
セキュリティチームのぐっちです。先日、ある方に「視覚障害者向けの音声コンテンツをAIで作れないか?」と相談を受け、サッとデモアプリを作ってみました。残念ながら、この話は案件や事例には繋がらなかったものの、せっかく作ったデモアプリを手元で眠らせておくのも悲しいので、解説や願いを含めて公開したいと思います。
情報アクセシビリティの向上:すべての人に開かれた社会へ
近年、情報アクセシビリティの重要性が高まっています。特に、視覚障害を持つ方々にとって、日常生活に必要な情報へのアクセスは依然として大きな課題となっています。もちろん、従来であれば点字や人間による読み上げデータが利用されてきました。しかし、それらを用意する実務上は以下のようなコストがかかり、障壁となるケースがあります。
健常者1向けのコンテンツを視覚障害者向けフォーマットに変換するコスト
世の中の大半のコンテンツは健常者向けに作られています。それは表形式になっていたり、さまざまなデザインや装飾が含まれたりするわけですが、そのまま音声読み上げすると視覚障害者にはうまく伝わりません。音声読み上げデータを作る前処理として、原稿を読み上げデータに最適化してあげる必要があります。これは簡単そうに見えて、地味に工数がかかる作業です。

視覚障害者向けコンテンツを音声データにするコスト
前処理で視覚障害者にとって伝わりやすい原稿を作っても、それを音声データにするところにも更なる工数がかかります。人間が読み上げて原稿を作成する場合では、言い間違えると取り直しが必要ですし、何より多くの時間を必要とします。
また、このような工程を挟むと健常者向けの情報が出てから、視覚障害者向けの情報が作成されるまでのタイムラグが発生します。私が聞いたとあるケースでは、2週間程度のタイムラグが発生していたとのことです。情報は鮮度が大事であることも多く、タイムラグの存在は決して望ましいものではありません。
視覚障害者向けの音声コンテンツを作るAI
文字情報を音声に変換する技術は、この課題に対する重要な解決策の一つです。今回紹介するモックは、Azure OpenAI・Document Intelligence・Azure AI Speech といったさまざまな Azure AI Service を活用して、そのような課題に取り組んだものです。
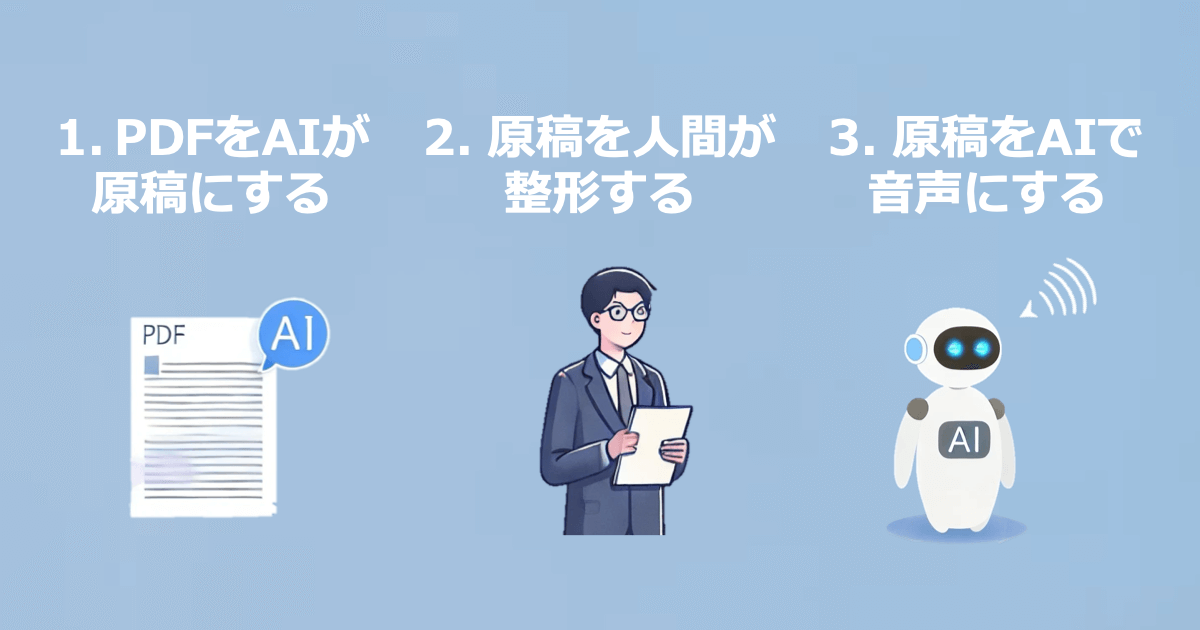
今回開発したモックは上記の3工程で利用することを想定して作られています。最初のプロセスでは、PDFをOCRで解析しつつ、Azure OpenAIの力を使って、読み上げ原稿を作成します。次に、その原稿を人間が整形し、原稿をAIで音声データに変換します。
工程1. PDF文書からAIで読み上げ原稿の作成
工程1の流れ
