シンジです。企業内の全情報を、企業内の検索エンジンで探すことができるようにする道具は昔から需要があり、エンタープライズサーチとして現在も存在し続けています。企業内の情報には機微情報や権限の壁が多くあり、どう設計するか、どれくらいの精度で結果を返すかなど、エンタープライズサーチの商品群にも様々な工夫が行われており、実際に企業が導入しようとすると、なかなかのいいお値段と運用負荷が付いて回るものです。AI時代と言われる現代において、この市場をかっさらっているのがGleanです。もちろんエンタープライズサーチの選択肢はGleanとNotionだけではありません。Elastic Workplace Search、Microsoft Copilot、Google Cloud Searchなども候補に挙がります。しかし、AIネイティブな検索体験、コネクタの充実度、そして当社のようなSaaS中心の企業環境での実用性を考慮すると、2026年時点で本気で検討に値するのはGleanかNotion AIの2択に絞られます。

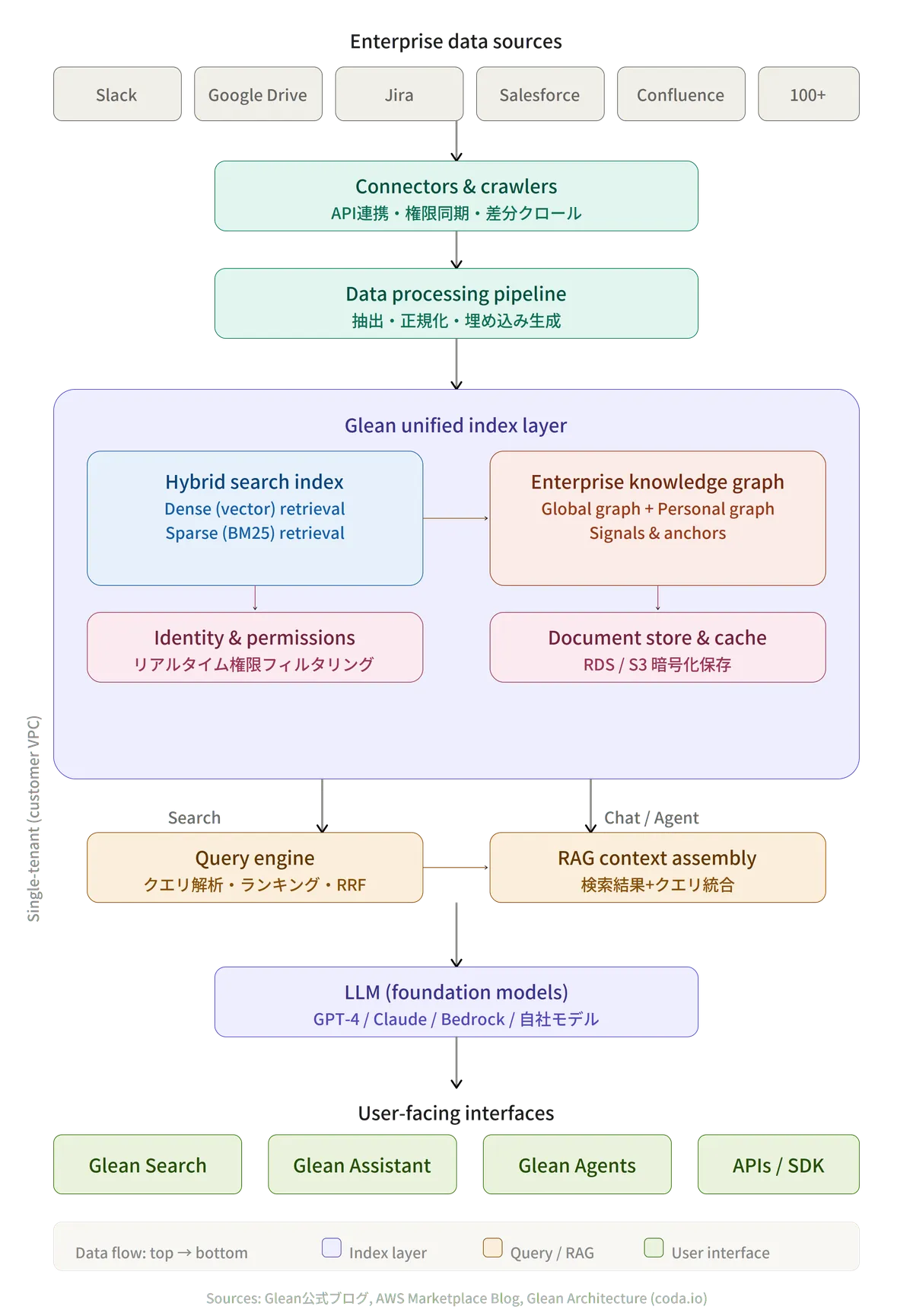
GleanはAIの前段にインデックスが存在する
AIは、同じ質問をしても回答が毎回変わるという特性があります。Gleanは、CEOのArvind Jain氏をはじめ創業メンバーの多くがGoogle出身であり、検索技術に深い知見を持つチームが設立したこともあってか、まずは検索用のインデックスを挟むことによって、AIの回答を安定させる工夫が行われています。
社内普及の為の工夫が随所にある
AIを買いましたといっても、社内に普及させるのは至難の業なのです。そこでGleanには、Google Chromeと連携する機能や、管理者側で利用率などを集計する機能などが豊富に用意されています。
Gleanは自社ホストができる
外部に情報を出さない究極的な方法として、そもそもGleanの環境を丸ごと自社のGCP環境に展開して使うことができます。SaaSやAIに情報が流れていくのを恐れるエンタープライズに取っては、こういったサービスは大変魅力的ではあるものの、GCP環境は自社で運用する必要がある点や、GCPのコスト、GCPの規模感によっては、インデックスされるまでに1週間程度のラグが発生したりするなどのデメリットもあります。
Gleanはオンプレミスのファイルサーバーも検索対象に出来る
自社環境に閉じたJiraやGithubなども検索対象に出来るほか、SharePoint Server 2013/2016/2019へのネイティブコネクタもあれば、Indexing APIでカスタムコネクタを自作することで、どんな対象であっても割と自由度高くインデックスさせることができます。CIFSやSMBのネイティブコネクタはありませんが、実際に当社でも、ネイティブコネクタが存在してないものはカスタムコネクタを使って接続しています。
Gleanええやんけと思って買ったんですが
Notionが似たようなこと出来るんですよ。あのNotionがまさかエンタープライズサーチになるとは思ってもみませんで。Notion AIってSaaSを接続することで、そのSaaSの情報を取得して回答してくれるんです。ただNotionの場合はインデックスはしないし、セルフホストも出来ないし、カスタムコネクタもありません。この記事を書いている時点ではですが。
当社の環境に限ってしまえば、オンプレ資産なんて全くないし、Notionがコネクタとして接続できるSaaSの範囲は十分だし、実はGleanの本領が発揮できないのではと感じたわけです。
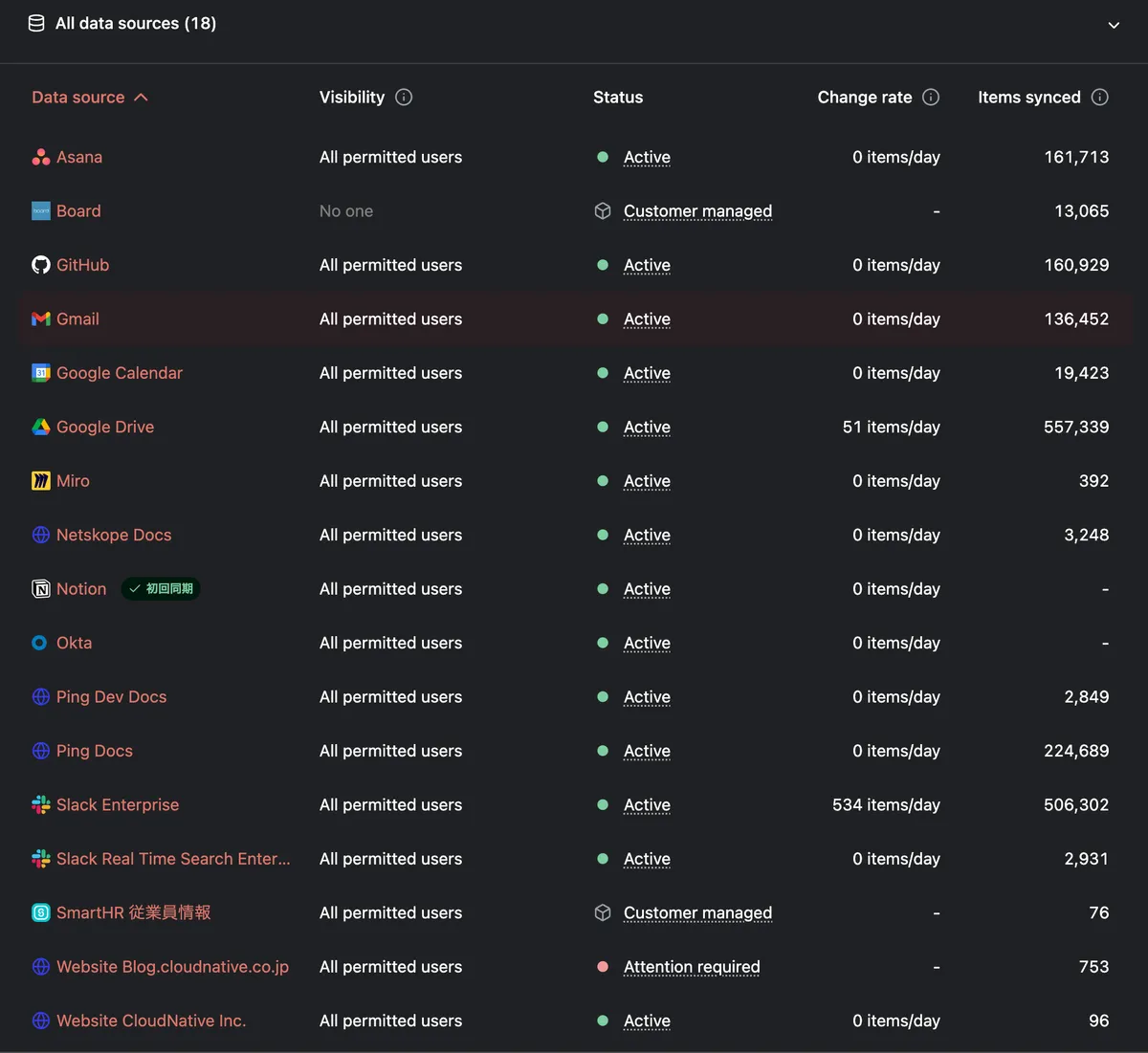
Gleanのデータソース
Notionのデータソース
それにしてもNotionが体感でかなり優秀に感じる
この感覚はシンジだけではなく、社内からも同様の声を聞くようになりました。根本的な気持ちの問題として、エンタープライズサーチを期待して導入してるGleanと、ドキュメント管理をメインにしているNotionでは、期待値が全く違います。その環境下においても、NotionがGleanを上回ってしまうようなことがあれば、じゃあGleanってなんであるんだっけってなりませんか。
当社の環境では「わりとNotionでSaaSの検索がカバー出来ている」という点が大前提にあるものの、ここで感じる優秀さというのは、「GleanとNotionに同じ質問をしても、Notionの方が良い回答出してる気がする」という点なのです。
前述の通り、GleanにはGleanにしか出来ない展開方法や運用方法があるわけなので、全てのシチュエーションにおいてNotionでいいじゃんとはならないわけですが、同じソースをみていて同じ質問をしたときに、エンタープライズサーチの為に導入したサービスが、それを期待していなかったNotionに負けてるなんてことがあるとすれば、社内でGleanの費用対効果を再検討すべきではないか、という議論が出てきます。
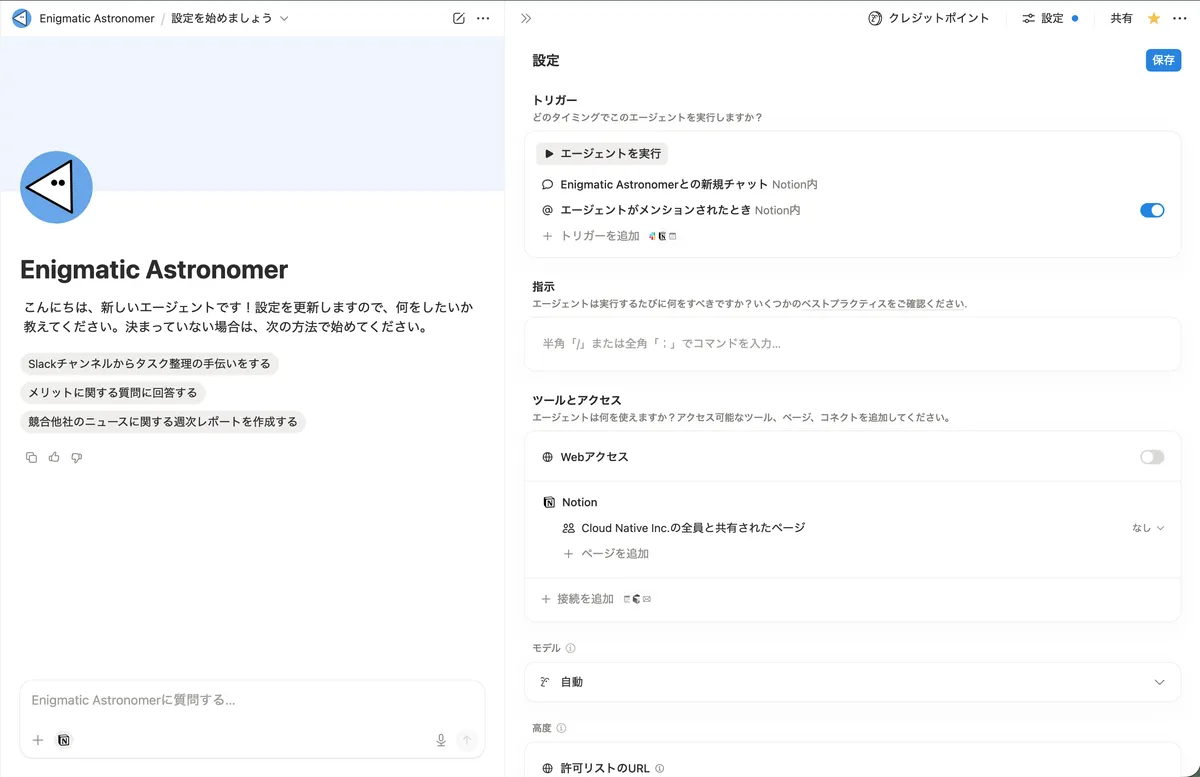
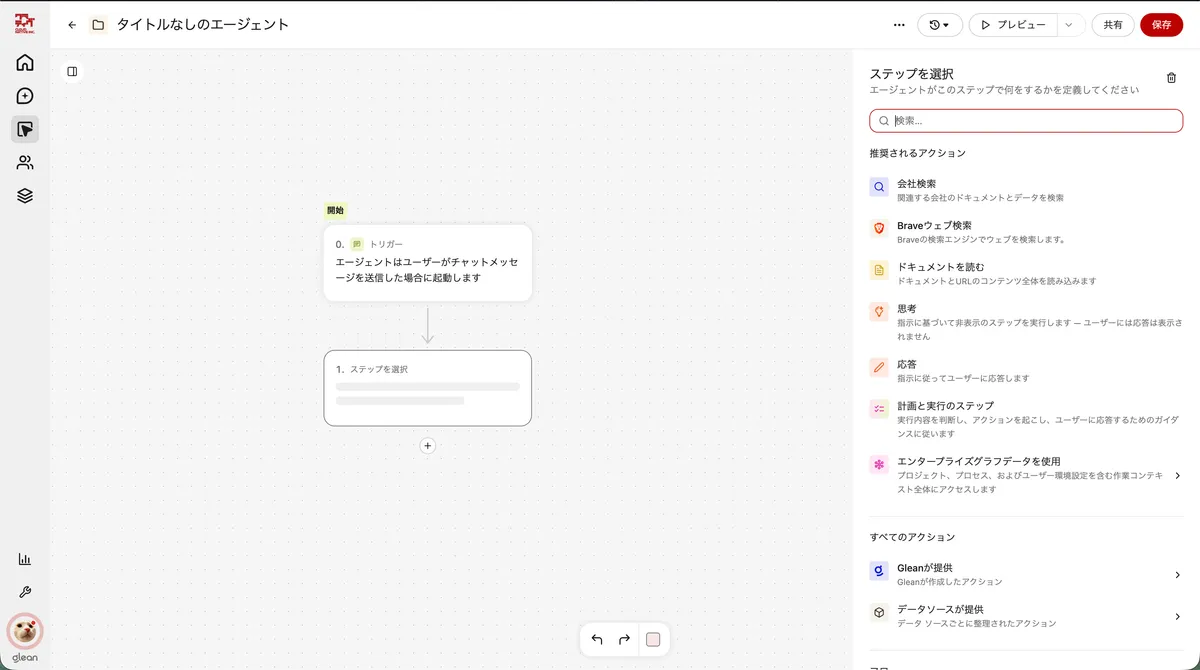
余談:AIエージェント作成画面も違いがある
Notionの画面、基本的に左側のAIにやりたい事を書くと作ってくれる。できることはかなりシンプル。カスタムMCPの接続も可能。
Gleanの画面、まるでiPaaSのように複雑なエージェントを作れる。出来る事が多い分、作り方を学ぶ必要がある。
600の質問を生成して、GleanとNotion AIに同じ質問をした結果を公表します
Claude CodeからMCP(Model Context Protocol:AIモデルが外部ツールやデータソースに接続するための標準プロトコル)を使って、どちらもOpus 4.6を指定して同じ質問をした結果、どっちが優れた回答をしたのか調べました。以下がそのレポートです。両社にとっても改善のヒントになれば幸いです。
以下は長いレポートなのでここで結論を書きますが
当社みたいな環境なら、Notionいいぞってことです。UIも綺麗だし。Notion全く使ってなくても、エンタープライズサーチ目的でNotionを導入するのもありだと思う。ただし、接続先が十分に用意されている環境が整っていればという前提で。これ、Notionも売り方変えた方がいいのではと思ってしまったのと、エンタープライズサーチの分野に殴り込みしてきた方がいいのではと思いました。
以下、Notionが圧勝しているレポートをご覧下さい。
1. はじめに
社内に蓄積された情報を「検索して正しく答える」能力は、エンタープライズ AI の中核機能です。本レポートは、株式会社クラウドネイティブの現行環境において、Glean と Notion AI の社内検索・回答品質を 600 件の質問で比較した観測結果を報告します。本結果は 1社のケーススタディであり、製品一般の普遍的優劣を示すものではありません。
本評価は、製品単体の API 比較ではなく、MCP 経由の E2E パイプライン比較です。したがって、コネクタ設定、MCP 実装、フォールバック、レートリミット耐性を含む実運用上の条件が結果に反映されています。
対象企業: 株式会社クラウドネイティブ(ゼロトラスト・SaaS セキュリティ専門、従業員約 40 名)
実行日: 2026-03-26(v1)→ 2026-03-27(v2: Glean 全コネクタ有効化)→ 2026-03-29(v3: Notion 回答全600件再取得)
主結果(モード別)
| モード | Glean | Notion | Tie | 説明 |
|---|---|---|---|---|
| real_world (n=300) | 15.3% | 78.3% | 6.3% | 各製品の実接続ソース全体を対象 |
| shared_retrieval (n=300) | 11.7% | 82.7% | 5.7% | Notion 内情報で回答可能な質問集合による準制御比較 |
| 全体 (n=600) | 13.5% | 80.5% | 6.0% | 上記2モードの合算(性格の異なるモードを半々で含む) |
本レポートの主な制約
結果の解釈にあたっては、以下の制約を先に理解してください。
- 1社のケーススタディであり、製品一般の優劣を示すものではありません
- 当社は Notion 中心の情報構造です。Notion の利用度が低い企業では異なる結果になる可能性が高いです
- v3 では両システムとも最新回答です。v2 までは Notion 回答が v1 固定ベースラインでしたが、v3 で全600件を再取得しました
- 評価者は単一 LLM(Claude Sonnet 4.6)です。人手再判定は未実施です。信頼度は Moderate です
当社では Glean と Notion AI を併用しており、それぞれが異なるデータソースに接続しています。この環境を活かし、実運用条件(real_world)と、Notion 内情報を主要対象とした準制御条件(shared_retrieval)の両面から評価を行いました。
2. 方法論
2.1 質問設計
5 カテゴリ x 120 件 = 600 件の質問セットを作成しました。
| カテゴリ | 件数 | 概要 |
|---|---|---|
single_hop_fact | 120 | 単一事実の検索 |
entity_relationship | 120 | エンティティ間の関係性 |
temporal_status | 120 | 時系列・ステータスの把握 |
decision_history | 120 | 意思決定の経緯 |
cross_source_synthesis | 120 | 複数ソース横断の統合 |
