Workatoでアクセスしたい
Workatoについては今更あれこれと語らなくても弊社のブログを見てる人であれば割と出てくる名前なのでご存じだと思いますが
いわゆる、IPaaS(Integration Platform as a Service)です。複数のSaaS同士の連携させて業務自動化の実現するツールなのですが、大半のIPaaSがそうであるようにWorkatoも基本的にはAPIを叩いてレスポンスをJSONなりXMLなりで受け取り、組み合わせていくSaaSな訳です。
しかし、世の中にはそもそもAPIが公開していないサービスは幾らでもあって(特に日本の企業が提供しているサービスは)、それらのサービスはIPaaSだと扱えないサービスと云う事になってしまいます。
例えばMoneyForwardや郵便局、保険協会等がそのままAPIがあれば色々と捗ると思う方も多いのではないでしょうか?
はっきり言って物凄く気に入らない!
サービス間の連携を行うのなら自社で使っているサービスは軒並み連携したいじゃないですか。これは使えますこれはダメですだと極当たり前に困る。ならば、ブラウザと同じようにアクセスしてブラウザと同じようにレスポンスを受け取り値を取り出してしまうスクレイピングを行えば何とかなるのでは?
スクレイピングするカスタムコネクタを作りたい
ご存じの方も多いでしょうがWorkatoには自分で接続するサービス用のコネクタを作りサービスにアクセスが出来ます。しかし、カスタムコネクタでアクセスすれば良いとはなりません。
上で書いた通り、WorkatoはAPIにアクセスしてAPIからのレスポンスを次に繋げて行く事が前提の仕様です。当然、ログインもこの仕様に沿うので、作れてもJWTやOAuth2での認証です。一般的なWEBページのログインなど出来ません。ステートレスなので接続も保持してくれません。
カスタムコネクタでスクレイピングする際の問題点
- APIを前提にしていない認証は行えない
- 基本的にはAPIとしてJSON/XML前提なのでJSONかXMLでないと値の取得が難しい
- ステートレスなのでセッション情報は保持してない
- HTMLはパース出来ない
- Rubyを使用できるが基本的な基本的なRubyのメソッド・ステートメントのみでGEM等でインストールするライブラリは使用出来ない
何なら出来る?
- HTTPリクエストは行える
- HTTPリクエストのレスポンスはJSONやXMLでなくても取得はできる
- JSON、XML、CSVのパースは行える
- 極一部、基本的なRubyのメソッド・ステートメントを使用できる
はい、割とキツイです。
特に赤字で書いたところは本当に厳しいですがRubyなのでNokogiriが使えれば楽なのですが残念なことにライブラリは使えません。これらを前提にスクレイピングして値を返却させなければいけません。
Workatoのカスタムコネクタの認証部分
Workatoのカスタムコネクタの認証部分であるconnectionはauthorization内のacquireを実行してリダイレクションの結果をapplyで受け取り、applyの返却値をコネクタ内の変数connectionに格納しtestを実行して正常にレスポンスが返れば接続完了です。
一般的にはacquireで認証を実行しapplyでBearer-Tokenを取得、Bearer-TokenをHTTPリクエストのヘッダとしてを変数connectionに格納されて保持し各所で行われるHTTPリクエスト時にこの値を使いまわします。
Workatoのコネクタはこの接続処理を行わないと始まりません。しかし、今回はこのconnection処理に頼れません。ブラウザで行われるWEB画面上のログインだからです。
コネクタの認証部分をどうするか?
簡単です。Workatoのconnection処理でログインしません。WEB画面上のログインは一般的にはCookieとセッションで行われるので、前提が異なるOAuth2の流れに乗せても上手くいかないからです。
そもそも一般的なWEBログインって?
