セキュリティチームのぐっちーです。先日、OpenAI 社から提供開始された Batch 処理(Batch API)は、非同期でChatGPT API を実行し、通常実行時と比べてコストを半額にできるオプションです。この仕組みは、安いだけではなくて、非エンジニアでも少しキャッチアップすれば簡単に使えるほど難易度が低いので、「APIはちょっと…」と思っている方に宣伝するつもりでブログを書いています。
OpenAI の Batch処理(Batch API)とは
OpenAI の Batch バッチ処理(Batch API)は、大量のリクエストを非同期に処理できるものです。通常、Web版のChatGPTやChatGPT APIは一問一答をリアルタイムに出すという形ですが、Batch API を利用すると、大量のリクエストを一度に送信し、24時間以内に結果を後でまとめて取得することが可能になります。また、Batch API の利用料金は、同期APIと比較して50%割引となっており、コストパフォーマンスに優れています。この仕組みは、もともとはAPIでのみ提供されていましたが、最近だとGUI上でも実行できるようになっています。 12
非エンジニアが大量処理する際にも使える難易度
従来の ChatGPT API を使った大量処理は、レートリミット(例:1分間にXXXトークン)を気にする必要があり、地味にめんどくさいです。また、サードパーティの拡張やサービスなどでも実現できる手段はありますが、セキュリティ的に大丈夫なのかという課題がもあったりします。そこで、非エンジニアの方は1件1件コピぺする力技をした方もいるのでは(?)と考えています。
Batch の仕組みは、エンジニアが利用するのはもちろんのこと、非エンジニアでも利用できそうな難易度となっています。流石に、パソコン触れませんというレベルの方には難しいかもしれませんが、ホワイトカラーと言われるような仕事をしている人であれば、難なくできそうです。そこで、この仕組みを使うと、レートリミットやエラーハンドリング等を気にせずに、しかも安価に実行できるという点が素晴らしいと思っています。