難易度分布:
| 難易度 | 件数 |
|---|---|
| easy | 200 |
| medium | 200 |
| hard | 200 |
評価モード分布:
| モード | 件数 | 説明 |
|---|---|---|
real_world | 300 | 各製品の実接続ソース全体を対象(接続範囲の広さも性能の一部として評価) |
shared_retrieval | 300 | Notion 内情報で回答可能な質問集合を用いた準制御比較(詳細は 2.5節参照) |
回答可能性分布:
| 区分 | 件数 |
|---|---|
| answerable | 544 |
| insufficient_evidence | 36 |
| unanswerable | 20 |
unanswerable / insufficient_evidence を合計 56 件(全体の 9.3%)含めることで、「わからない」と適切に留保できるか(abstention_quality)を測定しました。
機微度分布:
| 区分 | 件数 |
|---|---|
| public_internal | 346 |
| confidential | 228 |
| restricted | 26 |
2.2 質問レビュー
質問生成は 722 件を候補として作成し、品質レビューにより 122 件を除外して、600 件を確定しました。
除外理由の内訳:
| 除外理由 | 件数 |
|---|---|
| answerability_unclear(回答可能性が不明確) | 64 |
| over_sensitive(機微度が高すぎる) | 25 |
| mode_scope_mismatch(評価モードとスコープの不整合) | 15 |
| no_evidence_basis(実在する証跡が見込めない) | 9 |
| too_ambiguous(質問が曖昧すぎる) | 6 |
| semantic_duplicate(同義重複) | 2 |
| product_bias(特定製品に有利) | 1 |
| 合計 | 122 |
最大の除外理由は answerability_unclear(64 件、全除外の 52.5%)であり、「そもそも正しい答えが存在するか判断できない質問」を排除することで、評価の信頼性を確保しました。
2.3 Ground Truth 作成
600 件全てに対して Ground Truth(期待回答セット)を作成しました。Ground Truth は模範解答ではなく、must_include(含むべき事実)と must_not_claim(主張してはならない事実)を定義した監査可能な基準です。
Ground Truth の確信度分布:
| 確信度 | 件数 | 割合 |
|---|---|---|
| high | 171 | 28.5% |
| medium | 94 | 15.7% |
| low | 335 | 55.8% |
low が過半数を占めるのは、社内情報の多くが複数解釈可能であり、単一の正解を断定しにくいことを反映しています。
2.4 ブラインド評価設計
評価の公平性を担保するため、評価器に Glean / Notion の識別名を一切渡さない ブラインド評価を採用しました。
- シャッフル方式: SHA-256 (
run_id+question_id+fixed_salt) のハッシュ値で決定論的に A/B を割り当てました - v2: A = Glean となった質問: 301 件 / A = Notion となった質問: 299 件
- 再現性: 同一の
run_idとsaltを使えば、誰が実行しても同じ A/B 割り当てが再現されます
2.5 shared_retrieval の制約方法
shared_retrieval モード(300件)では、Notion ワークスペース内の情報のみを対象とする公平比較を意図しています。ただし、以下の制約があります。
制約の実装方法:
- 質問設計時の制約:
shared_retrievalの質問は「Notion ワークスペース内の情報のみで回答可能」と判断されるもののみを採用しました。Ground Truth も Notion ワークスペース内の情報のみを根拠として作成しました - Glean 側のソース制限: Glean に対して API レベルでのソース allowlist は設定していません。Glean は全接続ソースを検索可能な状態で実行しました
- 評価時の制約: 評価は Ground Truth(Notion 内情報のみで構成)に対する一致度で判定するため、Glean が外部ソースから取得した情報も、Ground Truth と一致すれば正当に評価されます
監査上の限界:
- Glean を Notion ソースのみに技術的に制限する手段(ソースフィルタリング API 等)は、Glean MCP の現行仕様では提供されていません
- 同一ユーザー権限で実行しましたが、同一時点のデータスナップショットは保証していません。v1 と v2 の実行は約1日の差があります
- このため、
shared_retrievalの結果は「同一情報範囲に制約した厳密な公平比較」ではなく、「Notion 内情報を主要対象とした比較」として解釈すべきです
2.6 勝敗判定ルール
ブラインド評価における勝敗判定のルールを以下に明示します。
Winner の判定基準:
- 評価者(Claude Sonnet 4.6)が、各質問に対して Answer A と Answer B を 6軸で採点した上で、「A」「B」「tie」を判定します
- Tie の閾値は明示的な数値ではなく、評価者の判断に委ねています。プロンプトでは「両者とも不十分で優劣が小さい場合は tie」と指示しています
- overall スコアは重み付き平均(accuracy 0.315 + completeness 0.265 + citation_quality 0.16 + context_awareness 0.16 + abstention_quality 0.10 = 1.0)で算出。各質問単位で丸め前のスコアから overall を算出し、整数に丸めた後、全質問の平均を取っています。responsiveness は overall 算出対象外の参考指標として別掲しています。7章の軸別平均は「全質問の各軸スコアの平均」であり、overall の算出元とは異なります。このため、7章の軸別平均に重みを掛けた値と overall 平均は一致しません(各質問での整数丸めの影響)
No-answer / API error の扱い:
- Glean が API エラーで回答を返せなかった場合も、そのまま評価対象としました。エラー回答は「回答できなかった」として低評価されます
- エラー回答を除外して再集計する方式は採用していません。これは API の安定性も製品品質の一部と判断したためです
- v2 での Glean エラー回答は 42件(7.0%)、Notion は 0件です
勝率と平均スコアの乖離について:
勝率差と overall 差は必ずしも比例しません。Tie の比率や、「僅差で勝つ質問が多いか」「大差で負ける質問が集中しているか」によって、勝率差と平均スコア差の見え方は変わります。本レポートでは、監査可能性の観点から overall(連続値) を主に参照します。
3. 実行アーキテクチャ
本ベンチマークは Claude Code セッション内で直接実行しました。外部 API キーは使用していません。
3.1 データソース接続状況
各システムのデータソース接続構成は以下の通りです。
共通コネクタ(7種): Asana, Box, GitHub, Gmail, Google Calendar, Google Drive, Slack
Glean のみ(14種): Board, Miro, Netskope Docs, Okta, Ping Dev Docs, Ping Docs, SmartHR 従業員情報, Website Blog.cloudnative.co.jp, Website CloudNative Inc., Zoom, AWS Docs, Microsoft Docs, Notion, Slack Real Time Search
Notion AI 固有: Notion ワークスペース自体(ネイティブアクセス)
3.2 回答取得
| システム | 使用ツール | 方式 |
|---|---|---|
| Glean | search / chat / read_document / employee_search / gmail_search / meeting_lookup | MCP 経由で直接呼び出し |
| Notion | notion-search(ai_search + workspace_search)+ notion-fetch | MCP 経由で直接呼び出し。2 つの検索モードを併用 |
3.3 評価実行
- 評価モデル: Claude Sonnet 4.6(claude-sonnet-4-6)サブエージェントによるブラインド評価
- 並列処理: 20 バッチ x 30 件 = 600 件を並列サブエージェントで処理しました
3.4 有効回答数
| システム | 有効回答数 | 有効率 |
|---|---|---|
| Glean(v1) | 513 | 85.5% |
| Glean(v2 全コネクタ有効化) | 558 | 93.0% |
| Notion | 600 | 100% |
