
IDチームの前田です。QK Alice Duoという分割Aliceレイアウトキーボードという夢のようなキーボードが発売されるようですが6万円位するらしくさすがに手が出ないので愛用しているNeo Ergoで我慢しております。Neo Ergoも最高です!

今回は2025年04月23日に発表されたOpenAI gpt-image-1 のAPIを利用したSlackbotを試作し、gpt-image-1の業務利用を検討した話をします。
本ブログ内の画像はgpt-image-1の技術検証目的で掲載しています。 本記事で掲載している画像は、画像生成AIによる創作物で既存のキャラクターや著作物の権利侵害を意図したものではありません。
三行まとめ
- OpenAIの最新画像生成モデル gpt-image-1 の仕様把握と業務利用の検討でSlackbotを試作
- 実用に耐えるレベルの画像生成には費用コストがかかる。また権利的にも怪しい画像が生成される
- 現時点だと業務利用のユースケースはかなり限定的になりそう
OpenAI gpt-image-1とは
- https://openai.com/index/image-generation-api/
- gpt-image-1は、執筆時2025年05月でOpenAIが提供する最新の画像生成AIモデルで、テキストや画像を同時に入力し、高精度な画像生成や編集ができる「ネイティブ・マルチモーダル」モデルです
- 従来よりも画像内の文字表現や複雑な指示への対応力が大幅に向上しています
- 分かりやすいところで言うと、最近流行のジブリ化などの画像処理をしている画像生成AIモデルです。
- これまでChatGPTなどからだけしか利用出来なかったのですが、API経由で利用が可能になりました
gpt-image-1 利用までの注意事項
- gpt-image-1を利用するには、API Organization Verificationが必要で、代表者の本人確認が必要になります
- 2025年5月1日現在のAPI Organization Verificationの注意事項として、90日に1回しか本人確認が出来ず、組織で本人確認を行うと、別の組織では本人確認を行うことが出来ません。
- 複数の組織を管理しているユーザーがA組織で本人確認をすると、B組織やC組織では本人確認を実行することが出来ないため、gpt-image-1 をA組織でしか利用出来なくなります。そのためB組織やC組織では別の人が本人確認の作業を行う必要があります。