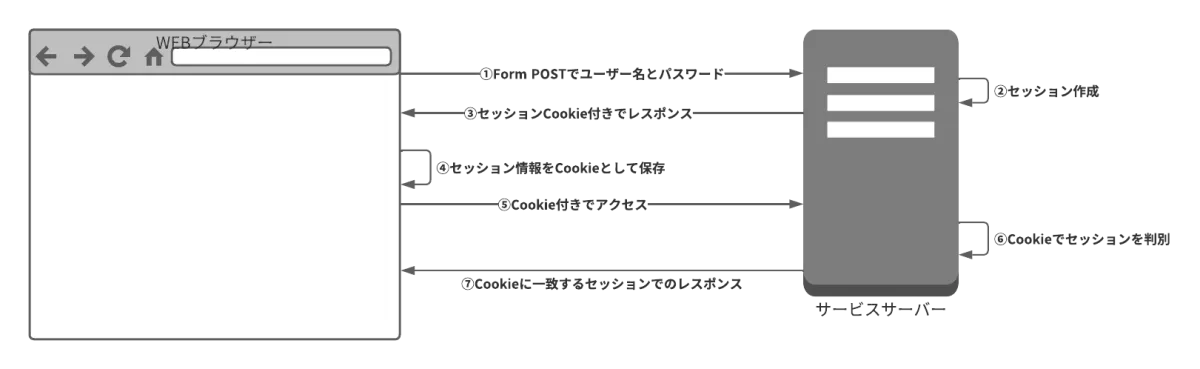
- ブラウザーはユーザーにログインIDとパスワードを入力させてサーバーに投げる
※ 大体はFORMリクエストでPOSTされる - サーバーはリクエストされたユーザー情報でブラウザーとセッションを確立する
- サーバーはレスポンスとしてセッション情報をCookieに乗せて返却
※ HTTPレスポンスヘッダーにSet-Cookieとして情報が返る - Set-Cookieを受け取ったらブラウザーはCookie情報をブラウザー内部でサイト毎に保存しておく
- 次にアクセスする際に保存しておいたCookieがリクエストに付与される
※ HTTPリクエストヘッダーにCookieとして付与 - サーバーはリクエストに乗ったCookieの情報からユーザーセッションを判定
- セッションがログイン済みであればレスポンスを返す。
※このレスポンスでもSet-Cookieが返却されブラウザーはCookieを上書き保存します
ざっくりと一般的なログインはこのような流れになる。
もちろんFORM POSTでなくGETで投げている場合や、ログインIDとパスワードを別々に投げる場合もあるし、途中でリダイレクトする場合もあるが、概ね、この流れのHTTPリクエストを再現してあげれば、ブラウザーでログインした際のレスポンスが取得できます。
Cookieをどうするの?
HTTPリクエストを再現するには、まず、Cookieをどうするのか?を考えないといけません。Cookieを無視してリクエストを投げるとログインしてないと認識されてサービス側のサーバーからログイン画面に飛ばされ続けます。
カスタムコネクター内部にCookieは保存出来ない上に、変数connectionに値として保存するとコネクタの接続時とrefreshの際にしか変更出来ないのでここには保存出来ません。では何処にどの様に保管すればよいか?
はい。クラウドストレージです。
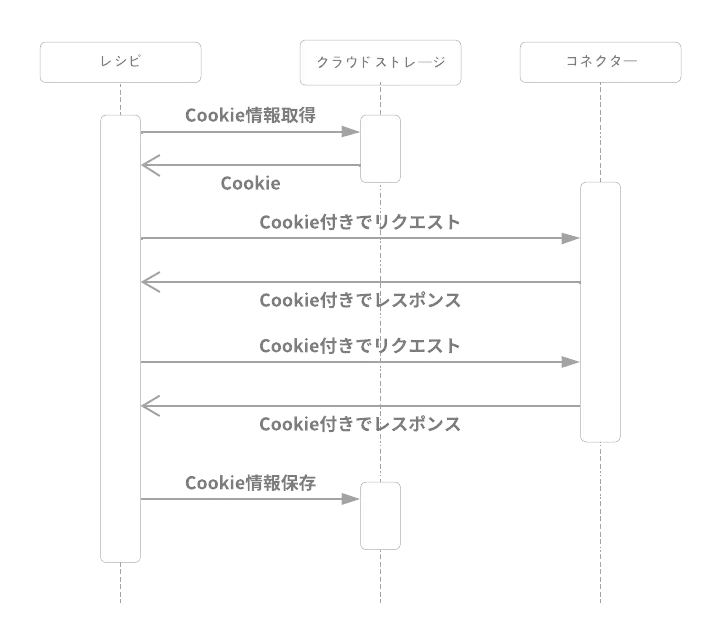
つまり、カスタムコネクタ内に保存しなければ問題はない訳です。カスタムコネクタの各アクションからのレスポンスにて返却されたSet-Cookieの内容を最終的にGoogleDriveにでもBoxにでも保存し、再度、呼び出される際に読み出して使用すれば継続的にCookieの保存が出来ます。
もちろん、Cookieはそのままだと扱い難いので一度パースしたりフォーマッティングしたりして値を読めるようにしておきます。
しかし、WorkatoのRubyのメソッド群にはCookieを扱うものはないので、もちろん自前で作成します。内容としてはこうです。
parse_cookie: ->(cookies, orgs){
if orgs == nil
orgs = {}
end
if cookies != nil
cookies = workato.parse_json(cookies)
cookies.each{ | c |
record = {}
c = c.split(";")
first = true
c.each{ |cookie|
cookie = cookie.split("=")
key = cookie[0]
value = cookie[1]
if value == nil
value = ""
end
key = key.strip
value = value.strip
if first == true
record["name"] = key
record["value"] = value
first = false
else
record[key] = value
end
}
orgs[record["name"]] = record
}
end
orgs
},
format_cookie: ->(cookies){
result = []
if cookies != nil
cookies.each{| key, record|
value = record["value"]
name = record["name"]
result.push("#{name}=#{value}")
}
end
result = result.join("; ")
result
},
これで保存する際はJSON構造にしてテキストファイルとして保存し、使用する時はテキストからHTTPヘッダーの形に相互変換できます。これで、ログインとCookieの保管に関する問題が解決です。
HTMLを受け取らないとはじまらない
前述の通りWorkatoはAPIを前提にして作られているので、JSONのレスポンスを前提にそのままgetやpostを呼び出してもレスポンスはJSONパースしようとするし、HTTPレスポンスヘッダーは返ってこないし、300番台のレスポンスが返ると問答無用でリダイレクトされます。
ですので、HTTPリクエスト用に内部でメソッドを纏めておいた方が無難です。
get: -> (connection, url, cookies, referer, query, header) {
get(url).