この工程では健常者向けに作成されたコンテンツを、視覚障害者向けのフォーマットに変換します。「工程3」の音声AIに健常者向けのコンテンツを直接投入する手段もありますが、前述の通り、視覚障害者には伝わりにくいフォーマットであるので、変換作業を挟みます。流れは以下の通りです。
- PDFデータをMicrosoft Teamsにアップロード
- Logic Appsがトリガーされる
- Azure Document Intelligenceによって1ページずつOCR処理
- OCR結果を Azure OpenAI(ChatGPT)に渡し、読み上げ原稿の生成
技術的なポイント
現在、Azure OpenAI GPT-4o では12.8万トークン(日本語12万文字※超概算)までの情報を入力することができますが、出力する情報量の限界は1.6万トークン(日本語1.6万文字※超概算)です。2 情報量がそれに収まるコンテンツであればいいのですが、分量が多いコンテンツを音声データ化したいというニーズがあったため、Azure Document Intelligenceによって1ページずつOCR処理をし、1ページずつ順番に処理をする流れとしています。
また、原稿は自然な読み上げデータにするために、プロンプトで「原稿を作成する際には、音読して意味が伝わりやすい文章の原稿として出力します。」というような要件を伝えて、より伝わりやすい出力にさせました。このように要件を言語で伝えられるのは良いですね。
インプット&アウトプット
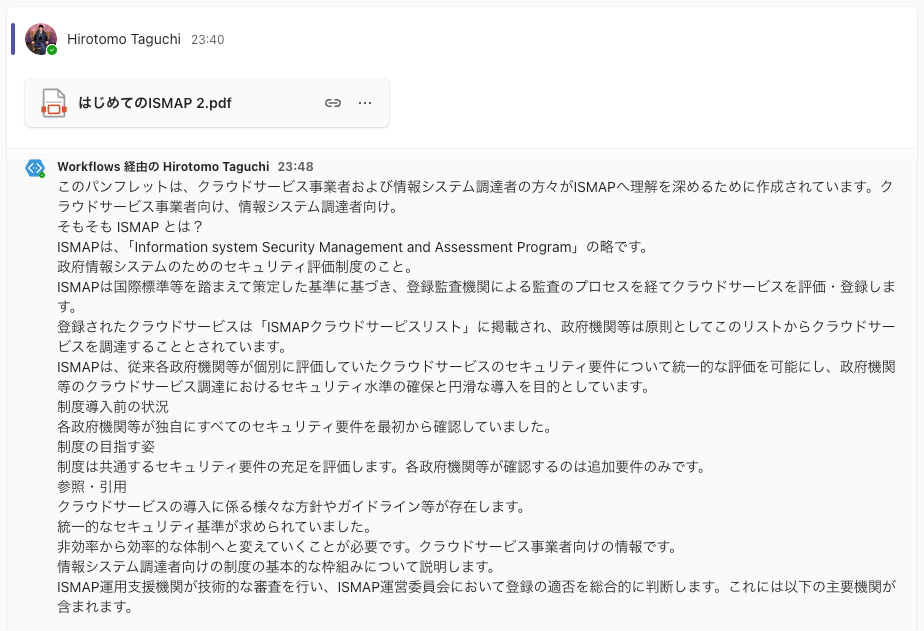
今回は、内閣サイバーセキュリティセンター、デジタル庁、総務省、経済産業省が公開している以下のPDFを利用して検証を行いました。3 これは、健常者にとっては読みやすいですが、そのまま読み上げても意味の伝わりにくい資料です。
これを Teams の特定のチャンネルに投下すると、以下のようなアウトプットとして出力されました。完璧とは言い難いですが、原稿としてはまずまずの文章を出力してくれました。
工程2. 原稿を人間が生成する
工程1で作った原稿の精度は80%程度(注:筆者の主観)です。これは非常に高い精度ですが、完璧ではありません。残りの10%から20%の誤りに対しては、人間による確認と修正が必要となります。この「人間とAIの協働」という点は、AIシステムを実用化する上で重要なポイントとなります。音声データにする前に、不適切な表現や意味が通らない表現を修正します。