注記: 本表は回答取得時点の実績を示しています。v3 主結果における有効回答率は、6章の主結果(Glean 93.0%、Notion 95.7%)を参照してください。
4. Notion 検索戦略の発見
本ベンチマークの設計過程で、Notion の検索品質を大きく左右する発見がありました。
4.1 事前テストの結果
本番実行に先立ち 5 件の質問で事前テストを実施したところ、ai_search のみを使用した場合と、workspace_search を併用した場合で劇的な差が出ました。
| 検索戦略 | overall スコア(5件平均) |
|---|---|
| ai_search のみ | 2.6 / 5.0 |
| ai_search + workspace_search 併用 | 4.0 / 5.0 |
4.2 各モードの特性
| 検索モード | 強み | 弱み |
|---|---|---|
workspace_search | 組織図、チーム情報、ISMS 文書、手順書、設定ドキュメント | セマンティック理解が弱い |
ai_search | 外部接続ソース(Box, Slack 等)、文脈理解、セマンティック検索 | 最近のブログ記事に偏る傾向 |
4.3 ベンチマーク設計への反映
この発見を受け、本番ベンチマークでは Notion の全質問に対して ai_search と workspace_search の両方を実行する設計としました。検索戦略の選択がベンチマーク結果を根本的に変えるため、各システムの最適な使い方で比較することが公平性の前提です。
4.4 Glean 側の最適化プロセス
Notion に対して 5件の事前テストを実施したのと同様に、Glean 側にも以下の最適化を行いました。
v1 時点の最適化:
search+chatの併用戦略を採用。まずsearchで広く検索し、必要に応じてchatで合成回答を生成read_documentによる文書詳細の取得- レートリミット対応のため 40並列 → 5並列に削減しリトライ実施
v2 再テストでの追加最適化:
- 全データソースコネクタを有効化(Slack, Gmail, Google Calendar, Box, Google Drive, GitHub, Notion, Okta, SmartHR 等)
employee_search(Okta/SmartHR 連携による組織図・人事情報)、gmail_search、meeting_lookup等の専用ツールも活用可能に- 回答取得プロンプトに「単一ソースで見つからない場合は必ず他のソースも検索すること」を明示
最適化の非対称性について:
Notion の事前テストは workspace_search の発見につながりましたが、Glean 側には同等の「未知の検索モード発見」はありませんでした。これは Glean MCP のツールが search / chat / read_document / employee_search / gmail_search / meeting_lookup と明確であり、「隠れた検索モード」が存在しないためです。一方、Notion MCP の notion-search は ai_search / workspace_search の 2モードが存在し、デフォルトが ai_search のため、明示的な探索なしには workspace_search を併用できませんでした。この非対称性は本ベンチマークの限界の一つです。
5. 実行時の運用課題
600 件規模のベンチマークを MCP 経由で実行する過程で、複数の運用課題が発生しました。以下に全て記録します。
5.1 Glean API レートリミット
問題: 初回実行時、40 エージェント並列で Glean API を呼び出したところ、HTTP 429(Elastic rate limit exceeded)が頻発しました。
エラー率のバッチ間ばらつき:
- batch_00 / batch_04: エラー率 0%
- batch_01 / batch_08: エラー率 70% 超
- バッチにより 0〜77% の範囲でばらつきが発生しました
対応: 並列数を 5 エージェントに削減してリトライを実施しました。
適正並列数の教訓: Glean / Notion ともに 5〜10 エージェント並列が適正です。40 並列は API レートリミットを誘発するため過剰でした。
5.2 Glean chat API の不安定性
問題: mcp__claude_ai_Glean__chat が "response contains message of type ERROR" を高頻度で返しました。
影響:
- chat API に依存した回答取得が不安定になりました
- search API へのフォールバックで対応したケースが多数発生しました
- search API は 50〜150KB の大量 JSON を返すため、LLM のコンテキストウィンドウを圧迫する副作用がありました
5.3 Notion MCP の処理時間
問題: Notion エージェントは Glean エージェントの約 2〜3 倍の処理時間を要しました。
| 項目 | Glean | Notion |
|---|---|---|
| 30 件バッチあたりの処理時間 | 約 6〜12 分 | 約 12〜18 分 |
| 1 質問あたりの MCP コール数 | 1〜2 回 | 最低 3 回(ai_search + workspace_search + fetch) |
Notion の処理時間増加は検索品質向上とのトレードオフです。ai_search のみに削減すれば高速化しますが、セクション 4 で示した通り検索品質が大幅に低下します。
5.4 サブエージェントのスキーマ不統一
問題: 20 バッチの評価サブエージェントが、それぞれ異なるスキーマで評価結果を出力しました。
発生した出力形式の例:
answer_a/answer_b形式scores_a/scores_b形式score_a/score_b形式- フラット形式(ネストなし)
対応: 正規化スクリプトを作成し、全バッチの出力を統一スキーマに変換しました。サブエージェントに構造化出力を強制する場合、スキーマ定義をプロンプトに明示的に含め、出力例を併記する必要があります。
6. モード別主結果(v3)
600件のブラインド評価の結果、当社環境では Notion AI が全体で優勢となりました。v2 再テスト(Glean 全データソースコネクタ有効化)で Glean は +3.4pp 改善しましたが、全カテゴリで Notion 優位が観察されました。
注: 全体勝率(13.5% vs 80.5%)は、性格の異なる real_world(300件)と shared_retrieval(300件)の合算です。モード別の結果(1章の主結果表)を先に参照してください。
v3 では両システムとも最新回答で比較しています。 v2 までは Notion 回答が v1 固定ベースラインでしたが、v3 では Notion 回答を全600件再取得し、v2 までより対称性の高い条件で比較しています。
v1 → v2 → v3 の変更範囲:
- v2: Glean 回答を全600件再取得(全コネクタ有効化)。Notion 回答は v1 固定
- v3: Notion 回答を全600件再取得(workspace_search + ai_search 併用)。Glean 回答は v2 を維持
- ブラインド評価: v3 で全600件を新 run_id + salt で再評価
v3 の結果が本レポートの主結果です。v2 までの Notion 固定ベースライン問題は v3 で見直され、より対称性の高い条件で比較しています
| 指標 | v1 Glean | v2 Glean | v3 Glean | v1 Notion | v2 Notion | v3 Notion | v3 Tie |
|---|---|---|---|---|---|---|---|
| 勝利数 | 113 | 133 | 81 | 413 | 376 | 483 | 36 |
| 勝率 | 18.8% | 22.2% | 13.5% | 68.8% | 62.7% | 80.5% | 6.0% |
6.1 モード別主結果(v3)
| モード | Glean | Notion | Tie | 性格 |
|---|---|---|---|---|
| real_world (n=300) | 15.3% | 78.3% | 6.3% | 各製品の実接続ソース全体を対象 |
| shared_retrieval (n=300) | 11.7% | 82.7% | 5.7% | Notion 内情報で回答可能な質問集合による準制御比較 |
v3 では両システムとも最新回答で比較しています。 Glean は v2 回答(全コネクタ有効化済み)、Notion は v3 で全600件再取得しました。
- 信頼度: Moderate(GT の low 確信度 55.8%、単一LLM評価者、人手再判定未実施)
- 有効回答率: Glean 93.0%(v2 据置)、Notion 95.7%(v3 再取得)
- 評価は Claude Sonnet 4.6(claude-sonnet-4-6)によるブラインド方式(A/B シャッフル、ベンダー名を伏せて実施)
- 本ベンチマークは製品単体の API 比較ではなく、MCP 経由の E2E パイプライン比較です。コネクタ設定、MCP 実装、フォールバック、レートリミット耐性を含む実運用上の条件が結果に反映されています
7. 評価軸別スコア(v3 主結果)
5段階評価(1.0〜5.0)の各軸における平均スコアを以下に示します。
