はじめに
こんにちは。最近 Azure 触るのが楽しい Identity チームの すかんく です。
Azure OpenAI Service で自社データを含めた検索・回答生成を行う際、検索対象となるデータをフィルタすることが出来るようなので試してみました。
本記事内では極力平易な言葉を用いることで、誰でも読みやすい内容にすることを意識して執筆しております。 そのため、各サービス・機能の解説が不十分であったり、ニュアンスとして不適切な表現が含まれる場合があるかと思いますが、ご容赦いただけますと幸いです。
TL;DR
- 従来、生成 AI に自社データを取り込んだ場合、元データのアクセス権を意識したデータ選択や回答の生成が困難だった
- 新しく、Azure OpenAI Service で自社データを利用する際に、検索対象とするデータのフィルタが可能になった
- 検証した結果、フィルタ機能を適切に運用するためには元データを含めた全体のデータ・ライフサイクル管理が重要だと感じた
生成 AI での自社データ活用における大きな課題
生成 AI と自社データを連携することで、業務改善・効率化されている企業様は多くいらっしゃると思います。
弊社でも類似チケット検索システムをはじめ、様々な機能を検証・リリースしております。
- 詳しくは 【Public】AI 組み込みシステム開発タスクボード をご確認ください
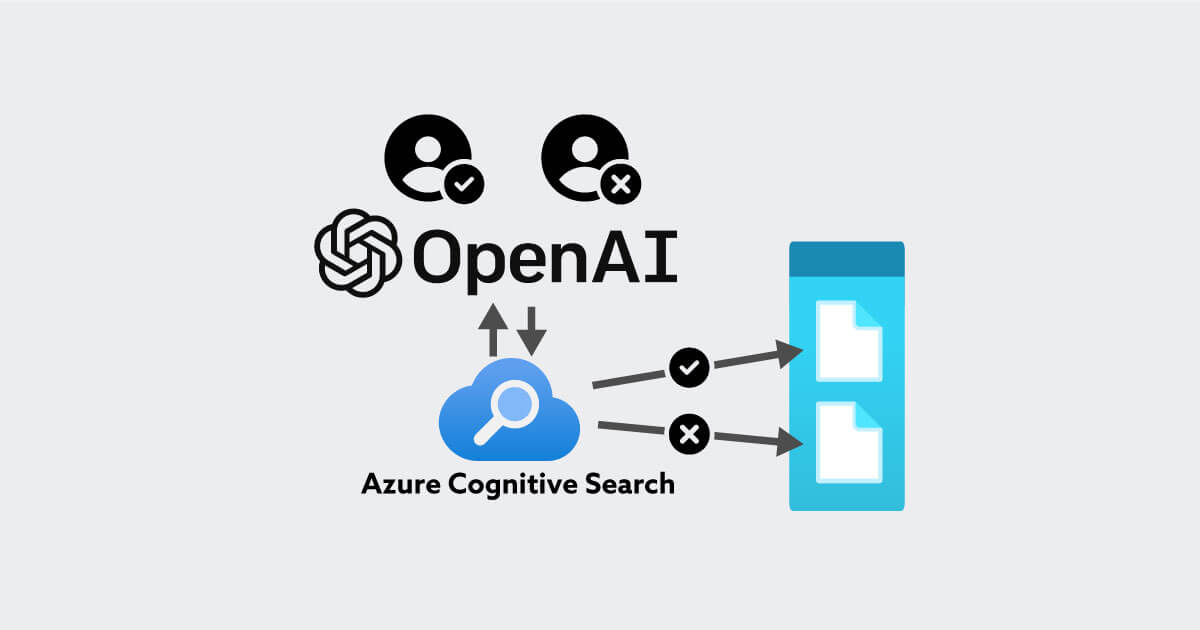
全社規模で生成 AI に自社データを学習させることを本気で考え始めると、まず最初に大きな壁として立ちはだかるのが、「生成 AI はインプットした自社データが元々保持していたアクセス権を意識した回答が出来ない」という点です。
極端な例を挙げると、元データが特定のユーザーのみ閲覧・編集可能だった場合でも、生成 AI を介してしまえば誰でも情報にアクセスできてしまうリスクが生じることになります。(イメージ図として以下をご確認ください。)
この問題は頻出ケースである「コンシューマ向け生成 AI サービスで入力されたプロンプトが学習に再利用される」みたいな話と本質的には同等と考えています。(データの利用範囲が “to B/C” か “社内サービス” かの違い)
クラウドネイティブ社内の検証チームでは、上記課題に対して複数のアプローチによるリスク低減・問題解決を模索していました。
以下がアプローチの具体例となりますが、いずれも一定の効果は見込めるものの、根本的な解決策とはなり得なかったり、実装・運用コストが見合わない等の問題がありました。
[具体例]
- 生成 AI に関連する機能を開発する際は、必ずデータ流通経路に関する検討・評価を行う
- まずストレージから利用者のコンテキストでデータ検索を行い、取得したデータを生成 AI に受け渡す
- 学習させるデータセットを利用範囲(公開・公開+社外秘・公開+社外秘+関係社外秘)毎に準備して、利用者に応じて利用データを変更する
