どうも おかしん です。
推論モデルって、みんな理解して使っていますか?
ChatGPT、Claude、Gemini、Codex などを使っていると、推論に任せたほうが強い、thinking を使ったほうがいい、逆にこのタスクは非推論モデルに投げた方がいい、といった話を見かけることがあります。
なんとなく意味は分かります。普通のモデルより、じっくり考えてくれそう。難しいタスクに強そう。コードや設計に向いていそう。
でも、正確に理解していないという人は多いんじゃないでしょうか。
- そもそも推論とは何なのか
- 推論モデル以前のモデルと何が違うのか
- Claude の Sonnet や Haiku は推論モデルなのか
- Codex はモデルなのか、エージェントなのか
- 推論があるなら、AIへの任せ方をどう変えればいいのか
この記事では、推論とは何か、推論モデルはどのように使うのがよいのかを整理します。
そもそも推論とは何か
推論は英語では reasoning です。分かっていることをもとに、まだ分かっていないことを導くことです。
たとえば、前提、観察、条件を組み合わせて、こう考えるとこの結論になりそうだ、と筋道を立てる行為です。計算問題を解くときも、トラブルの原因を探るときも、複数の選択肢を比べるときも、私たちは何かしら推論しています。
AIにおける推論も、まずはこの延長で捉えると分かりやすいです。
推論モデルとは何か
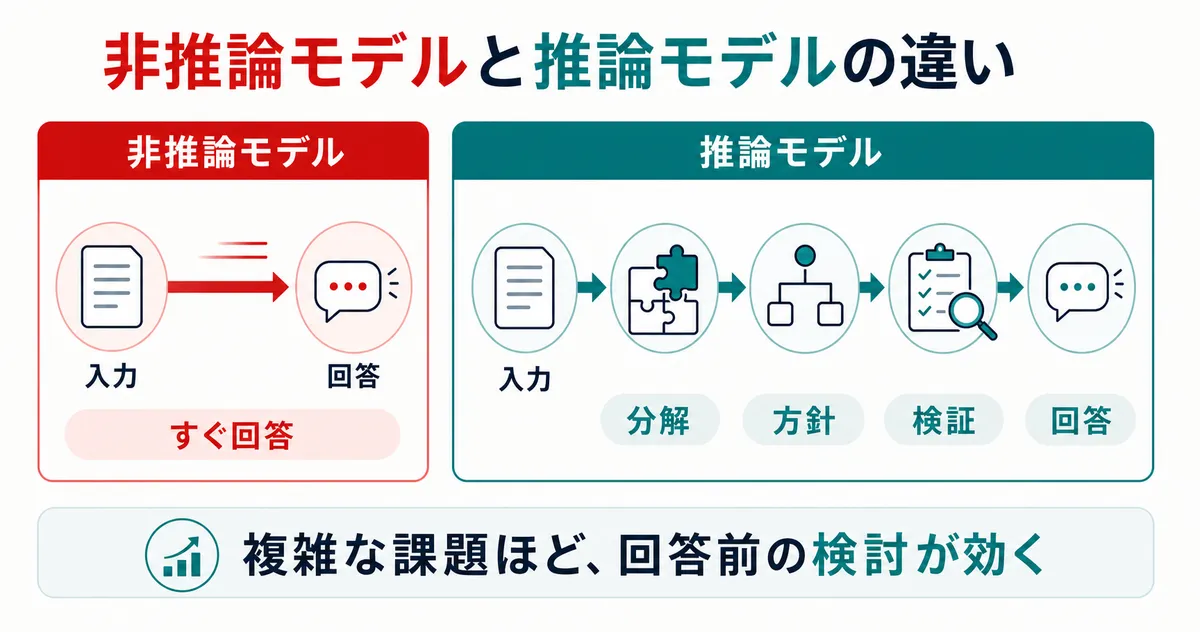
非推論モデルは、入力に対して比較的すぐに最終回答を生成するモデルです。これに対して推論モデルは、最終回答を返す前に、内部で問題を分解し、方針を立て、必要に応じて検証しながら回答を導くモデルです。
AIが考えるようになった、と言われることもありますが、「考える」は比喩です。人間と同じ内面があるという話ではありません。OpenAI の Reasoning models、Claude の extended thinking、Gemini の thinking も、回答前の内部検討をユーザーや開発者が扱える機能として説明しています。その結果として、応答までの時間や reasoning / thinking tokens が増えることがあります。
OpenAI が 2024年9月に公開した OpenAI o1-preview は、この流れを製品として強く印象づけたモデルでした。OpenAI は o1 を、応答前により長く考えるよう設計したモデルとして説明しています。
ただし、研究の流れとしてはそれ以前からあります。2022年の Chain-of-Thought Prompting や Large Language Models are Zero-Shot Reasoners では、中間的な推論ステップを出させることで、算術、常識推論、記号推論などのタスク性能が改善することが示されていました。
つまり、歴史を分けるとこうです。
| 観点 | 代表的な流れ |
|---|---|
| 研究上の起点 | Chain-of-Thought など、モデルに中間推論ステップを出させる研究 |
| 製品としての転換点 | OpenAI o1 以降、推論モデルという言葉が一般ユーザーにも見える形で広がった |
| 現在の使い方 | reasoning effort、extended thinking、thinking budget などで、考える量を調整する |
推論モデル以前は何が違ったのか
推論モデル以前のAIが、まったく推論していなかったわけではありません。
以前から、プロンプトで、順番に考えてください、前提を整理してから答えてください、と頼めば、モデルはそれらしい手順を出してくれました。実際、Chain-of-Thought 系の研究も、そうしたプロンプトの力を示したものです。