| 評価軸 | v3 Glean | v3 Notion | 差分 | v2差分 |
|---|---|---|---|---|
| accuracy | 3.01 | 3.77 | +0.75 | v2: +0.29 |
| completeness | 2.56 | 3.65 | +1.09 | v2: +0.33 |
| citation_quality | 2.12 | 3.70 | +1.58 | v2: +0.58 |
| context_awareness | 2.79 | 3.92 | +1.13 | v2: +0.36 |
| abstention_quality | 3.54 | 4.11 | +0.57 | v2: +0.19 |
| overall(連続値, 5軸加重平均) | 2.77 | 3.78 | +1.01 | v2: +0.35 |
v2 → v3 の変化:
v3 で Notion 回答を再取得した結果、全評価軸で差が拡大しました。これは v2 までの Notion 固定ベースラインが Notion の実力を過小評価していたことを示しています。
- citation_quality の差が最大(+1.58)。Notion の workspace_search による構造化ページへの正確な引用が大きな差を生んでいます
- completeness の差が次点(+1.09)。Notion の回答はより網羅的に must_include 項目をカバーしています
- abstention_quality の差が最小(+0.57)。「わからない」と適切に留保する能力では差が比較的小さいです
- 全評価軸で Notion が優位です。特に citation_quality、completeness、context_awareness で大きな差が観測されました
overall の補足:
本レポートでは、5軸(accuracy / completeness / citation_quality / context_awareness / abstention_quality)の加重平均から overall を算出しています。overall(連続値) は各軸平均に重みを掛けた連続値であり、overall_rounded は各質問単位のスコアを整数化したうえで平均した参考値です。外部向けの比較では、監査可能性の観点から overall(連続値) を主指標として扱います。
参考指標(overall 算出対象外):
| 指標 | Glean | Notion | 備考 |
|---|---|---|---|
| responsiveness | 3.06 | 3.97 | 回答の有無・エラー状態を含む補助的な主観指標。実測レイテンシではない |
| MCP 処理時間(実測) | 約6〜12分/30件 | 約12〜18分/30件 | 5.3節参照。Notion は3回以上の MCP コール必要 |
responsiveness の補足:
responsiveness は実測レイテンシではなく、回答の有無、エラー状態、応答の安定性を含む補助的な主観指標です。v3 では Glean 3.06、Notion 3.97 で、Notion の方が高い値でした。一方、5.3節の処理時間は MCP 経由の実測値であり、Notion は 30件バッチあたり約 12〜18 分、Glean は約 6〜12 分でした。したがって、responsiveness と実測処理時間は異なる指標であり、前者は「体感的な応答安定性」、後者は「実際の所要時間」を示します
8. カテゴリ別分析
8.1 single_hop_fact(単一事実検索)
| v3 Glean | v3 Notion | v3 Tie | |
|---|---|---|---|
| 勝率 | 19.2% | 74.2% | 6.7% |
単一事実検索では Notion が優勢でした。Glean も一定の回答力を示しましたが、Notion はチームページ、組織図、方針文書などの構造化情報を直接根拠として参照できるため、正答率と引用の一貫性で差が出ました。Glean は Okta / SmartHR / Google Workspace / Slack プロフィールなど複数ソースから人物・組織情報を取得できますが、本評価では回答本文と根拠の対応の分かりやすさで Notion が上回りました。
8.2 entity_relationship(エンティティ間関係)
| v3 Glean | v3 Notion | v3 Tie | |
|---|---|---|---|
| 勝率 | 14.2% | 78.3% | 7.5% |
エンティティ間の関係性でも Notion が優勢でした。「AプロジェクトとBチームの関係は何か」「Cツールはどの業務フローに組み込まれているか」のような質問では、Notion 内のチームページ、運用手順、設計資料、管理台帳を横断しながら、関係性を比較的安定して再構成できていました。Glean は複数ソースから断片的な関係情報を拾える一方、それらを一つの説明としてまとめる段階で取りこぼしや不整合が残るケースがありました。
8.3 temporal_status(時系列・状態把握)
| v3 Glean | v3 Notion | v3 Tie | |
|---|---|---|---|
| 勝率 | 17.5% | 71.7% | 10.8% |
時系列・状態把握でも Notion が優勢でした。「現在の担当は誰か」「現行ステータスは何か」「いつ完了したか」といった質問では、Notion のプロジェクト DB や運用ページが直接的な情報源になりやすく、最新状態の把握に強みが見られました。Glean は Slack や Google ドキュメントなどから関連情報を収集できますが、時点依存の質問では、最新情報を優先する挙動に改善余地が残りました。
8.4 decision_history(意思決定履歴)
| v3 Glean | v3 Notion | v3 Tie | |
|---|---|---|---|
| 勝率 | 14.2% | 84.2% | 1.7% |
意思決定履歴は、本評価で Notion の優位が最も分かりやすく出た領域の一つでした。議事録、決定記録、ISMS 文書、方針ページなど、意思決定の前提・経緯・結論が Notion 側でまとまっていることが多く、Notion はそれらを比較的整合的に引用しながら説明できていました。Glean は関連するメール、Slack、各種文書断片を拾えるものの、「なぜその判断に至ったか」という経緯の説明で推測が混ざるケースがありました。
8.5 cross_source_synthesis(複数ソース統合)
| v3 Glean | v3 Notion | v3 Tie | |
|---|---|---|---|
| 勝率 | 2.5% | 94.2% | 3.3% |
複数ソース統合は、本評価で最も大きな差が出たカテゴリでした。「Aチームが利用している全ツールと管理者は誰か」「複数ドキュメントに分散した担当・現状・決定事項を統合して説明してほしい」といった質問に対し、Notion は workspace_search と ai_search の併用により、複数ページ・DB・関連文書をまたいだ統合回答を構成できていました。Glean も複数ソースから情報を取得できますが、本評価では断片の列挙にとどまるケースが多く、一貫した統合回答の品質で大きな差が残りました。
9. モード別・難易度別分析
9.1 ベンチマークモード別(v3)
| モード | Glean | Notion AI | Tie |
|---|---|---|---|
| real_world | 15.3% | 78.3% | 6.3% |
| shared_retrieval | 11.7% | 82.7% | 5.7% |
real_world と shared_retrieval のいずれでも Notion が優勢でした。real_world は各製品の実接続ソース全体を対象にした条件、shared_retrieval は Notion 内情報で回答可能な質問集合を対象とした準制御比較です。Glean は real_world の方が 3.6pp 高く、接続ソースの広さが一定の価値を持つことは観測されましたが、本評価ではその利点をもっても Notion を上回るには至りませんでした。
shared_retrieval でも Notion が 82.7% と高い勝率を示しており、Notion 内情報が主要根拠となる条件では差がさらに拡大しました。ただし、2.5節で述べた通り、shared_retrieval は Glean を技術的に同一ソースへ制限した厳密な same-source 比較ではなく、「Notion 内情報を主要対象とした比較」として解釈すべきです。
9.2 難易度別(v3)
| 難易度 | Glean | Notion AI | Tie |
|---|---|---|---|
| easy | 16.5% | 80.0% | 3.5% |
| medium | 11.0% | 83.0% | 6.0% |
| hard | 13.0% | 78.5% | 8.5% |
難易度別では、easy / medium / hard のすべてで Notion が優勢でした。最も Notion の勝率が高かったのは medium(83.0%)で、hard でも 78.5% を維持しています。Glean は easy で 16.5%、medium で 11.0%、hard で 13.0% と、全難易度帯で大きな差が残りました。
