はじめに
どうも、たにあんです。久しぶりにmakeの記事です。
ここ1〜2ヶ月で、makeさんもそこそこアップデートされていまして、AI Agentなどのアップデートはあったものの機能としてはイマイチなような感覚もありつつ…
そんなところ、2025年4月に以下のようなアップデートがありました。いまさらですが触れていきます。
- Return Outputs Module
- Synchronous Execution Mode
- Start a Subscenario Module
少なくともWorkatoではできていたRecipe間の依存関係をmakeでは構成することができず、Scenarioを作成する際に苦戦したものです。
iPaaSのアップデート内容としては地味ながら、大変嬉しい機能です。
概要
忙しい人向け、なんとなく知りたい方向けの内容です。
- 従来は、あるScenario(便宜的に親Scenario)から別のScenario(子Scenario)を実行するために必要な機能が不足していました。
- 例えば…
- 親Scenarioから子Scenarioを実行した際、元のScenarioへ結果を返すことができませんでした。
- 子Scenarioの実行完了を待つことができませんでした。
- 例えば…
- 子Scenarioの実行結果に応じて同じ処理を複数回実行させたいような状況でも、同じ処理を構築する必要がありました。
- 2025年4月のアップデートでScenario間の連携がスムーズにできるようになり、上述の内容はすべて解決しました。
以降は、機能を中心に解説していきます。
Subscenario とは?
Subscenario とは、「他のScenarioから呼び出して利用できる、独立した小さなScenario」です。makeにおいてはCall a subscenario Moduleを使って別のシナリオを呼び出します。
再利用可能な形で1つのScenarioを作成しておくことで、SubscenarioとしてあらゆるScenarioから呼び出すことができるようになります。
具体的な利用の流れは以下の通りです。
- 呼び出される側(
Subscenario= 子Scenario):- 最初のModuleには
Start a subscenarioを使用し、外部からのデータを受け取る準備をします。- 受け取るデータは
Scenario Inputsで定義します。
- 受け取るデータは
- 処理を実行します。
- 処理結果を
Return outputsModuleで呼び出し元に返します。- 親Scenarioに返すためのデータは
Scenario Outputsで定義します。
- 親Scenarioに返すためのデータは
- 最初のModuleには
- 呼び出す側(親Scenario):