Slackからgpt-image-1を利用する
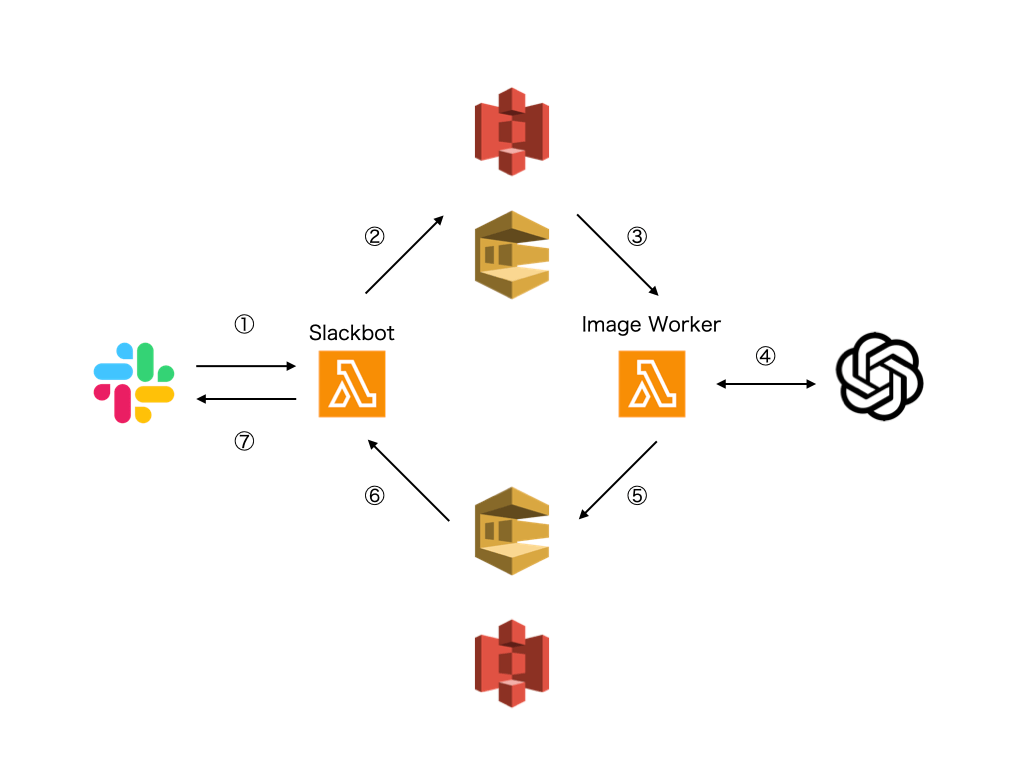
実際のコードなどは機会があれば公開するとして、構成としては下記になります。
- SlackからSlackbotにメンションで指示
- SlackbotからAmazon SQSにプロンプト、S3に画像を保存
- Image WorkerがSQSのメッセージをトリガーにしてImage Workerが起動
- OpenAI gpt-image-1 API に画像生成依頼
- 生成された画像をS3に保存、SQSに結果情報を送信
- SQSの結果が入ったメッセージをトリガーに、Slackbotが起動
- Slackに画像を投稿
実装のポイントとしては
- SlackbotはAWS Lambda上で稼働(AWS Chaliceで開発)
- 画像生成処理に数分要するため、非同期処理にするため画像処理用のLambda Functionを別で用意(AWS SAMで開発したけど、AWS Chaliceで統一しても良かったかも)
- SlackbotのLambda Functionと画像処理用のLambda Function のデータやりとりで、メッセージはSQS、画像はS3でやりとり
- 画像生成時のパラメーターはImage Worker側でプロンプトを見て判断して調整。高画質が含まれていたら quality=”high” に設定など。
利用してみて分かった gpt-image-1
品質問題
画像生成時のqualityパラメーターがあり、low, middle, high があるのですが high 以外は実用が厳しい印象。middleの場合はプロンプトで頑張る必要があり、リトライを何回も繰り返すので結果的にhighよりもコストも時間がかかったりしました。
各画像を拡大して見たい場合は、ブラウザ上で右クリックで別タブで開いて見てください
Qualityパラメーターごとの比較
| low | middle | high |
 |  |  |
以下は同じプロンプトでlow, middle, highでqualityを変えて変更した画像。
- うどん
- カリスマ情シスが法廷で追及を受けている様子 ジブリ風
- 中華料理
quality=”low” の出力例
 |  |  |
quality=”middle” の出力例
 |  |  |