Tie は easy 3.5%、medium 6.0%、hard 8.5% と全体に低く、v3 では「両者がほぼ同等」と判定されるケースよりも、Notion が明確に上回るケースが多く観測されました。これは Notion 回答を v3 で再取得したことにより、v2 までよりも差が鮮明になったことを示しています。
9.3 回答可能性別(v3)
| 回答可能性 | Glean | Notion AI | Tie |
|---|---|---|---|
| answerable (n=544) | 14.2% | 80.9% | 5.0% |
| insufficient_evidence (n=36) | 0.0% | 88.9% | 11.1% |
| unanswerable (n=20) | 20.0% | 55.0% | 25.0% |
answerable では Notion が 80.9% と高い勝率を示し、通常の業務質問に対する回答品質で大きな差が観測されました。insufficient_evidence では Notion が 32/36件(88.9%)を占め、情報が不足する場面で「何が分かり、何が分からないか」を適切に留保する能力でも優位でした。
unanswerable では Notion 55.0%、Glean 20.0%、Tie 25.0% でした。母数は20件と小さいため解釈には注意が必要ですが、少なくとも v3 では「回答すべきでない質問に対して断定しない」傾向でも Notion が相対的に優勢でした。Glean は unanswerable で一定の改善余地を残しています。
10. 重大エラー分析(v3)
| エラー種別 | v3 Glean | v3 Notion | 説明 |
|---|---|---|---|
| unsupported_claim | 40 (6.7%) | 14 (2.3%) | 根拠のない主張 |
| fabricated_entity | 3 (0.5%) | 0 | 架空の固有名詞の生成 |
| incorrect_citation | 4 (0.7%) | 3 (0.5%) | 誤った引用・出典 |
| overconfident_statement | 65 (10.8%) | 20 (3.3%) | 過度に断定的な記述 |
| 合計 | 112 (18.7%) | 37 (6.2%) |
v3 での重大エラーは Glean 112ラベル、Notion 37ラベルです。Glean のエラー率は Notion の約 3 倍(18.7% vs 6.2%)です。
重要な注釈 — 重大エラー数の解釈について:
v3 の重大エラー数は v2(Glean 15、Notion 4)より大幅に増加しています。この増加には以下の構造的要因があります。
- Ground Truth の 55.8% が confidence=low であり、「断定するな」という制約が付いています。このため、具体的な情報を返すほど overconfident_statement に引っかかりやすい構造です。実際に Glean の overconfident_statement 65件のうち 69% は GT confidence=low の質問で発生しています
- v3 で Notion 回答が強化されたことで、相対的に Glean の弱点が目立ち、評価者がエラーフラグを立てやすくなった可能性があります
- v2 と v3 は異なる評価セッション(それぞれ別の Sonnet 4.6 サブエージェント)が実行しており、判定基準の揺れが含まれます。v2 と v3 の重大エラー数の直接比較は避けるべきです
したがって、重大エラー数の絶対値よりも、v3 内での両システム間の比率(Glean が Notion の約3倍)と、エラーの内容パターンに注目してください。
分類ルール:
- 分類単位: 回答単位(1回答に対し複数ラベルの付与あり)。合計はラベル件数(「少なくとも1つの重大エラーを持つ回答数」ではない)
- 母数: 全600件(API エラーによる無効回答を含む)
- 判定者: ブラインド評価者(Claude Sonnet 4.6)が、Ground Truth の must_not_claim との照合および回答テキストの断定度から分類
- v2 では Notion 回答は v1 と同一であるため、Notion 側のエラー数変化(19件→4件)は再評価による判定差です
主な所見(v3):
- overconfident_statement が最多です(Glean 65件、Notion 20件)。特に decision_history(28件)と temporal_status(11件)で Glean が証拠の薄い情報を断定する傾向が観察されました
- unsupported_claim は Glean 40件、Notion 14件です。Glean の decision_history カテゴリに集中(18件)しており、意思決定の経緯を根拠なく推測するケースが見られました
- fabricated_entity: Glean 3件(0.5%)、Notion 0件。少数ながら、実在確認ができない固有名詞を含む回答が Glean 側で観測されました
- incorrect_citation は両者とも少数(Glean 4件、Notion 3件)です
- 匿名化した代表例: q004 で Glean が自社利用 EDR を CrowdStrike と断定(正解は MDE。CrowdStrike は取扱製品)、q429 で書籍の出版社名と発売日を断定(GT は confidence=low で断定禁止)
11. 各システムの強みと弱み
11.1 Glean の強み
- 広い接続範囲: Glean は共通7コネクタに加え、Okta、SmartHR、Miro、公開 Web、Slack Real Time Search、Zoom など追加ソースを持ちます。real_world モードでの Glean 勝率が 15.3% と、shared_retrieval の 11.7% を 3.6pp 上回ったことは、この接続範囲の広さが一定の価値を持つことを示しています
- 人物・組織情報の横断取得: Okta / SmartHR / Google Workspace / Slack プロフィールを横断した人物特定や所属把握には独自の強みがあります。単一のソースに閉じない人物関連情報の探索は、Glean の価値が出やすい領域です
- 外向き活動・公開情報の把握: 公開事例、イベント登壇、ブログ記事など、Notion ワークスペース外に存在する情報の検索では相対的な強みが見られました
- single_hop_fact では一定の競争力: single_hop_fact での Glean 勝率は 19.2% で、他カテゴリと比べると相対的に高い水準でした。単純な事実検索では一定の競争力を示しています
11.2 Glean の弱み
- cross_source_synthesis が最大の弱点: 勝率は 2.5% で、Notion の 94.2% と大きな差がありました。複数情報の統合を要する質問で、断片の取得後に整合的な回答へまとめる力に改善余地があります
- citation_quality が低い: Glean 2.12、Notion 3.70 で差は +1.58 でした。根拠の提示、主張と出典の対応関係、引用の正確さの面で差が大きく出ています
- 断定の強さに課題が残る: v3 の重大エラーでは overconfident_statement が 65 件、unsupported_claim が 40 件で、Notion より多く観測されました。特に意思決定履歴や時系列状態の質問で、証拠が薄い情報を断定する傾向が見られました
- 本評価環境では Notion 内の構造化情報活用が限定的: shared_retrieval で 11.7% にとどまったことから、Notion 内ページ、DB、関連文書を主要根拠とする質問で相対的に弱さがありました
- 運用面の不安定さ: 本評価環境では、chat API 呼び出しの安定性や、並列実行時のレートリミット(HTTP 429)が課題として観測されました。有効回答率は 93.0% まで改善したものの、依然として Notion(95.7%)を下回っています
11.3 Notion AI の強み
- 構造化された社内情報の活用: ISMS 文書、チームページ、手順書、プロジェクト DB など、Notion 内の構造化情報を直接根拠として利用できる点が大きな強みです
- citation_quality で最大差: Notion 3.70、Glean 2.12 で差は +1.58 でした。引用元の明確さ、根拠の一貫性、回答本文との対応で優位が見られました
- cross_source_synthesis が突出: 勝率は 94.2% で、複数ページ・DB・関連文書を横断して一つの回答にまとめる能力が本評価で最も強く出た領域です
- workspace_search + ai_search 併用の有効性: 事前テストでは ai_search 単体 2.6/5.0 に対し、workspace_search 併用で 4.0/5.0 でした。本番でもこの併用戦略が回答品質を大きく底上げしています
- 有効回答率の高さ: v3 では 95.7% と高い水準を維持し、大量実行時の安定性でも相対優位がありました
11.4 Notion AI の弱み
- 処理時間が長い: 30件バッチあたり約 12〜18 分で、Glean の約 6〜12 分より長くなりました。ai_search + workspace_search + fetch の複数コールが必要なため、バッチ利用では時間コストが高くなります