今後、モデルがアップデート等されたり、プロンプトを調整することで、人間の修正にかかる工数は削減できるとは考えています。例えば現在は、Azure OpenAI の出力トークンが16000トークンということで、1ページずつ処理しています。これが、精度を落としている原因の1つではありますが、例えば64000トークン出力できる下記のモデルなどが一般公開されると、すべてのページを同時に処理ができ、精度が向上するのではと期待しています。
工程3. 読み上げ原稿から音声データの生成
工程3の流れ
- 修正された読み上げ原稿をTeamsの別チャンネルに投稿
- Logic Appsが再びトリガーされる
- Azure AI Speech による音声データの生成
技術的なポイント
工程3では、Azure AI Speech のAPIを利用して、音声データを作成しました。Azure AI Speech は Microsoft の Azure Cognitive Services の一部として提供される音声認識と合成のサービスです。これを利用することで、音声認識(Speech to Text)や音声合成(Text to Speech)をアプリに組み込むことができます。
インプット&アウトプット
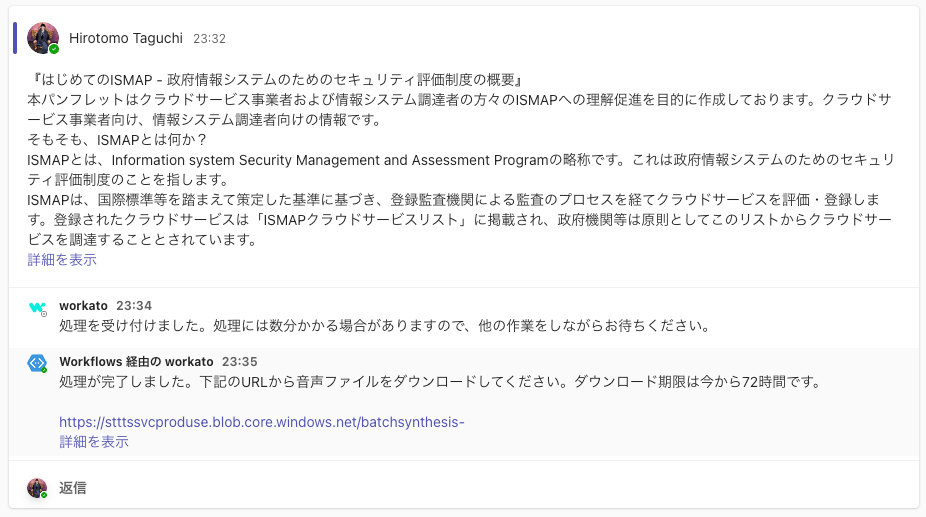
今回作ったデモアプリ
今回のデモアプリは Github 上で公開しています。案件で作ったものではなく、筆者が週末にサクッと作ったものなので、エラー処理などはしてません。ゴリゴリの開発者に見られるのは恥ずかしい出来栄えではありますが、あくまでデモアプリであるということを留意しつつ、参考にしていただけたら幸いです。
まとめ
このシステムの最大の意義は、視覚障害者の情報アクセシビリティを大幅に向上させるポテンシャルがある点にあります。従来、点字化や人手による読み上げが必要だった文書を、迅速かつ効率的に音声化することが可能になります。また、担当者の業務負担を軽減し、より多くの文書を音声化することができます。加えて、健常者と視覚障害者の情報のタイムラグを縮める効果も見込めます。
技術は日々進化しています。しかし、最も重要なのは、その技術をどのように活用し、市民の生活をより良いものにしていくかというビジョンだと考えています。AIは強力なツールですが、それを使いこなすのは私たち人間であると思うので、今回のケースのように現場のニーズに耳を傾け、適切な技術を選択し、継続的に改善していく姿勢を忘れずに頑張っていきたいと思います。
- 「健常者」と「障害者」という表現には議論があることも重々承知ですが、一般的かつ適切な言葉が他にないので、このようなワードチョイスにしています。他に適切な言葉がある場合には是非教えていただけると幸いです。 ↩︎
- トークンと日本語文字数の概算については、超ざっくり試算です。内容や利用するトークナイザーによって異なるで、精緻なものではありません。 ↩︎
- 出典:ホーム – ISMAPポータル ↩︎