、実在する人間の上司から毎日言われたらちょっとイラッとくるかもしれませんね。俺ならイラつきますね。AIが言ってるからまぁ、みたいな感じになるのがAIのいいところです。
この画像ではタスク一覧が表示されていますが、誰もが積極的にAsanaで全てのタスクを管理しているわけではないので、Asanaからのデータがない場合はタスク詳細部分が省略されてすっきりした内容になります。
余談ですが、このスクショを取ったときに日付が1日ずれてることと、Slackリアクションがやたら多すぎることに気がついたので、ブログ書きながら直してます(直しました)
実際に投稿されたマネージャー向けサマリー
各従業員向けは小さなサマリーでしたが、マネージャー向けは情報量てんこもりにしてあります。
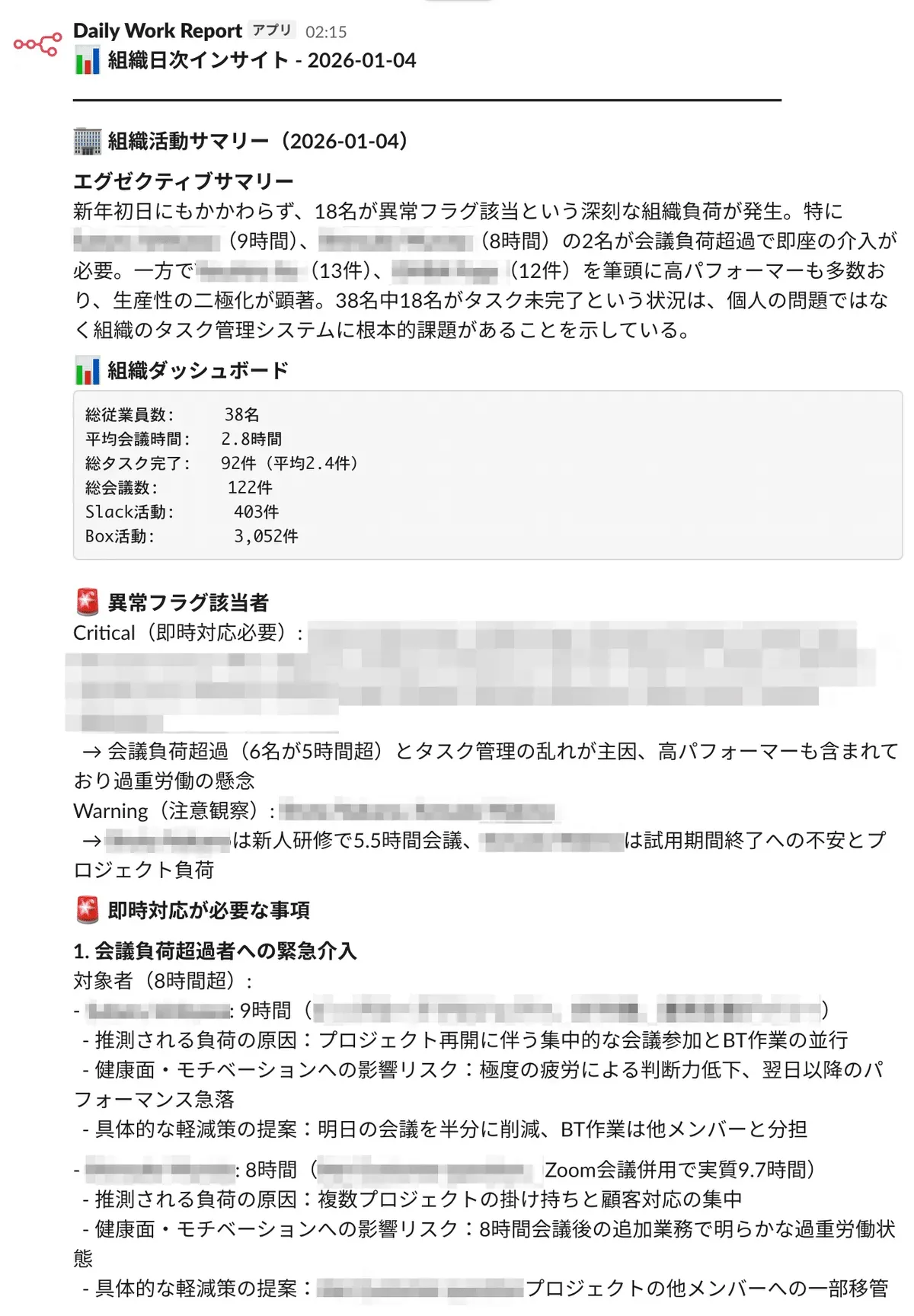




どうですか。たっぷりでしょ?目を覆いたくなりますね。
これに対して言いたいことはいっぱいあるんですが、AIは従業員に優しいということが分かりました。マネージャーには厳しいですね。ぐぬぬ。
n8nはゲームFactorioに通じる面白さがある

IT研修でも使われるゲームFactorioは、総プレイ時間2000時間以上プレイしたくらいはまっているゲームです。ふとしたときにやりたくなる中毒性があります。どうやって作業を効率化していくかを考えるゲームなのですが、n8nにも同じように1つの処理(ノードと呼ばれています)を追加していくごとにどんどん肥大化し、肥大化したものを効率化するように作り替えたりして、まるでゲーム感覚でした。
ワークフローは全て生成AIで作成した
「n8nを使ってこれこれこーゆーことをやりたい、インポートできるJSON作って。」というところから、生成AIで用意したJSONをダウンロード、n8nでインポートして動かして、出たエラーや期待した動きをしていないところをAIにコピペ、そして結果をn8nコピペ。これだけで完成です。素晴らしい世界だ。コードの中身を見る気が起きなくなるぜ。