※本記事では上記施策に関する解説は含まれません。話を聞いてくださる方は是非お問い合わせください。
そんな中 Azure OpenAI Service が自社データのフィルタ機能を提供した
上記のような背景もあり、「Azure OpenAI Service で自社データを利用する際、利用データをフィルタできるようになったらしい」というニュースは自分にとって大きな期待を寄せるものでした。
手順・動作の確認
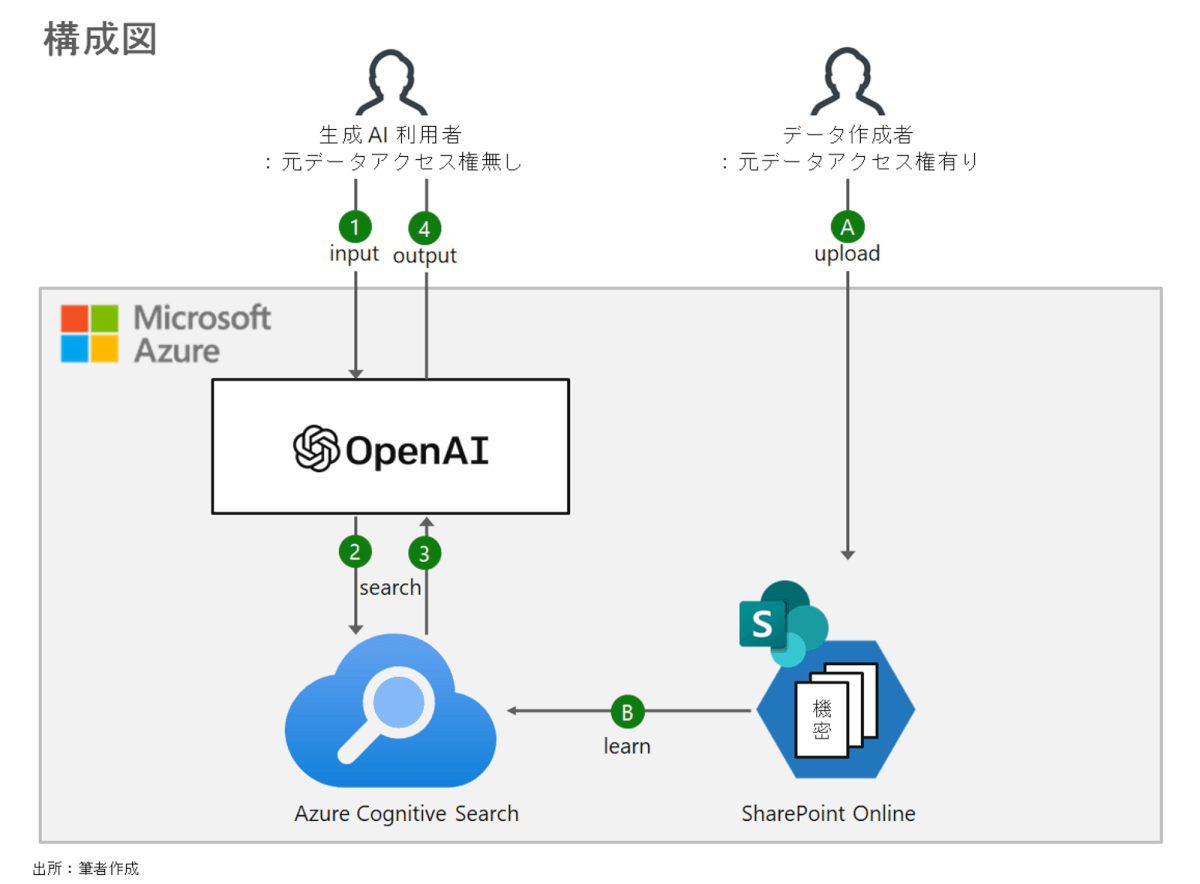
ここからは実際の手順・動作の確認をしていきます。まず公式ドキュメントの内容を要約すると以下になります。
- インデックスにフィルタ用のデータフィールドを用意する
- ドキュメントにフィルタ用データを付与する
- 検索時にフィルタパラメータもセットで引き渡す
公式ドキュメントでは Azure OpenAI Studio の利用手順が丁寧に記載されているため、本記事では API による動作確認をしてみたいと思います。
今回は作成済みのインデックスを利用します。インデックスが未作成の場合、以下ブログの [Azure Cognitive Search で検索用のインデックス作成] の章を参考に前準備をお願いします。
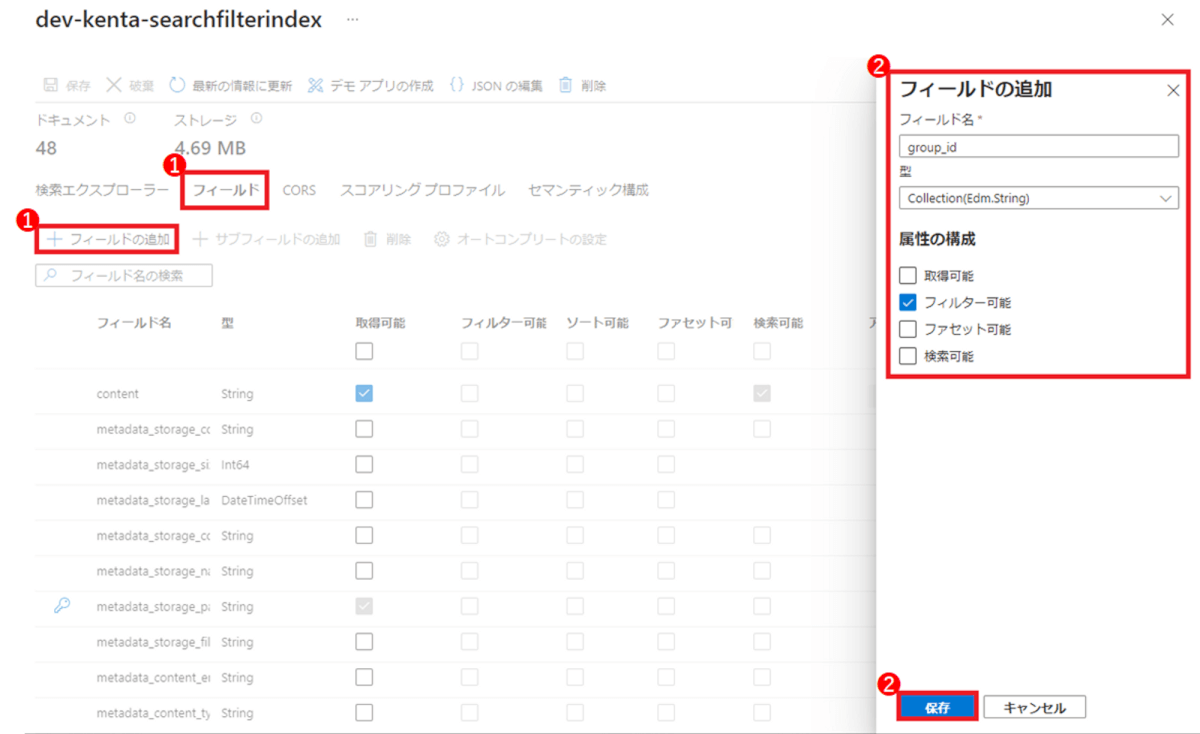
インデックスにフィルタ用のデータフィールドを用意する
① 作成済みインデックスの [フィールド] から [+フィールドの追加] をクリック
② [型: Collection(Edm.String)]、[属性の構成: フィルター可能] を選択し、[保存] をクリックする
ドキュメントにフィルタ用データを付与する
① 以下形式で API リクエストを行い、ステータスコードが 200 で応答されたことを確認します
※ 今回は Azure AD に作成されたグループを想定したフィルタ用データを付与します。
※ <>の記載は適宜置き換えてください。
POST https://<cognitive service name>.search.windows.net/indexes/<index name>/docs/index?api-version=2023-07-01-Preview
"headers": {
"Content-Type": "application/json",
"api-key": "<cognitive service api key>" // [Cognitive Serach] > [キー] > [プライマリ管理者キー]
},
"body": {
"value": [
{
"@search.action": "merge", // or "mergeOrUpload"
"<key field name>": "<key field value AAA>", // インデックスのキーフィールドと値
"group_id": [