非エンジニアを想定した Batch API の使い方
前提条件
- OpenAIのアカウントが必要です。
- OpenAI Platform(https://platform.openai.com/settings/organization/billing/payment-methods)にPayment methods(クレジットカード)を登録しておく必要があります。※ 従量課金制です
ステップ1: インプットデータの作成
インプットのデータはJSONL型式でOpenAIに渡す必要があります。型式は以下の通りで、列ごとに考慮が必要な部分を赤字にしています。
{"custom_id": "request-
1
", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "
gpt-3.5-turbo-0125
", "messages": [{"role": "system", "content": "
You are a helpful assistant.
"},{"role": "user", "content": "
Hello world!
"}],"max_tokens":
1000
}}
{"custom_id": "request-
2
", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "
gpt-3.5-turbo-0125
", "messages": [{"role": "system", "content": "
You are a helpful assistant.
"},{"role": "user", "content": "
こんにちは!
"}],"max_tokens":
1000
}}- “custom_id”: リクエストに割り当てられたカスタムIDを指定します。これによりリクエストを一意に識別できるため、重複した値を入れてしまうとエラーになります。
- “model”: 使用するモデルを指定します。ここでは”gpt-3.5-turbo-0125″というモデルが指定されています。対応しているモデルはOpenAI社のヘルプページ3に記載があるので”GPT-4o”など高度なモデル
- “messages”: AIに送信するメッセージの配列を指定します。
"role": "system", "content": "You are a helpful assistant."の部分でAIに役割を認識させ、"role": "user", "content": "Hello world!"の部分で具体的な指示を与えます。 - “max_tokens”: 生成する文章の最大トークンを指定します。ここでは1000に設定されています。
OpenAIの公式ページなどでは、簡単なPythonのコードでJSONLファイルを作成する手順が紹介されていましたが、非エンジニアからすると、なかなかハードルが高いかと思います。そこで非エンジニアの方は以下のようにエクセルやスプレッドシートでJSONLファイルの中身を作るのも大アリなのではと思います。非エンジニアが大量の処理をしたいケースというのは、エクセル型式が多いかと思いますし。
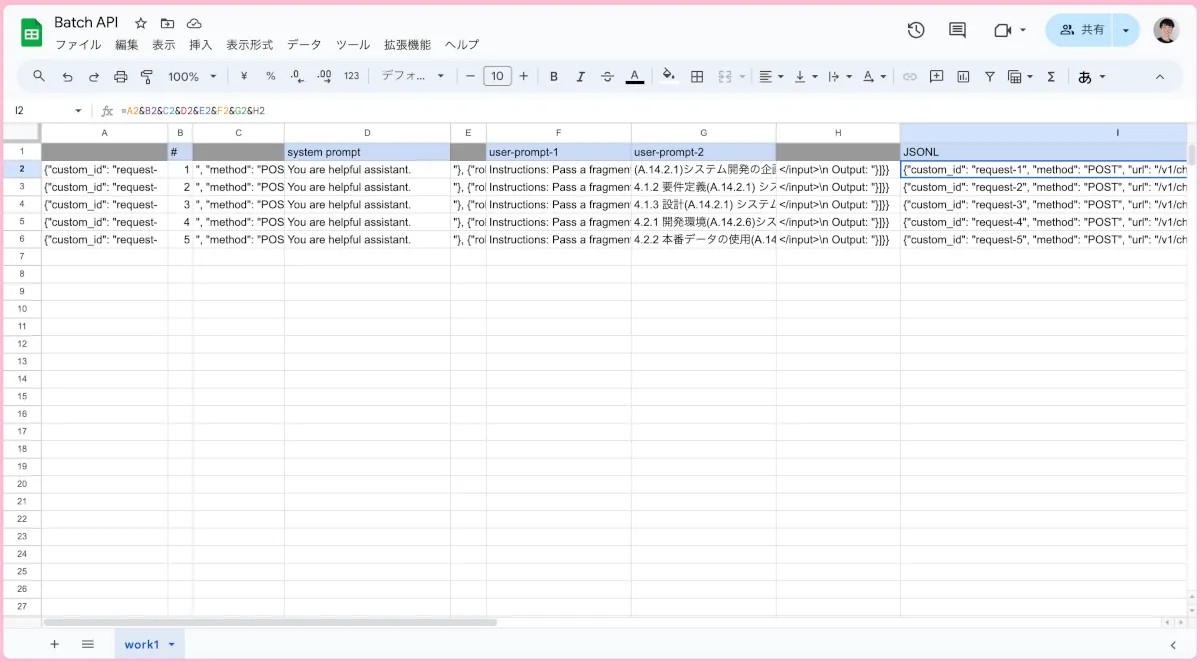
.josnlとなっているファイルに貼り付けます。1行目が青色になっている部分が、各列ごとに変わる部分です。また、プロンプトの部分は2つに分けて構成しています。I列がOpenAIに渡す部分になりますので、この部分だけ拡張子が.josnlとなっているファイルに貼り付けます。