試した生成AIは、ChatGPT5.2(個人のやつと会社のやつ)、Gemini(個人のやつと会社のやつ)、Claude(個人のMAXプラン)の3つです。いろいろ試した感じでは、ChatGPTの場合、問題に問題を加えて問題を複雑化した結果、どんどん肥大化していくので辞めました。Geminiは知りたくもない情報のアウトプットが多すぎて辞めました。結果的にClaudeで落ち着いたのですが、コピペに及ぶコピペのお祭りで、Claude側が容量パンパンで受けきれなくなるのが地味にきつかったですか、仕方なし。
n8nはクラウド版の無料から始めて結果セルフホストになった
無料はお試し15日間なので、結果的には課金しました。といっても月額4〜5千円で使える一番安いプランです。
これでこのワークフローを作っていましたが、不明なエラーが連発。n8n Cloud Starterプランのメモリ上限は320MiBで、メモリも足りません。デバッグログも取れないので、なんで止まったのかよくわからんのです。生成AI曰く、実行時間が長いからクラウド版の実行時間制限を超えていると。んでもってこの問題は上位プランにしたところで解決しないからホストしろってことでホストしました。
GCPを選択、インフラ構築のTerraformも生成AIが書く
ターミナルで実行するだけです。らくちーん。ドメインは既存のものがAWS Route53にあるので、そこだけはAWSを使いました。セキュリティ設計もAIが生成してます。
インスタンスサイズ問題
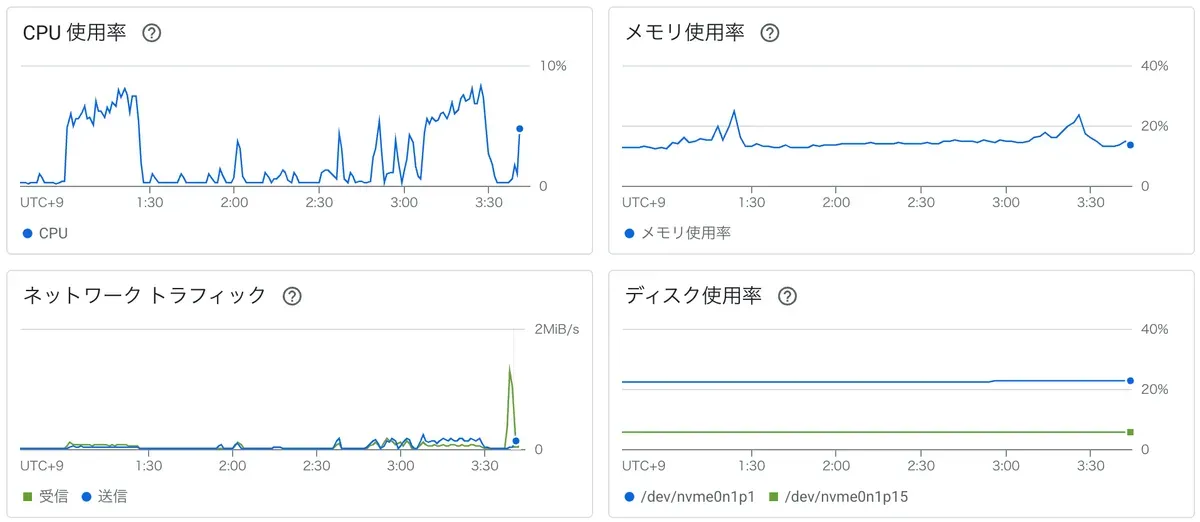
安いマシンだと、安いのはいいんですが、何時間待っても全員分の処理が終わらないので、いろいろ試した結果c3-highcpu-4 (4 個の vCPU, 8 GB メモリ)に落ち着きました。月額2万くらいしそうですが、動かないよりはましということと、このサイズだとかなり余裕あるのですが、そもそもこいつ爆速で処理してくれるので(実行完了までの速度が安いインスタンスと比較して1.7倍速い)まぁいいかとなりました。
ホストしたn8nの環境設定問題
n8nがデフォルトで各ノード実行ごとにSQLiteデータベースに実行データを保存していたことが原因で、データがどんどん肥大化して重くなり、処理が遅くなっていきました。結果的にSQLiteデータベースファイルが肥大化します。というわけで設定を変更します。