"<Group Object ID 11>, <Group Object ID 22>" // ex)Azure AD Group Object ID 11 and 22
]
}
],
"value": [
{
"@search.action": "merge", // or "mergeOrUpload"
"<key field name>": "<key field value BBB>", // インデックスのキーフィールドと値
"group_id": [
"<Group Object ID 11>, <Group Object ID 33>" // フィルタ用データ ex)Azure AD Group Object ID 11 and 33
]
}
]
}
検索時にフィルタパラメータもセットで引き渡す
① 以下形式で API リクエストを行い、ステータスコードが 200 で応答されたことを確認します
POST https://<open ai service name>.openai.azure.com/openai/deployments/<deployment-id>/extensions/chat/completions?api-version=2023-06-01-preview
"headers": {
"Content-Type\\t": "application/json",
"api-key": "<open ai key>",
"chatgpt-key": "<open ai key>",
"chatgpt-url": "https://<open ai service name>.openai.azure.com/openai/deployments/<deployment-id>/chat/completions?api-version=2023-06-01-preview"
},
"body": {
"dataSources": [
{
"parameters": {
"endpoint": "https://<cognitive service name>.search.windows.net",
"indexName": "<index name>", // 検索対象のインデックス
"key": "<cognitive service api key>", // [Cognitive Serach] > [キー] > [プライマリ管理者キー]
"roleInformation": "<system message>", // 無くてもok
"topNDocuments": "1", // 手順通り進めているとフィルタ結果のデータ数が最低5コンテンツ(デフォ値)必要なためエラー
"filter": "group_id/any(g:search.in(g, '<Group Object ID 11>, <Group Object ID 22>'))" //設定したフィルタ用データ、単データでも可
