はじめに
こんにちは、俊介です。 2025アドベントカレンダー16日目担当です!
Cloudnative IRS Advent Calendar 2025 – Adventar
僕は最近のAIのトレンドだったり、ちょっと前のトレンドだけどお客様のやりたい事を一緒に解決したことをどのように実装したか等を書いています。
チームメンバーがいろんなジャンルのブログを書いていますのでぜひ覗いてみてください!
今日のお話しを簡単に
今日はAzure AI Search(以下、AI Search)のインデックスにBoxのデータを入れてRAGBotで利用出来るようにするお話しです。
やってみようと思った背景
私は今までAI Searchで用意されてるデータソースでしかインデックスは作れないもんだと思っていました。 しかし、Advent alendarやるってなって、最近なんかできること増えてないかな?って調べていたら気になる記事が。
Microsoft Foundry Blog | Push method for Azure AI Search
これはMicrosoftが出しているブログなんですが、気になるのはインデックスにデータを送信する方法が2つあるらしいと。 最初は、「へえ」と思いながら読んでいたんですがプッシュ方式のデータソースのサポートに目がとまりました。
これは、AI Searchのインデックスに入れれるデータの幅が広がるぞ!と。
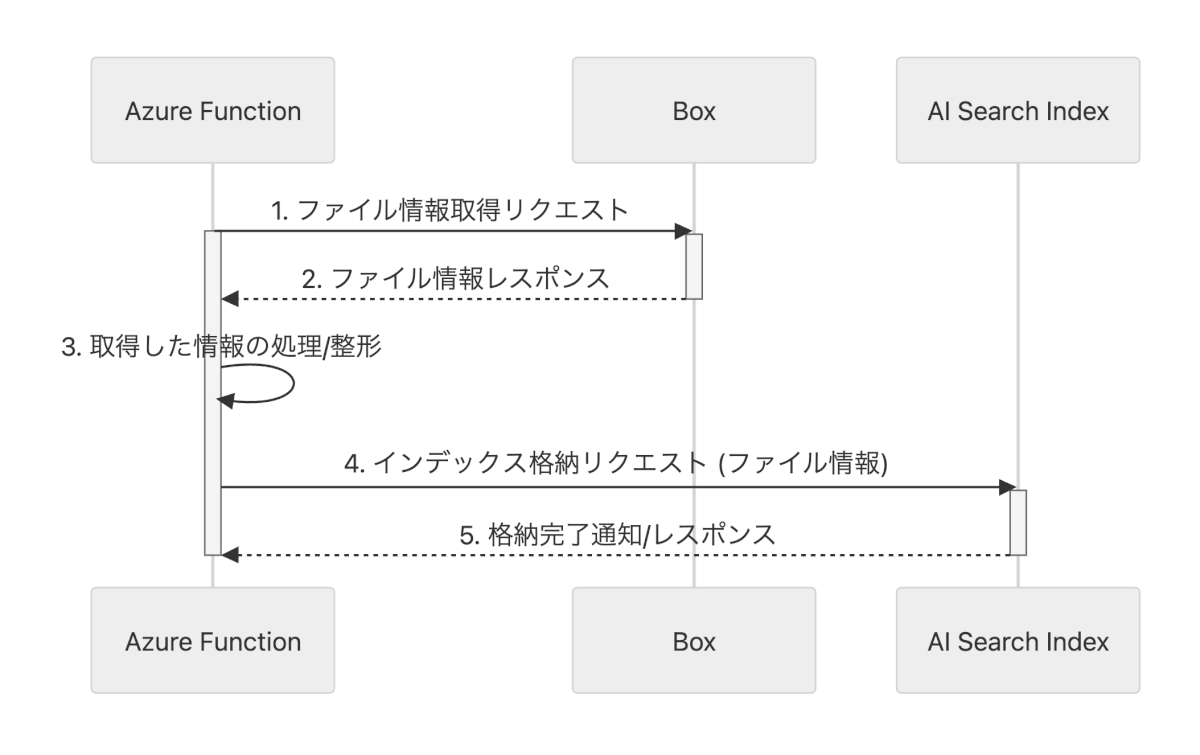
シーケンス図
今回実装するものはシーケンス図にするとこんな感じです。
実際にやってみる
準備するもの
- Box App サービスアカウントを作成してAPI操作をしていきます
- 認証はJWT認証です
AI Searchのインデックス
- データを入れる為の箱になります
Azure Functions
- Boxのファイル取得やインデックスにデータ投入を行う処理を入れます
VS Code
- Azure Functionsに関数コードをデプロイする為に使います
Python
- 今回の実行言語
Box Appの作成
- Boxにログインして、左下の「開発者コンソール」>[Platformアプリ]>右上「Platformアプリの作成」を押下
- カスタムアプリを選択
- フォームを入力して「次へ」を押下 アプリ名:例)BoxToIndex App 目的:統合 カテゴリ:AI 統合する外部システム:例)Azure
- 認証方法は「サーバー認証(JWT使用)」を選択して「アプリの作成」を押下
- [構成]タブの[アプリアクセスレベル]セクションを「アプリ + Enterpriseアクセス」に変更
- [公開キーの追加と管理]セクションで「公開/秘密キーペアを生成」を押下してJSONファイルをDL(後続の作業の環境変数の設定で利用するので大事に保管)
- 「変更を保存」を押下
- [承認]タブにいき、「確認して送信」を押下 ▼申請するとこの状態になる
- [管理コンソール]>[統合]>[Platformアプリマネージャ]へ移動し、対象のAppがあることを確認
- 右上の「承認」を押下して確認画面が開くのでもう一度「承認」を押下
- [開発者コンソール]>[Platformアプリ]>[対象アプリ]>[承認]へ画面遷移して
承認ステータス、有効化ステータスが変わっているのを確認 - インデックスにデータを入れたいフォルダに今回作成したアプリのサービスアカウントを追加する
インデックスを作成
- [Azure Portal]>[AI Search]>[作成したいインデックスのAI Search]へ画面遷移 ▼Azure Portal画面 ▼操作するAI Search選択
- [検索管理]>[インデックス]>「+インデックスの追加」>「インデックスの追加」を順番に押下
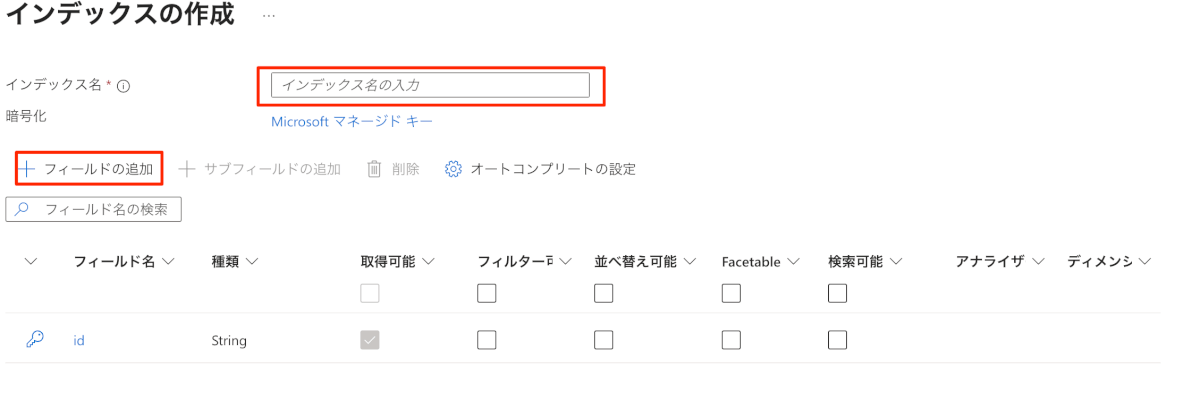
- インデックス名と「+フィールドの追加」からフィールドを追加していく
今回以下をフィールドに追加しました。
id(デフォルトで入ってる):BoxのファイルIDを入れます file_name:Boxのファイル名を入れます content:ファイルの中身を入れます file_type:ファイルの拡張子を入れます folder_path:ファイルパスを入れます last_modified:最終更新時間を入れます size_bytes:ファイルサイズを入れます url:ファイルのURLを入れます
| フィールド名 | 種類 |
|---|---|
| id | Edm.String |
| file_name | Edm.String |
| content | Edm.String |
| file_type | Edm.String |
| folder_path | Edm.String |
| last_modified | Edm.DateTimeOffset |
| size_bytes | Edm.Int64 |
| url | Edm.String |

4. インデックスの名前をコピーしておく 後続の作業の環境変数の設定で利用します
5. [概要]セクションに移動して、AI Searchのエンドポイントをコピーしておく 後続の作業の環境変数の設定で利用します
6. セクションに移動して、AI SearchのAPIキーをコピーしておく 後続の作業の環境変数の設定で利用します
Azure Functionsの作成
- [Azure Portal]>[関数アプリ]へ画面遷移して「+作成」を押下
- 関数アプリのプランを選択 今回は検証なのでフレックス従量課金を選択しました