environment:
# 成功時のデータ保存を停止
- EXECUTIONS_DATA_SAVE_ON_SUCCESS=none
# 進行中のデータ保存を停止(最重要)
- EXECUTIONS_DATA_SAVE_ON_PROGRESS=false
# 古い実行履歴を自動削除
- EXECUTIONS_DATA_PRUNE=true
- EXECUTIONS_DATA_MAX_AGE=168 # 7日間(時間単位)
- EXECUTIONS_DATA_PRUNE_MAX_COUNT=1000
# バイナリデータをファイルシステムに保存
- N8N_DEFAULT_BINARY_DATA_MODE=filesystem
# Node.jsヒープサイズの最適化
- NODE_OPTIONS=--max-old-space-size=4096肥大化したSQLiteファイルをVACUUMコマンドで圧縮します。
# コンテナ停止
docker compose down
# VACUUM実行
sqlite3 /opt/n8n-data/database.sqlite "VACUUM;"
# WALをメインDBに統合
sqlite3 /opt/n8n-data/database.sqlite "PRAGMA wal_checkpoint(TRUNCATE);"
# 再起動
docker compose up -dこれをホストで自動実行します。PostgreSQLへの変更も考えましたが(PostgreSQLにすると、この作業が要らない)、まいっかと思ってこのままです。
ここまでの内容も全部生成AIの指示通りです。
n8nのMergeノードが使い物にならない問題
Mergeノードはその名の通り、いろんなデータを受け取ってマージしてくれるノードなのですが、結果的にSaaSの各種データをまとめる処理を、Codeノードで処理することになりました。なぜかこの子、ループ処理内にいると挙動が安定しないとか、マージするデータが3つ以上になるとダメだとか、なんだかいろんな問題に遭遇しまして、そもそもMergeノードは一切使わない方針で進めました。AIさんがそうおっしゃるので。
