ある日、Zoom OAuth の処理中に次のようなレスポンスが返ってきた。
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
<hr><center>cloudflare</center>
</body>
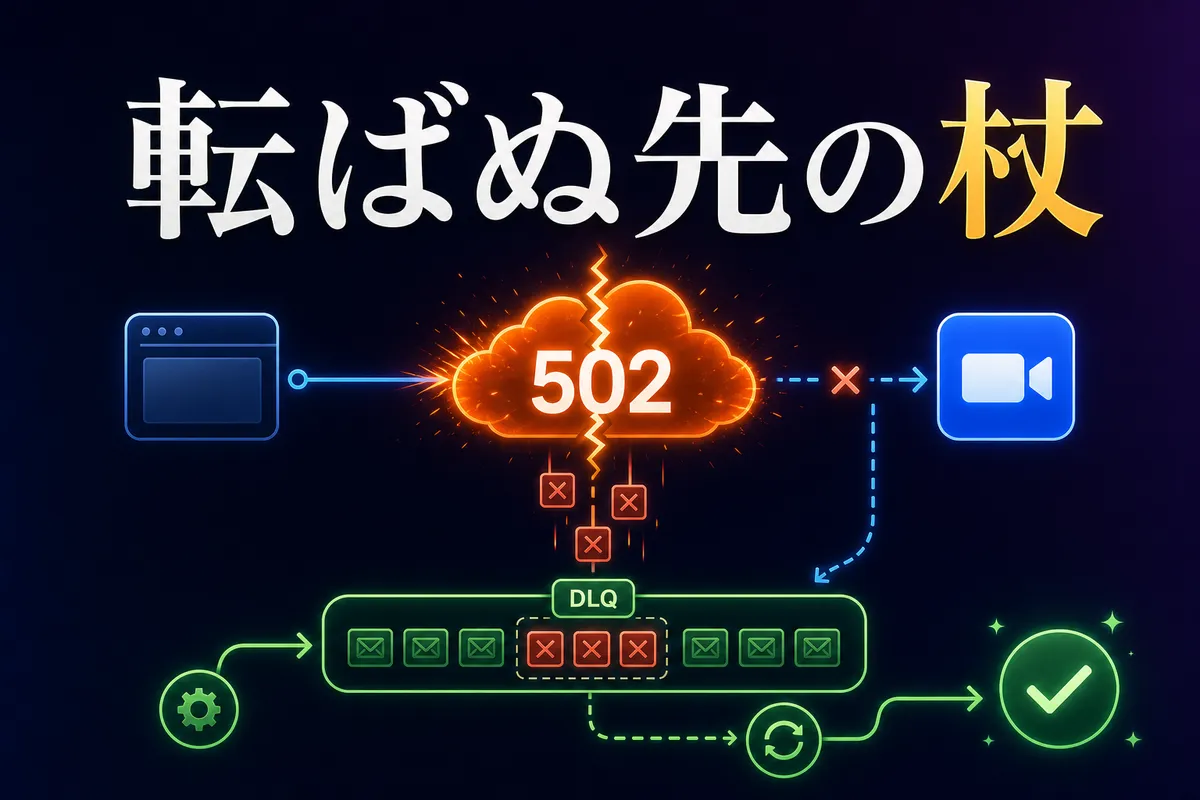
</html>HTTP 502 Bad Gateway。レスポンスボディの末尾に cloudflare とあるので、障害の起点は自前のアプリケーションではなく、Cloudflare 側(あるいは Cloudflare から見えた上流)だった。
幸い、事態は大きくはならなかった。エラー監視はちゃんと鳴った。一方で、Dead Letter Queue(DLQ)経由の再処理が後続を拾い、結果としてユーザー影響は出なかった。
この記事では、そのとき何が起きていたか、そして「AI にコードを書かせるときに何を明示すべきか」を整理する。
何が起きたか
Zoom OAuth のフローは、ざっくり次のような流れになる。
- ユーザーが Zoom の認可画面へリダイレクトされる
- 認可コードを受け取る
- アクセストークンを取得する
- 以降の API 呼び出しに使う
今回、トークン取得(またはその直前の HTTP 通信)のタイミングで、上記の HTML が返ってきた。502 は「ゲートウェイが上流から正常な応答を得られなかった」という意味で、Cloudflare が前面にいる構成では、一時的なネットワーク不調や上流の瞬断でも普通に起こりうる。
重要なのは次の2点だ。
- 502 が返った時点で、そのリクエストを処理していたプロセス(またはワーカー)は終了した
- エラー監視はエラーとして報告した — これは正しい。502 は「成功」ではない
つまり、単体の HTTP リクエストとしては失敗している。ログにもアラートにも残る。ここまでは想定どおりの挙動だ。
なぜ「事なきを得た」のか — DLQ の存在
502 でプロセスが落ちても、全体として問題にならなかった理由は DLQ と再処理の仕組み にあった。
ざっくりした構成イメージはこうだ。
[OAuth 処理] --失敗--> [DLQ にメッセージ保存]
|
v
[再処理ワーカーが後から実行]
|
v
[成功 or 再リトライ]502 のような 瞬発的・一過性の障害 は、少し時間を置いて再試行すれば通ることが多い。Cloudflare や上流の一時的な不調は、数秒〜数分で収束することがある。
DLQ は「その場で失敗した処理を捨てない」ための仕組みだ。
- 1回目の試行: Cloudflare 502 → 失敗 → DLQ へ
- 再処理: 同じ処理を後から実行 → 成功
エラー監視から見ると「エラーが発生した」という事実は変わらない。アラートが飛ぶのも自然だ。ただし ユーザー体験やデータ整合性の観点では、再処理がカバーしてくれた わけだ。
ここで言いたいのは、「監視が静か = 問題なし」でも、「監視が鳴る = 必ず障害」でもない、ということだ。DLQ 付きの非同期処理では、一時的失敗はログに残りつつ、最終的には成功する というパターンが普通にある。
Cloudflare は「案外」止まる
CDN やリバースプロキシは、可用性が高いインフラだと感じがちだ。Cloudflare も大規模で安定している一方、完全に止まらないわけではない。
502 Bad Gateway が Cloudflare 名義で返る典型例は次のようなものだ。
| 原因のイメージ | 説明 |
|---|---|
| 上流(オリジン)の一時不調 | アプリサーバーが短時間応答不能 |
| Cloudflare ↔︎ 上流間の接続問題 | タイムアウト、接続リセットなど |
| Cloudflare 側の瞬間的な問題 | 稀だが、エッジや経路の一時障害 |
| 相手先(今回なら Zoom)側の瞬間的な問題 | OAuth エンドポイントの一時エラー |