headers(header.merge({
"Connection" => "keep-alive",
"Cookie": call(:format_cookie, cookies),
"Referer": referer
})).
params(query).
response_format_raw.
ignore_redirection.
after_response { |code, body, response_headers|
:
:
:
}
}この辺りはWorkatoのSDK Referenceを参考にしてください。
headersにCookieを追加、response_format_rawにてHTTPのレスポンスをそのまま受け取るように宣言しignore_redirectionで300番台のリダイレクションを抑制しています。
後はafter_responseでHTTPのステータスコード、Body、レスポンスを受け取って処理するだけですね
HTML受け取った後どうしろと?
はい、ある意味最難関です。
何故ならWorkatoにはHTMLのパーサーがありません。after_responseで返って来るのはただのHTMLのテキストデータです。ここは頑張りどころですね。
HTMLをパースする
要するに自分でパーサーを書けば良いのです。
HTMLを構文解析してしまえば良い。幸い、Workatoでは、scanもgsubもarrayもhashも基礎的なRubyの構文なら使えます、ではどの様な考え方でHTMLを構文解析するのか?
- HTMLは開始タグと終了タグの中にインナーテキスト、もしくは子タグがある
- 開始タグの終端が/で終わった場合、終了タグは記述されない
- 開始タグの終端が/で終わらない場合は必ず終了タグが記述される
- 開始タグは<TAG>となる囲まれる
- 終了タグは</TAG>の構文になる
- 開始タグの中には属性情報が入る
- 属性情報はNAME=”attribute”の形式で書かれる
- 属性情報同士は1つ以上のスペースで区切られる
というのがHTMLの基本的な仕様です。
今回は構文解析機などは使えないので自前でこれを解析して行きます。
- 各行の行頭のインデントを削除します。
- 改行も邪魔なので削除します。
- scriptタグも必要ないので削除します。
- HTMLのコメントも削除します。
- <br>と<br/>も邪魔なので消します。
まず、下準備として1~5を行います。gsubとか使ってガシガシ消しましょう。
で、次は<>で囲まれたタグとそうじゃない文字列を見つけ出していきArrayにします。
<div class="content">
<p>テスト</p>
</div>要はこういうHTMLがあったら
["<div>", "<p>", "テスト", "</p>", "</div>"]こうします。
これを繰り返し文で回して開始文字が<か</かそれ以外か?で区分して階層番号を振ります。開始タグを見つけたら+1、終了タグを見つけたら-1でカウントして行きます。
つまり、こうなります。
1 <div class="content">
2 <p>
2 テスト
2 </p>
1 </div>ここまで来ると後は簡単です。
上から見ていきカウントが開始タグ同じ数字を持っている終了タグが対になる終了タグです。後は開始と終了の内側にあるデータは子タグとインナーテキストです。
子タグなら再帰的に呼び出してnodeとして、インナーテキストなら親タグのtextとしてぶら下げます。タグの属性情報は正規表現で個別に切り出してしまいます([^=" ]+="[^"]*")としておけばkey=”value”の構造は取れます。
[
{
"tag": "div",
"attr": [
"class": "content"
],
"node": [
{
"tag": "p",
"text": "テスト"
}
]
}
]最終的にはこのような形にします。
この状態の構造であれば簡単にwhereで絞り込みながら探していけます
後は淡々とActionを実装しリクエストを投げてレスポンスをパースして値を返すように作り込み続けるとWorkatoのカスタムコネクタのみで動くスクレイパー実装コネクタが出来上がります。
正直、物凄く面倒ですが、WorkatoのコネクターからAWS LambdaやAzure Functionsを呼び出すよりはオーバーヘッドは小さいと思われます。
まとめ
車輪の再発明の車輪の再発明みたいな変態的な話だけれど、出来ませんって諦めるより、昔ながらの無きゃ作りゃ良いんだよ!!精神です。でもやっぱり、当たり前だけれどHTMLの構成変えられるとやり直しになる…
創造はメンテの始まりなのは覚悟完了しててくれ!
一定のメンテナンスが任せれるというのがマネージドサービスの良い点だから皆、サービスを作る時はAPI作ってくれ!
頼むから!お願いだから!