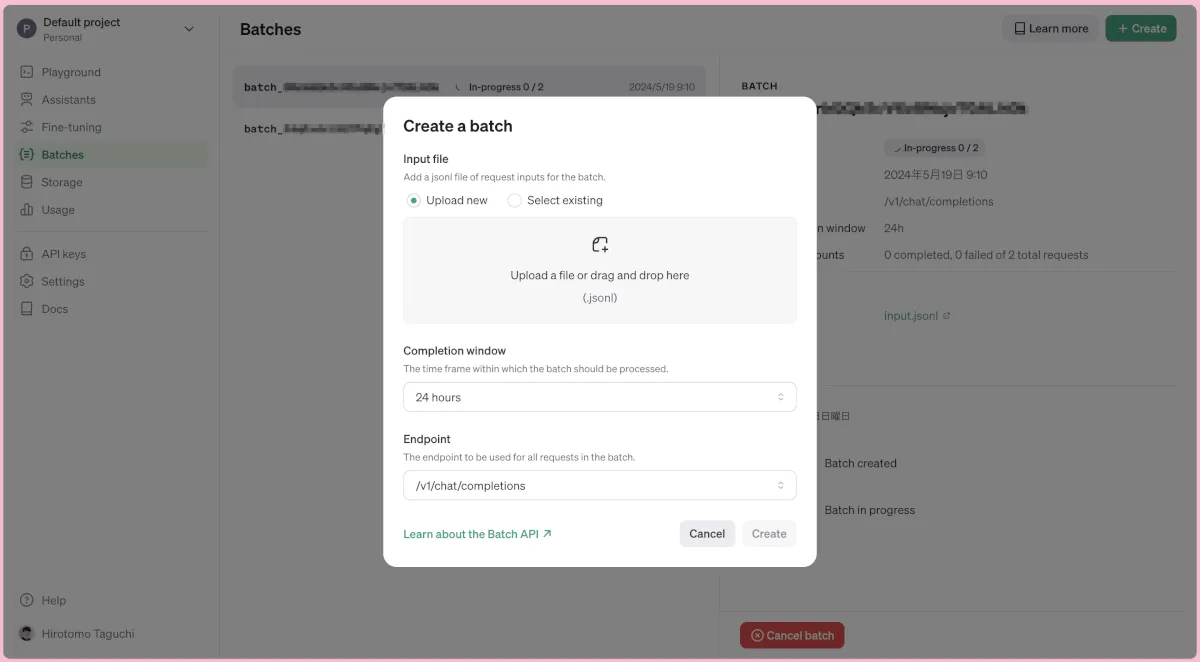
ステップ 2: ファイルをアップロードして待つ
先ほど、作ったファイルをOpenAIのBaches(https://platform.openai.com/batches/)にアップロードします。前提条件にも記載しましたが、OpenAIのアカウントを作成し、クレジットカードを登録しておく必要があります。
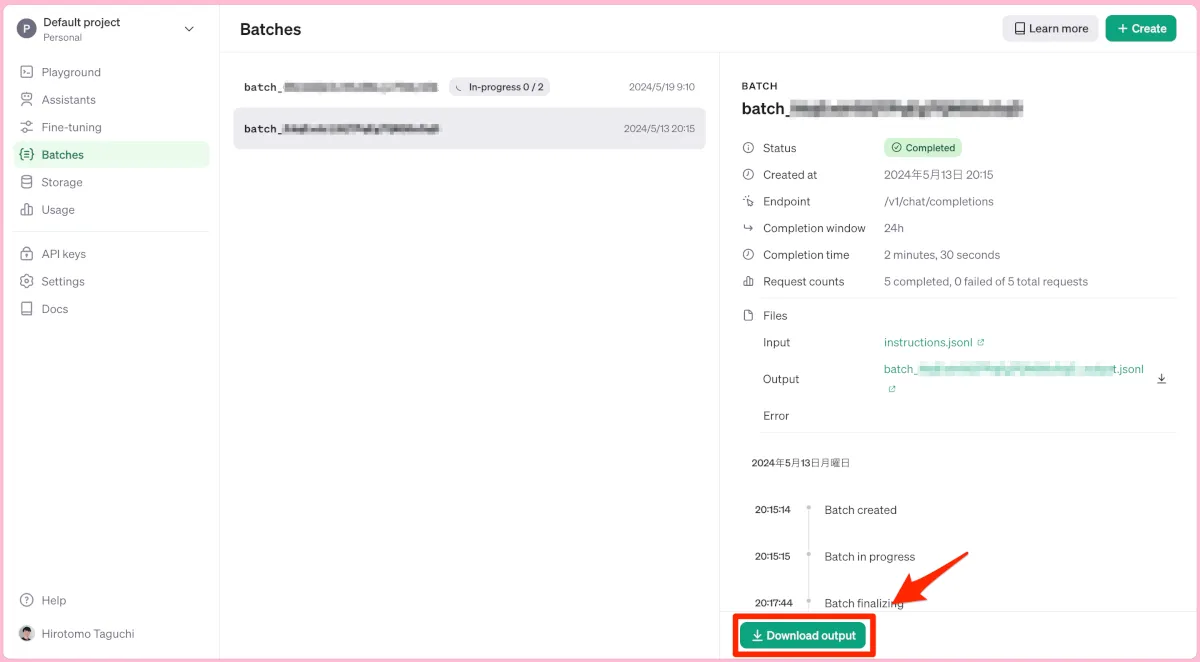
ステップ 3: 結果の受け取り
しばらく時間が立って、OpenAIの管理コンソールを見にいくと、処理が終わっている場合はアウトプットをダウンロードすることができます。
注意
現時点では、出力で日本語を利用すると、Unicode エスケープシーケンスという型式で出力されてしまいます。読むことができません。型式を変換(デコード)する必要があります。方法はいろいろありますが、VSCodeを利用する場合は以下のようにできます。
1. VSCode 検索機能で、正規表現をONにして\\u.{4}と検索
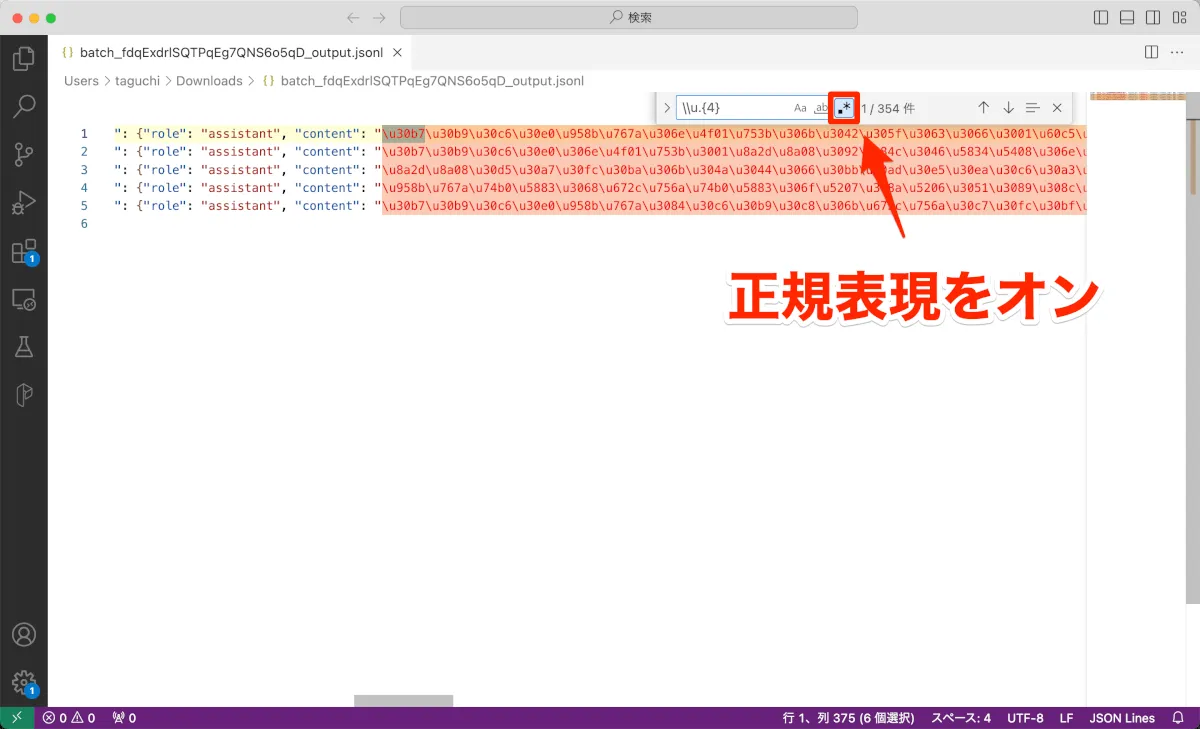
2. Windowsの場合はalt + enter を押して検索された部分を全選択する。(Macの場合は option + returnを押して検索された部分を選択する)
3. Windowsの場合は ctrl + alt + c を押して、メニュを開き [Unicode to String] を選択する。(Macの場合は cmd + option + Cを押して、メニュを開き [Unicode to String] を選択する。)
ややめんどくさいので、英語で出力して、エクセル関数で翻訳すると、変換が不要となり最終的には楽かもしれません。