Scenarioカテゴリの中にあるCall a subscenarioを使用してSubscenarioを呼び出します。Subscenarioに必要なデータを渡します。Subscenario側で設定したScenario inputsを使用します。
Subscenarioからの処理結果を受け取って、後続の処理に利用します。Subscenario側で設定したScenario outputsを使用します。
機能詳細
Scenario inputs / outputs
Scenario inputsは、親Scenarioから子Scenarioに特定の値を渡すときに利用する機能です。Scenario outputsは、子Scenarioから親Scenarioに特定の値を返すときに利用する機能です。
いずれも子Scenarioで設定する必要があり、呼び出し元の親Scenarioでは、
値の変数名(Name)と型(Type)を設定すると使用することができます。Requiredにチェックをつけた場合は、「呼び出し元で値を必ず渡すように強制する」ことになります。
以下に一例を示します。
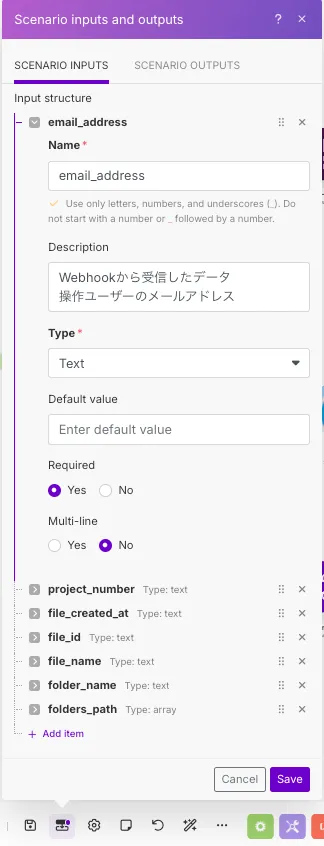
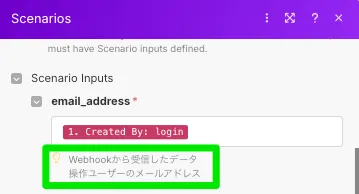
ちなみに、説明欄(Description)は、親Scenarioから渡す値を指定する際に表示されます。Scenario Inputsを設定するときの必須項目ではありませんが、記載することをオススメします。
Call a subscenario module
親Scenarioで使用するModuleです。既に作成されているScenarioを子Scenarioとして呼び出すことができます。
設定画面は以下のようになっています。
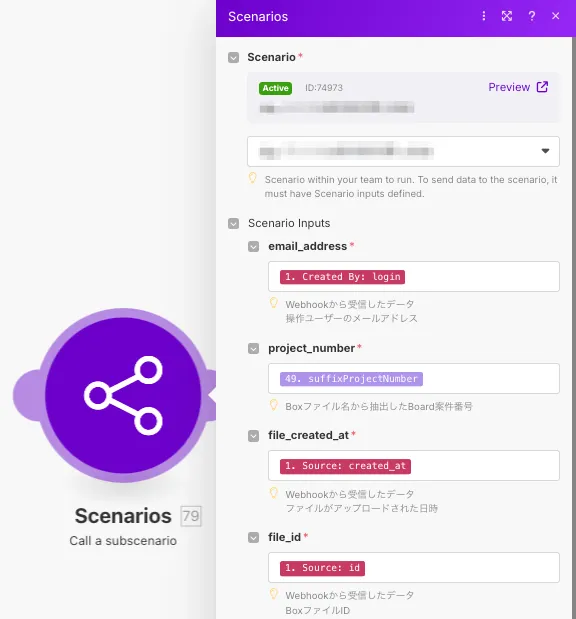
Scenario Inputsの項目は、指定したSubscenarioで設定されているScenario Inputsが表示され、親Scenarioから子Scenarioへ引き継ぐ値を指定することができます。Scenario Inputsの各名称の横にアスタリスクがついている項目は、必ず何かしらの値を入力しなければいけません。これは前項のRequiredの設定に依存します。
また、子Scenarioの実行を待つこともでき、適切なタイミングで後続の処理を実行させることが可能です。
もちろん、Call a subscenario の結果を待たずに、複数のScenarioを並行して実行することも可能です。
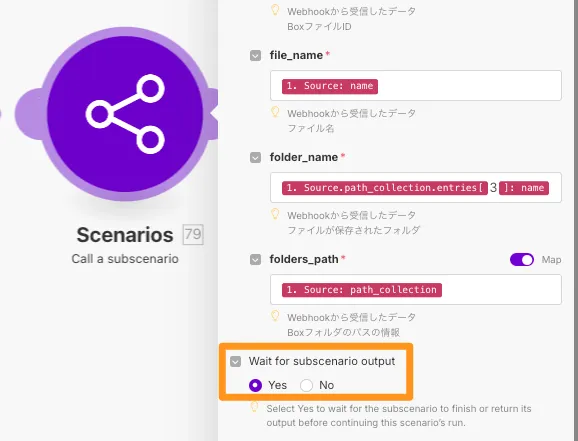
ちなみに、Call a subscenarioはmakeのOperationsを消費しません。
Start a subscenario module
Subscenarioの最初のModuleとして使用します。置かなくてもSubscenarioとして機能しますが、必ず配置しましょう。