- 外部情報の広がりでは限界がある: real_world では 78.3%、shared_retrieval では 82.7% であり、Notion 外の文脈が有利になる質問では相対差がやや縮小しました。より広い外部接続を持つ製品に対して改善余地があります
- single_hop_fact / temporal_status では他カテゴリより相対的に低い: それでも高勝率ではあるものの、single_hop_fact 74.2%、temporal_status 71.7% と、cross_source_synthesis や decision_history ほどの圧倒差ではありません
- 検索戦略に依存する: ai_search 単体では実力を十分に発揮できず、workspace_search との併用が事実上必須です。API 利用者やエージェント実装者が最適戦略を知らない場合、性能を過小評価するリスクがあります
12. バージョン間比較
本ベンチマークでは、主に次の3段階で条件が変化しました。
- v1(リトライ後): Glean の初回並列取得で rate limit が多発したため、5並列リトライ後の結果を採用
- v2: Glean の全データソースコネクタを有効化し、Glean 回答を再取得
- v3: Glean は v2 回答を使用し、Notion 回答を全600件再取得して再評価
12.1 全体勝率の推移
| バージョン | Glean | Notion | Tie |
|---|---|---|---|
| v1(リトライ後) | 18.8% | 68.8% | 12.3% |
| v2 | 22.2% | 62.7% | 15.2% |
| v3 | 13.5% | 80.5% | 6.0% |
v1 から v2 では、Glean の全コネクタ有効化により勝率が 18.8% から 22.2% に改善しました。一方、v3 では Glean は v2 回答を維持したまま、Notion 回答を全件再取得して再評価したため、Notion の勝率が 80.5% に上昇しました。したがって、v1 → v2 は主として Glean 側の改善、v2 → v3 は主として Notion 側の再取得と再評価条件の変更を反映しています。
12.2 解釈上の注意
- v1 → v2 は、主として Glean 側の接続構成改善の効果を観測した段階です
- v2 → v3 は、Notion 回答の再取得と再評価を含むため、単純な性能変化ではなく比較条件の対称性向上も反映しています
- このため、v3 を現時点で最もバランスの取れた主結果として扱います
13. ベンチマークの限界と注意事項
本ベンチマークの結果を解釈する際は、以下の制約を考慮する必要があります。
- 対象企業が 1社のみです。株式会社クラウドネイティブ 1社での結果であり、他企業への一般化には複数企業での追加検証が必要です
- Notion 中心の情報構造です。当社は Notion ワークスペースを社内情報の中心に据えています。Notion の利用度が低い企業では異なる結果になる可能性が高いです
- 評価者のバイアスです。回答取得には Claude Opus 4.6、評価には Claude Sonnet 4.6 を使用しました。いずれも Anthropic 社の Claude ファミリーであり、同一ベンダーのモデルで回答取得・評価の両方を行っている点はバイアス源となり得ます。ブラインド方式(A/B シャッフル、ベンダー名非開示)でバイアスを低減していますが、LLM 評価者固有の傾向が残る可能性があります。理想的には GPT-4o や Gemini 等の他社モデルでの交差検証が望まれます
- Glean の有効回答率です。v2 では 600件中 42件(7.0%)で Glean が有効回答を返せませんでした(v1: 87件、14.5%)。chat API の不安定性が主因です
- 処理時間の比較制約です。MCP(Model Context Protocol)経由での計測であり、各社の直接 API 呼び出しとは処理時間が異なります。MCP のオーバーヘッドが含まれるため、絶対値としての処理時間比較は参考値です
- 質問設計の影響です。質問は 5カテゴリ各120件の均等配分で設計しています。実際の業務利用パターンとは分布が異なる可能性があります
- 検索戦略の影響です。Notion は workspace_search + ai_search の併用戦略を採用しました。この戦略の有無で結果が根本的に変わることが過去の E2E テストで確認されています。各システムの「最適な使い方」で比較している点に留意してください
14. Glean への改善提案(ベンダー送付版)
この節の読み方
- issue / failure_mode: 本評価で観測されたユーザー体験または回答品質上の課題
- evidence: 600問評価で観測した集計値
- possible_explanation: 観測結果から考えられる要因。内部実装の断定ではありません
- confidence: 観測と提案の結びつきの強さ
- repro_hint: 匿名化した再現ヒント
- recommended_change: ベンダー側で検討しやすい改善案
なお、本章で用いる real_world は接続済みデータソースをそのまま用いる実運用条件、shared_retrieval は Notion 内情報で回答可能な質問集合を用いた準制御条件を指します。
14.1 ユーザビリティ観点
1. 回答本文と引用の対応関係を、利用者から追いやすくしてほしい
- issue: 回答本文の各主張と、どの引用がそれを支えているかを追いにくいケースがあった
- observed_pattern: 複数ドキュメントをまたぐ回答で、引用は提示される一方、本文中のどの主張をどの出典が支えているかが分かりにくい場面があった
- user_impact: 利用者が重要な主張の裏づけを素早く確認しづらく、回答の信頼性を自己判断するコストが上がる
- evidence: citation_quality は Glean 2.12、Notion 3.70。cross_source_synthesis での Glean 勝率は 2.5% だった
- confidence: High
- repro_hint: 複数ソースから担当者、決定事項、現状を一つの回答に統合する質問
- recommended_change: 回答文中の要点ごとにインライン引用アンカーを付与する、または本文の各主張の近くに根拠ソースを表示する
2. 情報不足時の留保を、利用者にもっと分かりやすく伝えてほしい
- issue: 証拠が十分でない質問で、回答可能範囲と不明範囲の切り分けが利用者に十分伝わらないケースがあった
- user_impact: 利用者が不確実な情報を確定情報として受け取るおそれがある
- evidence: insufficient_evidence では Glean 0.0%、Notion 88.9%。unanswerable では Glean 20.0%、Notion 55.0%。重大エラーでは overconfident_statement 65件、unsupported_claim 40件が観測された
- confidence: High
- repro_hint: 証拠が部分的にしか見つからない質問、存在しない可能性がある情報を尋ねる質問
- recommended_change: UI 上で「確認できたこと」「確認できなかったこと」を分けて表示し、必要に応じて明示的に棄権する
3. 本評価環境における Notion 到達範囲を利用者が確認しやすくしてほしい
- issue: 利用者から見て「情報が存在しない」のか「この環境では十分に到達できていない」のかを判別しにくかった
- user_impact: 検索不発時の切り分けが難しく、運用上の説明責任が重くなる
- evidence: shared_retrieval における Glean 勝率は 11.7% で、real_world の 15.3% を下回った
- confidence: Medium
- repro_hint: Notion 内にあるはずの組織情報・手順書・チームページを主要根拠にする質問
- recommended_change: Notion コネクタの対象範囲、同期状態、取得対象オブジェクト種別を確認できる UI / ダッシュボードを提供する
4. バッチ利用時の安定性をさらに高めてほしい
- issue: バッチ取得では、一部の質問で有効回答が返らないケースが残った
- user_impact: 大量処理時にリトライや例外処理が必要になり、運用負荷が上がる
- evidence: 有効回答率は Glean 93.0%、Notion 95.7%。Glean では 42件で有効回答が得られなかった
- confidence: High
- repro_hint: 30件単位の連続実行、5並列での取得
- recommended_change: 一時エラー時の自動リトライ、バックオフ、部分失敗時の再開機構を強化する
14.2 技術的観点
1. 複数ソースの統合回答に改善余地がある
- failure_mode: 複数ソースから得た情報を1つの整合的な回答にまとめる場面で、断片の列挙にとどまるケースがあった
- possible_explanation: クロスソース統合を促すコンテキスト構成、または統合後の要約フェーズに改善余地がある可能性
- evidence: cross_source_synthesis での Glean 勝率は 2.5%(Notion 94.2%)