},
"type": "AzureCognitiveSearch"
}
],
"messages": [
{
"content": "<prompt>", // フィルタされたデータがヒットするようなプロンプトを入力
"role": "user"
}
]
}
応答サンプル(振る舞いとしては通常の completions-extensions と同じ)
使ってみた感想
「自社データの生成 AI 活用」がより身近になってきた
今回の検証を通じて、自社データを扱う上で一番最初に立ちはだかる壁とも言える「アクセス権を意識した実装」について、大きな手札が加わったと確信しました。
今後、検索フィルタのデザインパターンが活発に検討・発信されていくことで、より自社データの生成 AI 活用が推進されるのではないかと思います。
「フィルタに使うデータの管理どうしよう、、、」やっぱりデータ・ライフサイクル管理は必要
良好な手ごたえを感じたのは確かですが、本番環境想定でフィルタ機能を運用するためには何点か検討課題が残ったと考えています。
例えばユーザーインターフェース(SlackやTeams、Web App等)によるリクエストから、フィルタに使うデータをどのように抽出するか検討が必要です。または、ストレージの移動等によって元データのアクセス権に変更が出た場合、出来るだけ低遅延でフィルタ用フィールドへのデータ更新が必要そうです。
本気で考えるほど、結局は生成 AI 活用もデータ・ライフサイクル管理なんだなぁと感じる今日この頃です。
著者の妄言:ユーザーコンテキストで動作する SaaS 提供生成 AI との関係性
このような課題を前に試行錯誤している内に、各社が持つデータストレージに対してエンドユーザーのコンテキストでデータ検索するような SaaS ベンダー提供の生成 AI サービスが登場すると考えています。(代表例:Microsoft 365 Copilot や Box AI など)
これら SaaS ベンダー提供の生成 AI を直接、またはアドインや IPaaS 等を介してユーザーインターフェースから利用する、というのが近い将来のトレンドになっていくのかなと推察(妄想)しています。これはこれで楽しみな未来像です。
おわりに
今回検証した Azure OpenAI における自社データのフィルタ機能は今後確実に利用されていくものだと感じました。
クラウドネイティブは引き続き生成 AI に関する情報発信をしていきます。ではまた!
参考
・Document-level access control

・Security filters for trimming Azure Cognitive Search results using Active Directory identities
・Security filters for trimming results in Azure Cognitive Search