処理的には何もしませんが、Scenarioの実行履歴(History)を確認する際に役に立ちます。Start a subscenarioを配置しない場合、Scenario inputsとして受け取った値を確認する方法は、以下のいずれかになります。
- 親Scenarioの
Call a subscenarioで渡した値を見る。つまり、親Scenarioの実行履歴を確認する。 - 子Scenario内のModuleで
Scenario inputsを使用しているModuleを確認する。
非常に手間がかかる作業になってしまうため、配置しない理由がありません。Start a subscenarioがあれば、一目でScenario inputsとして受け取った値が分かります。
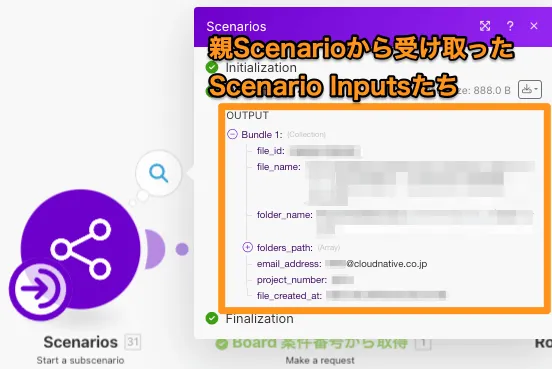
ちなみに、Start a subscenarioもmakeのOperationsを消費しません。
Return outputs module
子Scenarioから親Scenarioにデータを返すときに利用します。そのため、子Scenarioに配置します。
すでに説明したScenario outputsで設定した変数を使って返します。
子Scenarioの実行履歴を確認すると以下のようになっており、親Scenarioで返す値がログで表示されます。
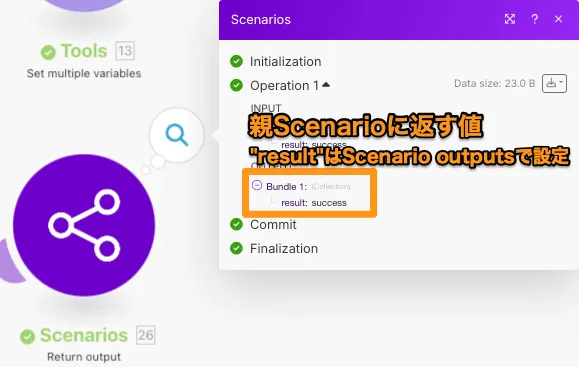
また、対応する親ScenarioのCall a subscenarioの実行履歴を見ると、同じ値が返ってきています。
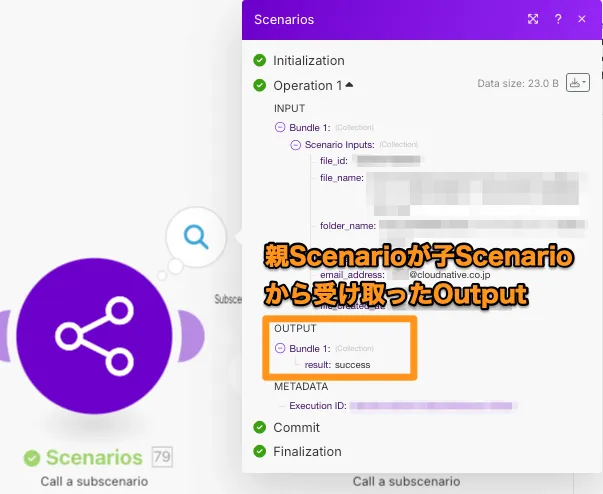
ちなみに、Return outputsもmakeのOperationsを消費しません。
Subscenarioのメリット
Subscenario を活用することで、以下のような多くのメリットが得られます。
- シナリオのモジュール化と再利用性の向上:
- 共通して利用する処理(例えば、エラー通知、特定サービスへのデータ登録、複雑なデータ整形など)を
Subscenarioとして切り出すことで、何度も同じ処理を組む必要がなくなります。 - 一度作成すれば、あとは呼び出すだけでOKです。楽ちんです。
- 共通して利用する処理(例えば、エラー通知、特定サービスへのデータ登録、複雑なデータ整形など)を
- 複雑なシナリオの可読性と保守性の向上:
- 一つの巨大なシナリオは、処理の流れを把握しにくく、修正やデバッグも困難になりがちです。
- Module数が30個近くなると、1つの画面で収まらなくなるシチュエーションも多く、見やすいmakeのUIを損ねることにもなります。
Subscenarioを使って処理を適切に分割することで、各シナリオの役割が明確になり、全体の構造がシンプルになります。
- 一つの巨大なシナリオは、処理の流れを把握しにくく、修正やデバッグも困難になりがちです。