- 基本情報を設定 リソースグループ:すでに作成してる場合は、トグルから選択。未作成の方は作成をしてください リージョン:作成する関数をどこのリージョンで動かすかをトグルから選択 バージョン:端末にインストールしたPythonバージョンを選択してください
- 今回は検証なので、[基本情報]以外はスキップして「確認および作成」を押下
- この画面になればOKです
環境変数の設定
機密情報をコード内に含めないためにAzure Functionsの環境変数を利用して、コードから取得するようにしています。 ここの手順では、その環境変数を設定していきます。
[Azure Portal]>[関数アプリ]>[該当の関数アプリ]>[設定]>[環境変数]へ移動して変数を作成して値を入れて「適用」を押下
Box Appの作成手順で取得したJSONファイルからコピペで貼り付けます
- BOX_CLIENT_ID
- BOX_CLIENT_SECRET
- BOX_ENTERPRISE_ID
- BOX_PRIVATE_KEYJSONファイルDL段階ではキーは暗号化されているので復号化した上でいれてください
- これはBoxのセキュリティ上の仕様です
BOX_PUBLIC_KEY_ID AZURE_SEARCH_INDEX_NAME
- インデックス作成の手順4で作成したインデックス名を入れる
AZURE_SEARCH_ENDPOINT
- インデックス作成の手順5でコピーしたエンドポイントを入れる
AZURE_SEARCH_API_KEY
- インデックス作成の手順6でコピーしたAPIキーを入れる
VS CodeでAzure Functionsに処理コードの関数をデプロイ
VS Codeの拡張子を使ってAzure Functiins関数アプリをデプロイします
- VS Codeを開いて「Azure Functions」の拡張子をインストール
- Azureにログイン
- 「Create Function Project…」を押下して関数の土台を作成しいく
- プロジェクトフォルダの場所を選択(今回は新規でプロジェクトフォルダを作成して「Select」を押下)
- 言語の選択は「Python」を選択
- 言語のバージョンはインストールしたPythonのバージョンを選択
- 今回検証でAzure Functions上で試すので「HTTP trigger」で大丈夫です
- 関数名を入れてEnter(Azure Functionのポータル上にも表示される)
- リクエストを飛ばす際の認証方法を選択(今回はFunctionを選択)
- 今開いてるVS Codeの画面をそのまま使うので、「Open in curent window」を押下
- function_app.pyに下記を貼り付けて保存 ▼変更箇所 156行目:8. で設定した関数名を入れてください 157行目:8. で設定した関数名を入れてください 160行目:Box App作成の12. で共有したBoxのフォルダIDを入れてください
import azure.functions as func import os import logging import jwt import requests import uuid import time import io from docx import Document from pypdf import PdfReader from azure.core.credentials import AzureKeyCredential from azure.search.documents import SearchClient app = func.FunctionApp(http_auth_level=func.AuthLevel.FUNCTION) BATCH_SIZE = 50 def get_box_access_token(): client_id = os.environ.get('BOX_CLIENT_ID') client_secret = os.environ.get('BOX_CLIENT_SECRET') private_key = os.environ.get('BOX_PRIVATE_KEY').replace('\\n', '\n') public_key_id = os.environ.get('BOX_PUBLIC_KEY_ID') enterprise_id = os.environ.get('BOX_ENTERPRISE_ID') jwt_body_claim = { "iss": client_id, "sub": enterprise_id, "box_sub_type": "enterprise", "aud": "https://api.box.com/oauth2/token", "jti": uuid.uuid4().hex, "exp": int(time.time()) + 60 } jwt_token = jwt.encode( jwt_body_claim, private_key, algorithm="RS512", headers={"kid": public_key_id} ) token_url = "https://api.box.com/oauth2/token" payload = { "grant_type": "urn:ietf:params:oauth:grant-type:jwt-bearer", "assertion": jwt_token, "client_id": client_id, "client_secret": client_secret } response = requests.post(token_url, data=payload) response.raise_for_status() return