いずれも 「永続的な障害」ではなく「瞬発的な不通」 として現れることが多い。だからこそ、同期1発勝負の設計だとユーザーにそのままエラーが返る。非同期 + リトライ + DLQ があると、運用者が寝ていても回復する余地が生まれる。
「Cloudflare だから大丈夫」は過信だ。前面に Cloudflare がいても、502 は普通に起きうる。
AI にコードを書かせるとき、DLQ とリトライは「暗黙では書いてくれない」
最近、実装を AI に任せる機会が増えた。便利だが、落とし穴もある。
Happy path(正常系)だけを書いて、障害時の設計を書いてくれない ことが多い。
AI がデフォルトで書きがちなもの:
- OAuth フロー本体
- トークン取得 → DB 保存
- 成功時のレスポンス
AI が明示しないと書いてくれないもの:
- 失敗時のリトライ(指数バックオフ、最大試行回数)
- DLQ / 再処理キュー
- 冪等性(同じメッセージを2回処理しても壊れない)
- タイムアウト設定
- 監視・アラートと「許容される一時失敗」の線引き
502 のような外部依存の失敗は、ビジネスロジックの一部 だ。OAuth 連携を本番運用するなら、「Zoom API が一時的に返す 502 をどう扱うか」は設計要件に含めるべきだ。
AI に任せる場合は、例えば次のように 明示的に指示 した方がよい。
- Zoom OAuth トークン取得は外部 HTTP 依存のため、502/503/504 は一時障害として扱う
- 失敗時は SQS(または相当するキュー)の DLQ に落とし、最大 N 回まで指数バックオフで再処理する
- 再処理は冪等に実装する(同じ authorization code / state で2回成功しても問題ない)
- CloudWatch(または相当する監視)ではエラーを記録するが、DLQ 再処理成功後は別メトリクスで回復を確認できるようにする「OAuth 書いて」だけだと、502 でプロセスが終了して終わり、というコードになりがちだ。今回のように DLQ があったから助かった、というのは 意図的にそう設計していたから だ。
運用に耐えるためには、要件として書く
まとめると、次の3層を分けて考えると整理しやすい。
1. 同期処理(その場の HTTP リクエスト)
- 502 が返ったら失敗として扱う
- ユーザーには適切なエラー画面 or 「処理中です」にする
- ここで無理にリトライしすぎない(OAuth の authorization code は使い捨てのことが多い)
2. 非同期処理(キュー + DLQ)
- 失敗したジョブは DLQ へ
- バックオフ付き再試行
- 冪等性の確保
3. 監視
- 502 はエラーとして記録する(隠さない)
- 「最終的に成功したか」も追えるようにする
- アラートの閾値は「DLQ に滞留が続く」「再試行上限超過」など、回復不能 の信号に寄せる
今回のケースは、この3層がうまく噛み合っていた。
- 同期: 502 でプロセス終了 → 監視が検知
- 非同期: DLQ が後から再処理 → 成功
- 結果: ユーザー影響なし、ただしログには痕跡が残る
おわりに
Zoom OAuth の途中で Cloudflare 502 が瞬発した。プロセスは落ち、エラー監視も鳴った。それでも DLQ による再処理が後を拾い、事なきを得た。
教訓はシンプルだ。
- Cloudflare の前に立っていても、502 は起きる — 瞬発的な不通は想定内に入れる
- AI に実装を任せるとき、DLQ・リトライ・冪等性は明示的に書かないと載らない
- 本番運用に耐える設計は、Happy path だけでは足りない — 要件として障害系を書く
次に OAuth 連携や外部 API 連携を AI に書かせるときは、「502 が来たらどうするか」まで一緒に指示しておくとよい。監視が鳴っても、DLQ が静かに仕事をしてくれる — その状態を 最初から設計に含める のが、運用と開発の両方に優しい。