サブワークフローが結果的に使えない問題
n8nでは、ワークフローが別のワークフローを呼び出して、一定の処理を別のワークフローに任せることができるのですが、結局動作は並列にならないし、デバッグ大変だし、思った通りにデータ入ってこないしと、いいこと全然なかったのでこれも使わない方針で進めました。
ノードはアプリのものよりHTTPノードの方が安定する
と、AIさんがおっしゃいましたので一部そうしていますが、実際そうです。Slackアプリとか使うと思ったとおりに値が取れなかったりして、結局はHTTPノードで細かく設定していく方が期待値通りの動きになりますね。
テスト用の処理も追加している
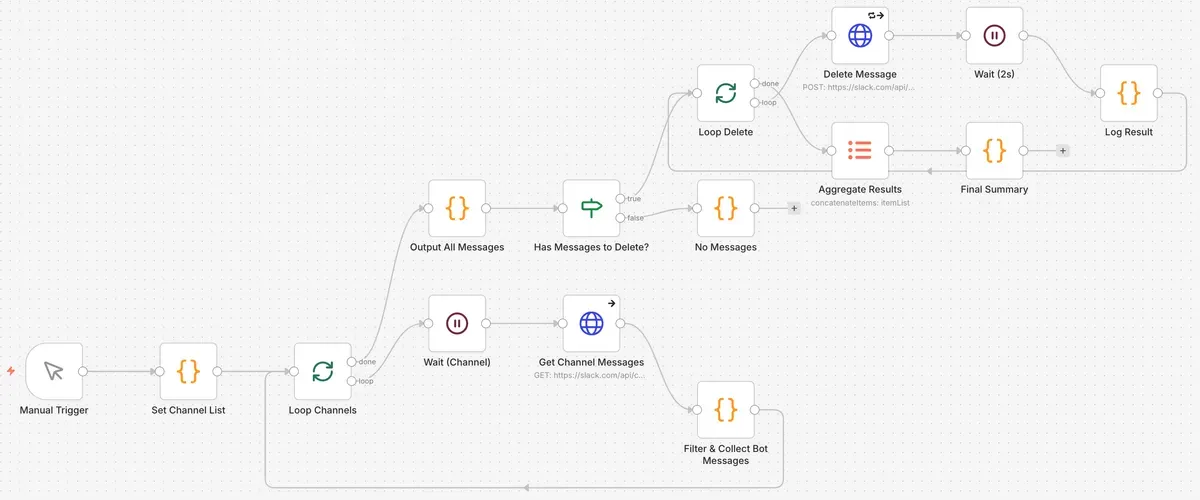
日付を固定して取得したり、実行時間などの結果を自分のSlackチャンネルに投稿する処理も追加してます。このワークフローをテストすると、テストするたびに全員のSlackチャンネルにサマリーが投稿されるので(投稿処理をスキップすることもできたのですが、きちんと投稿されることで俺の心理的安心を得られるので投稿しまくった)、投稿したデータだけを削除するワークフローを別で作って動かしています。こっちのトリガーは手動です。年末年始に作ったので、社内がざわざわすることはたぶんなかったはずだ。もちろんこのSlackメッセージ削除ワークフローもAIが生成しました。
今後の展望
SQLiteからPostgreSQLに変更すればより安定しそうではあるし、細かいところはいろいろあるんですが、そんなことをするくらいならGo言語で実装し直して、AWS Lambda/Cloud Functionsあたりで実行した方が爆速で処理できるはずです。並列処理できる上に、ついでに安い。
もちろんこれ、やろうと思ったら、n8nからダウンロードしたワークフロー全体のJSONを生成AIに投げるだけです。
そもそもこのワークフローの実行効果は会社的にどうか
わかりません!やってみたかっただけです!というか出力してまだ初日です!なんか面白そうだったからってだけでいいじゃないですか!
ちなみにこの記事は
100%手書き?です!