- confidence: High
- repro_hint: 複数システムに分散した担当者、時系列、決定事項、現状を一つの回答で要約する質問
- recommended_change: 複数ソース統合フェーズを明示し、矛盾がある場合は矛盾を開示した上で暫定判断を返す設計を検討する
2. 本評価環境では Notion 内の構造化情報活用に改善余地が残った
- failure_mode: Notion 内のページ、データベース、関連ページを主要根拠とする質問で、回答品質が相対的に伸びにくかった
- possible_explanation: Notion 内の階層情報、DB プロパティ、関連ページの取り込みまたは活用に改善余地がある可能性
- evidence: shared_retrieval で Glean 11.7%、Notion 82.7%
- confidence: Medium
- repro_hint: Notion のチームページ、プロジェクト DB、方針文書をまたいで答える質問
- recommended_change: Notion 由来データについて、階層・リレーション・関連オブジェクトをまたいだ取得と活用の強化を検討する
3. 証拠が疎なときの断定制御に改善余地がある
- failure_mode: 証拠が薄い場面で、unsupported_claim や overconfident_statement につながるケースがあった
- evidence: unsupported_claim は 40件(6.7%)、overconfident_statement は 65件(10.8%)
- confidence: High
- repro_hint: 断片的な検索結果しか返らない質問、または複数候補があり一意に確定しづらい質問
- recommended_change: 検索結果件数、上位スコア差、引用被覆率などを用いた evidence sufficiency 判定を導入し、閾値以下では留保表現を強める
4. 時点依存クエリで最新情報の優先付けに改善余地がある
- failure_mode: 現在状態を問う質問で、古い情報や断片情報が優先されるケースがあった
- evidence: temporal_status で Glean 17.5%、Notion 71.7%
- confidence: Medium
- repro_hint: 現在の担当、現行ステータス、最新の意思決定を尋ねる質問
- recommended_change: 更新日時や最終変更日の重み付けを強化し、時点依存クエリでは新しい情報を優先する
5. 複雑な質問への頑健性をさらに高めてほしい
- failure_mode: 全難易度帯で差が残り、複数条件・複数主体・時系列を含む質問で特に弱さが出た
- evidence: 難易度別勝率は easy 16.5%、medium 11.0%、hard 13.0%
- confidence: High
- repro_hint: 複数条件、複数主体、時系列、例外条件を含む複雑な質問
- recommended_change: 質問分解、サブクエリ探索、段階的統合を行う multi-step retrieval / reasoning を強化する
14.3 Glean の強み(改善継続を期待する点)
- 広い接続範囲の価値: real_world での Glean 勝率 15.3% は shared_retrieval の 11.7% を上回っており、接続ソースの広さが本評価でも価値として観測された
- 人物・外部情報探索の独自性: Okta、SmartHR、公開 Web、Slack Real Time Search など、Notion だけでは拾いにくい情報の横断探索には独自価値がある
- 改善余地がスコアへ反映される余地が見えた点: v1 18.8% → v2 22.2% の改善は、接続構成や実行条件の改善が成果につながる可能性を示している
15. Notion AI への改善提案(ベンダー送付版)
各フィールドの読み方は 14章の「この節の読み方」を参照してください。
15.1 ユーザビリティ観点
1. 構造化情報への到達をデフォルトで取りこぼしにくくしてほしい
- issue: ai_search 単体利用では、Notion ワークスペース内の組織図、ISMS 文書、チームページなどを取りこぼす場面があった
- observed_pattern: 事前テスト(5件)では ai_search 単体 overall 2.6/5.00、workspace_search 併用で 4.0/5.00 と差が大きかった
- user_impact: MCP API 利用者や AI エージェントが ai_search を単独で呼ぶと、重要な知識ベースに到達しにくい
- confidence: High
- repro_hint: Notion 内の複数ページ・DB を主要根拠にする組織情報、手順、役割定義に関する質問
- recommended_change: MCP API での統合検索エンドポイントを提供する、または
notion-searchの既定挙動で workspace_search 相当を自動併用する
2. 事実・関係性クエリでは、根拠の見せ方をさらに明確にしてほしい
- issue: 単純事実や人物・組織間関係の質問では、主張と参照元の対応が追いにくい場面があった
- evidence: single_hop_fact の Notion 勝率は 74.2%、entity_relationship は 78.3% で、他カテゴリ(71.7〜94.2%)と比べると相対的に低かった
- confidence: Medium
- repro_hint: 人物の役割、所属、責任範囲、組織間関係を1〜2ソースから答える質問
- recommended_change: 各要点ごとにページ名と該当箇所を近接表示し、DB セルやプロパティを直接引用する structured citation を強化する
3. 棄権ではなく部分回答を返せる場面を増やしてほしい
- issue: 部分的には回答可能な質問でも、全否定に近い留保になるケースがあった
- user_impact: 利用者は「何が分かっていて何が未確認か」を判断しづらい
- evidence: abstention_quality は Notion 4.11、Glean 3.54。unanswerable 20件での Tie は 25.0% だった
- confidence: Medium
- repro_hint: 一部だけ根拠が見つかるが、残りは確認できない質問
- recommended_change: 「確認できた情報」「確認できなかった情報」「追加確認が必要な点」を分けて返すフォーマットを導入する
4. バッチ利用時の往復回数と処理時間を下げてほしい
- issue: workspace_search、ai_search、notion-fetch の組み合わせが必要で、実務上の呼び出し回数が多い
- user_impact: エージェント実装とバッチ運用のコストが高い
- evidence: 30件バッチあたり Glean 約6〜12分、Notion 約12〜18分
- confidence: High
- repro_hint: 30件単位の連続実行、5並列での取得
- recommended_change: 並列検索やサーバー側マージを行う API、または fetch を省略しやすい高情報量スニペットの提供を検討する
15.2 技術的観点
1. 検索オーケストレーションをクライアント任せにしない方が使いやすい
- failure_mode: ai_search 単体では構造化情報への到達が弱く、workspace_search 併用で大きく改善した
- possible_explanation: 役割の異なる検索手段をクライアント側で組み合わせないと最適結果に到達しにくい可能性
- evidence: 事前テスト(5件)で ai_search 単体 2.6/5.00、workspace_search 併用 4.0/5.00(+54%)
- confidence: High
- repro_hint: Notion 内の複数ページやデータベースをまたいで答える質問
- recommended_change: サーバー側で検索手段を統合する API、または既定設定での自動オーケストレーションを提供する
2. entity_relationship では DB リレーションの活用余地がある
- failure_mode: 人物・組織・プロジェクト間の関係性を問う質問で、DB 間リレーションやロールアップを十分活かしきれていない可能性がある
- evidence: entity_relationship での Notion 勝率は 78.3% で、cross_source_synthesis(94.2%)や decision_history(84.2%)と比べると相対的に低かった
- confidence: Medium
- repro_hint: 人物、チーム、プロジェクト、役割をまたいだ関係性質問
- recommended_change: リレーション、ロールアップ、関連 DB を補助的に探索し、回答時に関連エンティティを追加取得する仕組みを検討する
3. 少数ながら、引用外の一般化をさらに減らせる
- issue: 件数は少ないものの、引用ページの内容を超えた一般化や断定的表現が残った
- evidence: unsupported_claim は 14件(2.3%)、overconfident_statement は 20件(3.3%)。fabricated_entity は 0件、incorrect_citation は 3件(0.5%)だった