response.json().get('access_token') def get_box_folder_items(access_token, folder_id): url = f"https://api.box.com/2.0/folders/{folder_id}/items" headers = {"Authorization": f"Bearer {access_token}"} resp = requests.get(url, headers=headers, params={"limit": 10}) resp.raise_for_status() return resp.json() def get_box_file_metadata(access_token, file_id): url = f"https://api.box.com/2.0/files/{file_id}" headers = {"Authorization": f"Bearer {access_token}"} resp = requests.get(url, headers=headers) resp.raise_for_status() return resp.json() def download_box_file(access_token, file_id): url = f"https://api.box.com/2.0/files/{file_id}/content" headers = { "Authorization": f"Bearer {access_token}" } resp = requests.get(url, headers=headers) if resp.status_code != 200: raise Exception(f"Box file download error: {resp.status_code} {resp.text}") return resp.content def extract_text_from_file_bytes(file_bytes, file_name): file_extension = file_name.split('.')[-1].lower() text_content = "" try: if file_extension == 'txt': text_content = file_bytes.decode('utf-8', errors='ignore') elif file_extension == 'pdf': pdf_file = io.BytesIO(file_bytes) reader = PdfReader(pdf_file) for page in reader.pages: extracted = page.extract_text() if extracted: text_content += extracted + "\n" elif file_extension == 'docx': doc_file = io.BytesIO(file_bytes) document = Document(doc_file) for para in document.paragraphs: text_content += para.text + "\n" else: logging.warning(f"Unsupported file type: {file_extension}. Indexing metadata only.") text_content = f"File type: {file_extension}, File name: {file_name}" return text_content if text_content else f"[No text content extracted for {file_name}]" except Exception as e: logging.error(f"Error extracting text from {file_name} ({file_extension}): {e}") return f"[Error extracting content for {file_name}]" def build_folder_path(file_metadata): entries = file_metadata.get("path_collection", {}).get("entries", []) folder_names = [e["name"] for e in entries if e["id"] != "0"] return "/" + "/".join(folder_names) if folder_names else "" def process_box_folder_recursive(access_token, folder_id, documents_to_upload, parent_path=""): items = get_box_folder_items(access_token, folder_id) for entry in items.get("entries", []): if entry["type"] == "folder": folder_path = f"{parent_path}/{entry['name']}".replace("//", "/") logging.info(f"Processing folder: {folder_path}") process_box_folder_recursive(access_token, entry["id"], documents_to_upload, folder_path) elif