ただし、推論モデルでは、回答前に内部で検討する仕組みが、モデルやサービス側の機能として組み込まれてきました。OpenAI API の Reasoning models では reasoning.effort によって、その検討の深さを調整できると説明されています。高い effort は品質や信頼性を上げやすい一方、遅くなり、トークン使用量も増えます。
ここが重要です。
推論モデルは、単に賢いモデルではありません。難しい問題に対して、最終回答の前に問題分解や検証を挟むモデルです。
だから、いつでも推論を強くすればよいわけではありません。簡単な分類、短い翻訳、形式変換、定型的な要約では、速いモデルで十分なこともあります。
Claude、GPT、Codex、Geminiではどう見ればよいか
推論という言葉は、各社で少し違う形で見えます。ここでは優劣ではなく、使う側から見た違いだけ整理します。
| 対象 | 推論の見え方 |
|---|---|
| Claude | extended thinking や effort |
| GPT | reasoning model / reasoning effort |
| Codex | 推論モデルを使うエージェント体験 |
| Gemini | thinkingBudget / thinkingLevel |
Claude
Claude については、Claude の Help Center で、extended thinking は問題分解、計画、複数アプローチの検討に時間を使う設定として説明されています。Sonnet や Haiku はあくまで Claude のモデル階級です。Sonnet だから推論、Haiku だから非推論、のように単純には分けられません。
GPT
GPT については、o1 が分かりやすい転換点でした。現在の OpenAI API では、モデルによって none、minimal、low、medium、high、xhigh などの effort が扱われます。つまり、推論は使うか使わないかだけでなく、どのくらい使うかの問題にもなっています。
Codex
Codex は少し別枠です。OpenAI は Codex を、クラウド上で複数のソフトウェアエンジニアリングタスクを並列に実行できるエージェントとして説明しています。コードを書く、質問に答える、バグを直す、テストを実行する、といった一連の作業を任せる体験です。なので、Codex は推論モデルかどうかというより、推論モデルを使って作業を進める仕組みとして見た方が分かりやすいです。
Gemini
Gemini では、Gemini API の thinking で、Gemini 2.5 系は thinkingBudget、Gemini 3 系は thinkingLevel を使うと説明されています。Google のドキュメントでは、thinking が有効な場合、出力トークンだけでなく thinking tokens も料金に関わることが示されています。
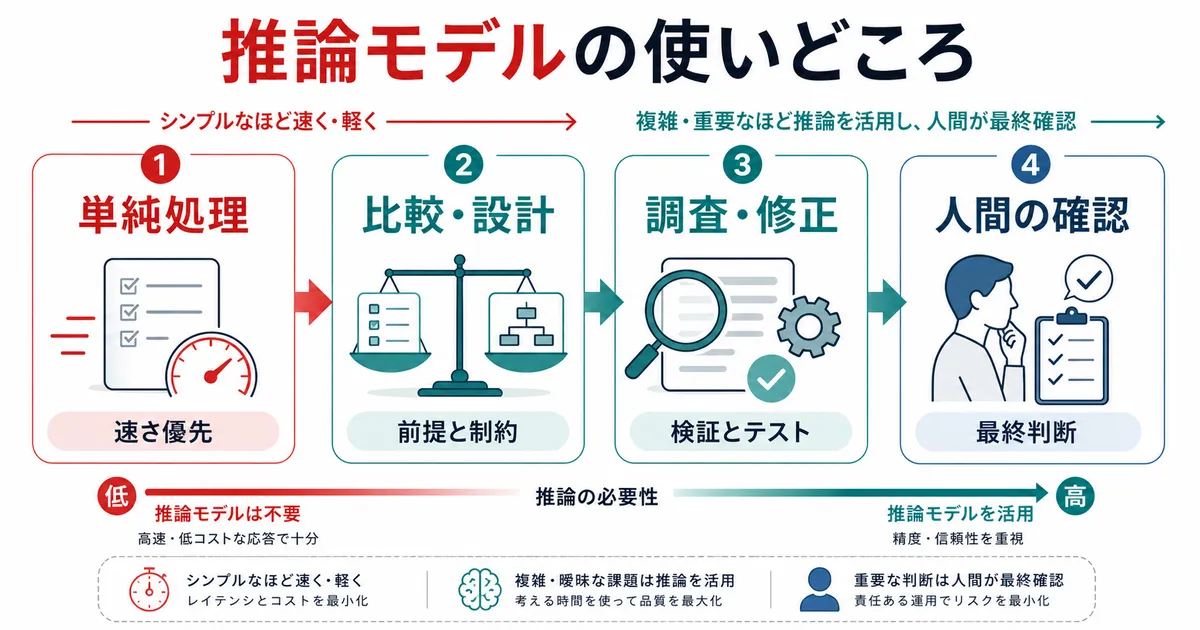
推論モデルが得意なこと、苦手なこと
推論モデルが強いのは、答えが一発で出ないタスクです。
たとえば、次のようなものです。
- 複数の制約を満たす設計を考える
- 選択肢を比較し、前提やトレードオフを整理する
- コードの原因調査、修正方針、テスト方針を考える
- 長い文書を読んで、論点や矛盾を整理する
- 作業手順を立て、途中で検証しながら進める
こういうタスクでは、すぐ答えを出すよりも、前提を整理する、分解する、失敗パターンを考える、一度出した案を検証することに価値があります。だから推論が効きます。
一方で、推論モデルがいつでも最適とは限りません。
- この文章を短くして
- このJSONを整形して
- このメールが会議依頼かどうか分類して
- この文章を英訳して
- この定型文を少し丁寧にして
こうした作業では、深い検討よりも速度やコストが重要です。推論を強くしても、体感品質があまり変わらないことがあります。むしろ遅く感じたり、不要に大げさな回答になったりします。