- confidence: High
- repro_hint: 根拠ページに近い情報はあるが、結論まで直接は書かれていない質問
- recommended_change: 生成後に「各主張が引用本文で直接裏付けられるか」を検証する post-generation verification を導入する
4. real_world モードでは情報ソースの幅に改善余地がある
- issue: real_world 条件では shared_retrieval 比で Glean との差が縮小した
- possible_explanation: より広い外部接続を持つシステムが相対優位だった可能性
- evidence: Notion は shared_retrieval 82.7% から real_world 78.3% へ 4.4pp 低下した
- confidence: Medium
- repro_hint: Slack、メール、外部公開情報など Notion 外の文脈があると有利になる質問
- recommended_change: 外部コネクタの拡充、または外部文脈の取り込み手段の強化を検討する
5. hard クエリでは、完全性をさらに伸ばせる余地がある
- failure_mode: 全体として高い勝率を維持している一方、複数ページの横断統合が必要な質問では partial answer にとどまるケースが残った
- evidence: hard での Notion 勝率は 78.5% と高い一方、completeness は 3.65 で他軸より低かった
- confidence: Medium
- repro_hint: 複数ページ、複数エンティティ、複数条件を含む hard 質問
- recommended_change: 追加検索を自動で回す iterative retrieval、または「不足している観点」を検出して補完検索する仕組みを検討する
15.3 Notion AI の強み
- cross_source_synthesis の強さ: 94.2% 勝率で、Notion ワークスペース内の複数ページ・DB を横断した情報統合に強みが観測された
- citation_quality の高さ: 3.70 対 2.12、差 +1.58 と、根拠提示の品質で相対優位があった
- 有効回答率 95.7%: v3 での全 600 件再取得でも高い水準を維持した
- 重大エラーの少なさ: fabricated_entity は 0件、incorrect_citation は 3件(0.5%)。unsupported_claim 14件(2.3%)、overconfident_statement 20件(3.3%)で、Glean(合計 112ラベル)の約 1/3 にとどまった
本フィードバックにおける possible_explanation は、観測結果からの推論であり、各製品の内部実装を断定するものではありません。機微情報保護の観点から、具体例は匿名化し、restricted 以上の質問は例示から除外しています。
16. まとめ(v3 主結果)
v3(Notion 回答全600件再取得 + Glean v2 回答据置)によるブラインド評価の結果、以下が確認されました。
- 当社環境では、Notion AI が全5カテゴリで優勢でした。v3 の全体勝率は Glean 13.5%、Notion 80.5%、Tie 6.0% でした。overall(連続値)は Glean 2.77、Notion 3.78 で、差は +1.01 でした
- v2 での Glean 改善(+3.4pp)は実在しますが、v3 は Notion 側の固定ベースライン問題も解消した、より対称性の高い比較条件です。 有効回答率は Glean 93.0%、Notion 95.7% でした
- 最大差は cross_source_synthesis(約92pp差)です。Glean 2.5% vs Notion 94.2%。複数ページ・DB を横断した統合回答の品質で最も大きな差が出ました
- v3 では、回答品質の差がより明確に観測されました。 citation_quality +1.58、completeness +1.09、context_awareness +1.13、accuracy +0.75、abstention_quality +0.57 と、主要な評価軸で Notion 優位が確認されました
- 全難易度帯で Notion が優勢です。easy 80.0%、medium 83.0%、hard 78.5%。v2 で見られた「easy で接戦」の傾向は v3 では解消されています
- 検索戦略の最適化が結果を根本的に左右します。Notion の workspace_search + ai_search 併用は必須であり、Glean も全コネクタ有効化で改善しました。両システムとも「最適な使い方」で比較した結果です
- 用途が補完的である可能性は引き続き示唆されます。Notion AI は社内構造化情報の検索・統合に強く、Glean は外部ソース横断検索で一定の価値を持ちます。real_world での Glean 勝率 15.3% は shared_retrieval(11.7%)を 3.6pp 上回っています
注記: v3 の重大エラーは Glean 112ラベル、Notion 37ラベルです(Glean が Notion の約3倍)。ただし v2 との直接比較は評価セッション差を含むため避けるべきです(10章参照)。本レポートは株式会社クラウドネイティブ 1社のケーススタディであり、製品一般の普遍的優劣を示すものではありません。Notion の利用度、Glean のデータソース接続構成、検索戦略、MCP 実装により結果は変動し得ます。
付録 A: 再現性情報
本ベンチマークの第三者検証に必要な情報を以下にまとめます。
A.1 実行環境
| 項目 | 内容 |
|---|---|
| 実行基盤 | Claude Code セッション内で直接実行(外部 API キー不使用) |
| 回答取得エージェント | Claude Opus 4.6(claude-opus-4-6)サブエージェント。両システムとも同一モデル |
| MCP サーバー | Glean MCP / Notion MCP(claude.ai managed servers) |
| ブラインド評価モデル | Claude Sonnet 4.6(claude-sonnet-4-6)サブエージェント |
| 総合評価モデル | Claude Opus 4.6(claude-opus-4-6)メインセッション |
| シャッフル方式 | SHA-256 (run_id + question_id + fixed_salt) による決定論的 A/B 割り当て |
| v3 run_id | run_v3_retest_20260329 |
| 並列数 | 回答取得: 5エージェント並列 / 評価: 20バッチ×30件 |
A.2 overall 算出方法
- 重み: accuracy 0.315 + completeness 0.265 + citation_quality 0.16 + context_awareness 0.16 + abstention_quality 0.10 = 1.0(5軸、responsiveness は参考指標として分離)。重みづけの根拠として、エンタープライズサーチの最重要要件である「正確性」(accuracy)と「網羅性」(completeness)に全体の約58%を配分し、citation_quality と context_awareness は信頼性検証の要素として同等に扱い、abstention_quality は補助指標として最小の重みとしました
- 各質問単位で重み付き平均を算出 → 整数に丸め → 全600件の平均
A.3 評価プロンプトの構造
評価プロンプトは以下の構成です。
- 質問文と Ground Truth(must_include / must_not_claim)を提示
- Answer A と Answer B をベンダー名を伏せて提示
- 6軸(accuracy, completeness, citation_quality, context_awareness, abstention_quality, responsiveness)で 1-5 の整数採点を指示
- 重大エラー4種の真偽判定を指示
- winner(A / B / tie)と reasoning を出力
A.4 正規化ルール
20バッチのサブエージェントが異なるスキーマで出力したため(5.4節参照)、以下のパターンを統一スキーマに変換しました。
answer_a/answer_b形式(スコアが回答オブジェクト内): 240件scores_a/scores_b形式(スコアが分離): 300件answer_a_scores/answer_b_scores形式: 60件
A.5 公開可能資料と非公開資料
公開可能資料
- 匿名化した質問ID別集計表
- 評価プロンプトの構造
- 集計ロジックの概要
- 指標定義と正規化ルール
非公開資料
- 生の質問本文
- Ground Truth の全文
- 回答本文の生データ
- 社内固有情報を含む中間生成物
- restricted 以上の内部資料
- 実行ログのうち機密情報を含む部分
社内情報保護の観点から、生データ一式は公開しません。ただし、第三者が結果の解釈を検証できるよう、集計ロジック、評価手順、匿名化済み集計表を公開可能対象とします。