entry["type"] == "file": file_id = entry["id"] file_name = entry["name"] logging.info(f"Processing file: {file_name} ({file_id})") try: file_bytes = download_box_file(access_token, file_id) file_metadata = get_box_file_metadata(access_token, file_id) file_content = extract_text_from_file_bytes(file_bytes, file_name) folder_path = build_folder_path(file_metadata) document = { "id": file_id, "file_name": file_name, "content": file_content, "file_type": file_name.split('.')[-1] if '.' in file_name else "unknown", "folder_path": folder_path, "last_modified": file_metadata.get("modified_at"), "size_bytes": file_metadata.get("size"), "url": f"https://app.box.com/file/{file_id}" } documents_to_upload.append(document) except Exception as e: logging.error(f"Error processing file {file_name} ({file_id}): {e}") def push_batch_to_search(search_client: SearchClient, documents: list): search_documents = [] for doc in documents: search_documents.append({ "@search.action": "mergeOrUpload", **doc }) try: results = search_client.upload_documents(documents=search_documents) result_list = getattr(results, "results", results) success_count = sum(1 for r in result_list if getattr(r, "succeeded", False)) failure_count = len(result_list) - success_count logging.info(f"Batch Push Result: Succeeded: {success_count}, Failed: {failure_count}") for r in result_list: if not getattr(r, "succeeded", False): logging.error(f"Failed to index document: {getattr(r, 'key', '')}") except Exception as e: logging.error(f"Error pushing batch to Azure AI Search: {e}") @app.route(route="<関数名>") def <関数名>(req: func.HttpRequest) -> func.HttpResponse: try: access_token = get_box_access_token() folder_id = req.params.get("folder_id", "インデックスさせたいフォルダID") documents_to_upload = [] process_box_folder_recursive(access_token, folder_id, documents_to_upload) search_endpoint = os.environ.get("AZURE_SEARCH_ENDPOINT") search_key = os.environ.get("AZURE_SEARCH_API_KEY") index_name = os.environ.get("AZURE_SEARCH_INDEX_NAME") search_client = SearchClient( endpoint=search_endpoint, index_name=index_name, credential=AzureKeyCredential(search_key) ) if documents_to_upload: push_batch_to_search(search_client, documents_to_upload) return func.HttpResponse( f"Box→Azure Search連携完了!件数: {len(documents_to_upload)}", status_code=200 ) except Exception as e: logging.error(f"Error: {e}") return func.HttpResponse(f"Error: {e}", status_code=500) 12. requirements.txtに下記のコードを貼り付けて保存

実行!