以前 AIが安く使える時代は長くは続かない でも書いたように、AI利用では処理にかかる時間やトークン、コストの感覚も重要です。推論は便利ですが、タダではありません。時間もトークンも使います。
個人で使っていると、サブスクリプションの範囲内で、軽いタスクにも強い推論モデルを選びがちです。それ自体が悪いわけではありません。ただ、社内の業務に密接に結びつくエージェントを作る場合は、回数、待ち時間、レート制限、費用を考える必要があります。
そうなると、すべてを推論モデルに任せるのではなく、一部の分類、整形、下処理、短い確認を非推論モデルや軽いモデルに任せる選択肢が出てきます。普段から使っていないモデルは、いざ選ぼうとしても感覚がありません。スキルやワークフローの一部で軽いモデルを使ってみると、どこまで任せられるか、どこから推論が必要になるかの肌感覚を持ちやすくなります。
使うときに意識したいこと
推論モデルを使うときに大事なのは、推論に任せることと丸投げすることを分けることです。
推論に任せるとは、次のようなことです。
- 目的を伝える
- 前提条件を伝える
- 制約を伝える
- 判断基準を伝える
- 失敗したら困ることを伝える
- 最後に検証してほしい観点を伝える
逆に、丸投げはこうです。
いい感じに考えて。
これでも返ってはきます。ただ、推論モデルが強いのは、与えられた問題を分解し、検討し、検証するところです。何を大事にしてほしいかを渡さないと、モデルはそれっぽい一般論を組み立てるだけになりやすいです。
私の感覚では、推論モデルには答えよりも進め方を渡す方が向いています。
これは以前の AIを使うのが上手い人は、プロンプトではなく進め方を設計している ともつながります。推論モデルが強くなるほど、プロンプトの言い回しだけでなく、どの順番で考えさせるか、どこで検証させるか、どこを人間が判断するかが大事になります。
たとえば、コード調査ならこうです。
- まず関係しそうなファイルを探す
- 仕様と実装の差分を整理する
- 修正案を複数出す
- 影響範囲を確認する
- テストを実行する
- 失敗したら原因を再検討する
Codex のようなエージェント体験では、この流れがより分かりやすくなります。単に質問に答えるのではなく、作業環境の中で調べ、変更し、テストし、結果を確認するからです。以前書いた Codexのコンテキスト圧縮が超優秀な件について でも、長い作業を続けるうえで文脈管理が重要になることに触れました。
推論モデルを使うときは、次のように考えると分かりやすいです。
| タスク | 推論に任せる価値 |
|---|---|
| 単純な変換、分類、短い要約 | 低い。速さを優先する |
| 比較、設計、原因調査 | 高い。前提と判断基準を渡す |
| コード修正、長い調査、複数ステップの作業 | 高い。手順、検証、テストまで任せる |
| 正確性が重要な判断 | 高いが、人間の確認、一次情報の照合、複数視点での検証を残す |
推論モデルは、AIにすべてを任せるためのものではありません。むしろ、人間が何を考えるべきかを渡したときに強くなります。
まとめ
推論モデルとは、回答前に問題を分解し、検討や検証を経てから回答を生成するモデル、またはその使い方です。
以前のモデルでも、プロンプトで段階的に考えさせることはできました。そこから、o1 のような reasoning model、Claude の extended thinking、Gemini の thinkingBudget / thinkingLevel、Codex のようなエージェント体験へと、推論はユーザーから見える機能になってきました。
ただし、推論モデルは必ず正しいモデルではありません。推論を長くすれば、常に良い答えになるわけでもありません。
大事なのは、どの作業を推論に任せると強いのかを見極めることです。
単純な作業は速く処理する。複雑な作業は、前提、制約、判断基準、検証観点を渡して推論に任せる。そして、重要な判断は人間が確認する。
推論モデルをそう捉えると、なんとなく賢そうなモデルではなく、AIへの仕事の渡し方を変えるための道具として使いやすくなると思います。