quality=”high” の出力例
 |  |  |
Stable Diffusionなどと同じように、プロンプトエンジニアリングがかなり必要。後述のコスト問題があるので、リトライをされまくるとコストがかなりかかります。
費用コスト問題
画像の場合トークン数が多いため、費用コストがかなりかかります。 開発着手時に何も考えずquality=”high” にしていたため一瞬で$10を溶かしました
- gpt-image-1の価格
- テキスト入力トークン (プロンプトテキスト) : 100万トークンあたり5ドル
- 画像入力トークン (入力画像) : 100万トークンあたり10ドル
- 画像出力トークン (生成画像) : 100万トークンあたり40ドル
- size=1024×1024にして、lowで2〜3円、middleで10〜15円、highで30〜45円くらい
- 特に画像編集はInput tokenもコストがかかるので、枚数が多いと1回で数百円みたいなことが発生するので、利用者へのコスト通知、コスト監視が必須
APIレスポンスにusage tokenが含まれるため、生成にかかったコストも通知するようにしています。

権利問題
- 著作権的に問題になりそうな、炎上しそうな画像を生成してくる
- キャラクター名とかはコンテンツポリシー違反で生成されないですが、巧妙にプロンプトを書くと、ほぼそのキャラクターまんまみたいなのが出てくる
- このグレーな画像を業務として使わないようにするリテラシーとかが問われる
OpenAI側でポリシー違反でブロックされるケースとされないケースがある。
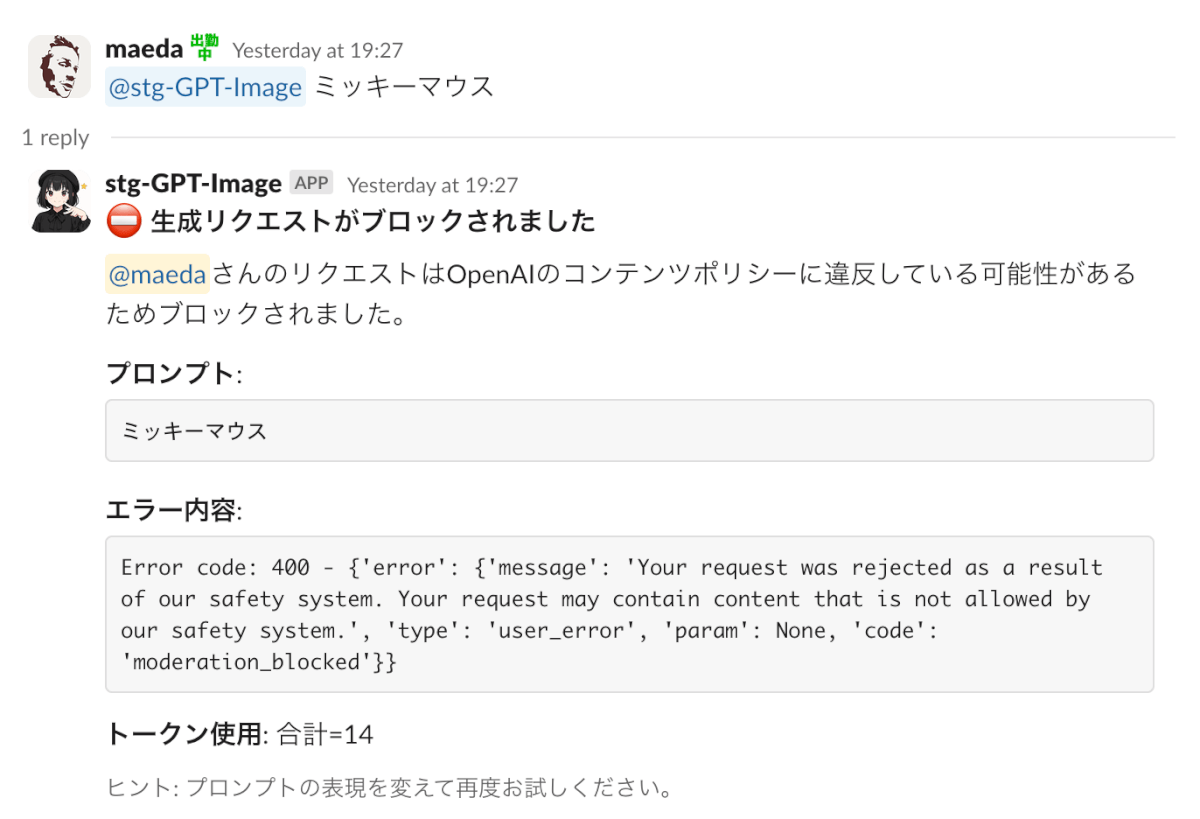
プロンプトでギリギリを攻めなくても、ほぼまんまの絵が出てきたり。
筆者は谷口ジロー展に会期中何回も通うほどのファンなのでこういうのがそのまんま出てくるのはちょっと…

想定される業務利用
リリースされて実際に利用してみて、コストと権利関係で業務で利用するのはかなり難易度が高いのではという印象です。プロンプトを頑張るなら別の画像に特化したStable Diffusion、Midjourney、FLUX.1などの方が良さそうと思いました。当社だとgpt-image-1は社内向けの限定適用とで利用する形になりそうです。
少なくとも今回試作したSlackbotなどは不特定多数が利用する可能性があるため、コスト面と権利面で業務利用には適さないのかなと個人的には思いました。