- 先ほど表示された関数名を押下して開く
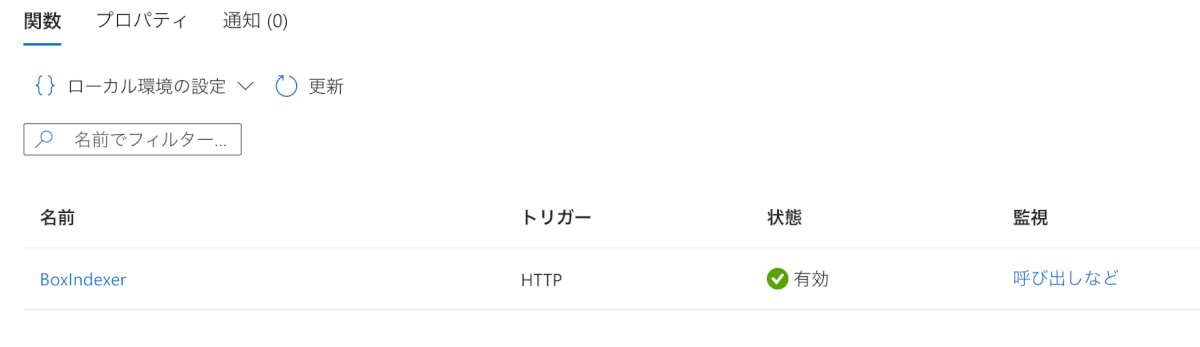
- [コードとテスト]>「テスト/実行」>「実行」を順番に押下
- 無事成功して、インデックスに入れたみたい
- インデックス作成した画面に移動して検索してみると…
※もし、ドキュメント0だったりまだ何もなさそう雰囲気のときは「最新の情報に更新」を押下してから「検索」をすると表示されるケースもあります。(反映の問題)
所感
- 素晴らしい!!!!!
- これ毎回実行すると全ファイル読み込むのかな? 従来のやり方だと差分だけ実行されるようになってるけど
汎用的なものにすればAzure Functions数個で色々なDBを繋げれてインデックス作成できそう AzureでRAGの基盤作成したいのに、対応してるクラウドストレージないよ…って会社さんは嬉しそう SaaSに標準で用意されてるAIも近年多く出てるけど、ケースによっては今回のシステムが良かったりするのかな?
- 例えばBoxの場合、Box AI for Hubsで簡単にRAG構築できるけど、アドオンコストが高かったり簡単に出来るが故のカスタマイズがあんまり出来ないとか色々ある
- まあここら辺はどんどん進化しているので最近はカスタマイズできたりするSaaSもあるけど
さいごに
ここまで読んでくださってありがとうございました! 今回は一般的に有名なインデックスにデータを送るやり方とは別の方法で試してみました! 今までAI Search対応していないと思っていた事ができる事が増えそうで夢が広がりましたね。 他のものとも連携できそうなのでやってみようかと思います。 次回はBox AI for HubsをTeamsから実行するブログを書こうかな….また会う日まで