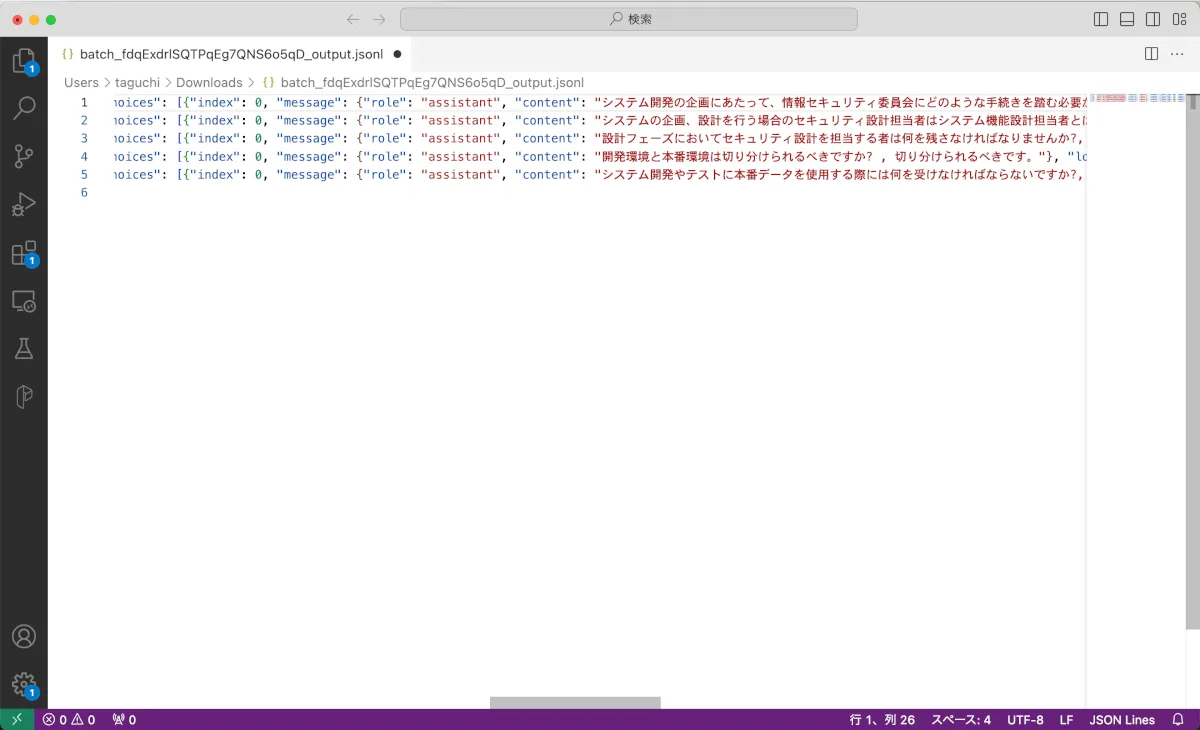
最終的なアウトプットも下記のようにJSONL型式で受け取れます。リクエストの際に指定したrequest id にマップされて、結果を閲覧することができます。
刺さりそうなユースケース
やはり、Batch API の最大の特徴は、大量のリクエストを一度に送信し、結果を後でまとめて取得できる点ですので、大量のデータを一度に処理する必要がある場合や、リアルタイム性が求められないバックグラウンドのタスクに最適です。具体的には以下のようなタスクが考えられます。
- テスト用のデータセットの生成
- ベクトルDBを作成する前のベクトル化
- データへのラベル付
- 過去の問い合わせ記録をシステムから出力し、それを一括でFAQ型式に変換する
- エクセル上の大量データでブランクとなっている箇所に対して、他のセルの情報を元に情報を生成する
これは、エンジニアに限ったことではなく、非エンジニアの方々にとっても、Batch API はデータの整形や分析作業を効率化する強力なツールとなるかと考えています。
おまけ
まだこの仕組みはOpenAI社でしか提供されておらず、Azureでの提供はありませんが、Microsoft Build ではAzureでも対応すると話に上がっていたようです。まだ、MS公式ドキュメント等に反映されている箇所を見つけられていませんが、Azureでも使えるようになったらいいですね。
おわりに
僕は日常的にこれを使うことは考えてませんが、「この汚いデータを綺麗にしたい」というケースの懐刀としておきたいと思います。また、これまでだったら非エンジニアの方が大量処理をしたい場合、他の人に頼むか、1件1件コピペするか、怪しい拡張機能を使うかなどの手段が主でしたが、OpenAIが公式でこういうものを出してくれるのは良いなと感じました。ぜひ使ってみていただけたらと思います。