- エラー処理の共通化と強化:
- エラーハンドリングの処理を
Subscenarioに集約できます。例えば、エラー発生時に特定チャンネルへ通知を送ったり、エラーログを記録したりする処理を共通化できます。
- エラーハンドリングの処理を
Subscenarioのユースケース
考えられる汎用的なユースケースは、以下のようなものがあります。
- データのバリデーション
- メールアドレスの形式チェック、電話番号の正規化といったバリデーション処理を
Subscenarioにまとめる。
- メールアドレスの形式チェック、電話番号の正規化といったバリデーション処理を
- 通知処理
- シナリオの成功・失敗時に、Slackやメールなど複数のチャネルに状況に応じたメッセージを送信する処理を
Subscenarioにまとめる。
- シナリオの成功・失敗時に、Slackやメールなど複数のチャネルに状況に応じたメッセージを送信する処理を
- ファイル処理の共通化
- Google Drive や Dropbox へのファイルアップロード、特定フォルダからのファイル取得、ファイル名の変更といった一連のファイル操作を
Subscenarioにする。
- Google Drive や Dropbox へのファイルアップロード、特定フォルダからのファイル取得、ファイル名の変更といった一連のファイル操作を
コラム:個人的にウキウキしているユースケース
makeのマニアックな話になります。makeをあまり知らないという方は、飛ばしていただいて構いません。
前述のユースケースの中で、通知処理には可能性を感じています。
エラーの通知処理を楽に行うために、自動化の主な処理をSubscenarioとして実行するという使い方があり得ると考えています。
子Scenarioでは処理の実行結果と、必要に応じてエラーをキャッチさせて親Scenarioに返すことで、親Scenarioにのみ通知処理を実装させるということです。
もう少し具体的に説明していきます。
まず背景から。makeにとって、エラーに伴う通知処理が厄介です。
Scenarioの任意の箇所でエラーが発生した場合、特定の処理を実行するということができません。
Workatoの場合、以下のような形で一定の範囲内でエラーが発生した場合、エラーをキャッチしたときの処理を一括で実装することができます。
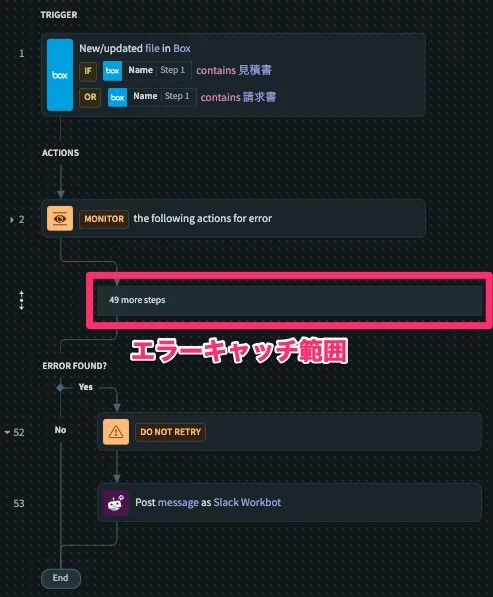
makeの場合、以下の画像の橙枠に対してエラー処理を入れる必要があります。
厳密に実装するなら、すべてのModuleに対してエラー処理が必要ですが、やってられないので以下のようなポイントを重点的に対応する形になると思います。
- 外部サービスのAPIを呼び出している箇所
- 条件分岐で想定外の挙動やデータが処理される箇所
- Data Storeを含むデータベースの更新などの箇所
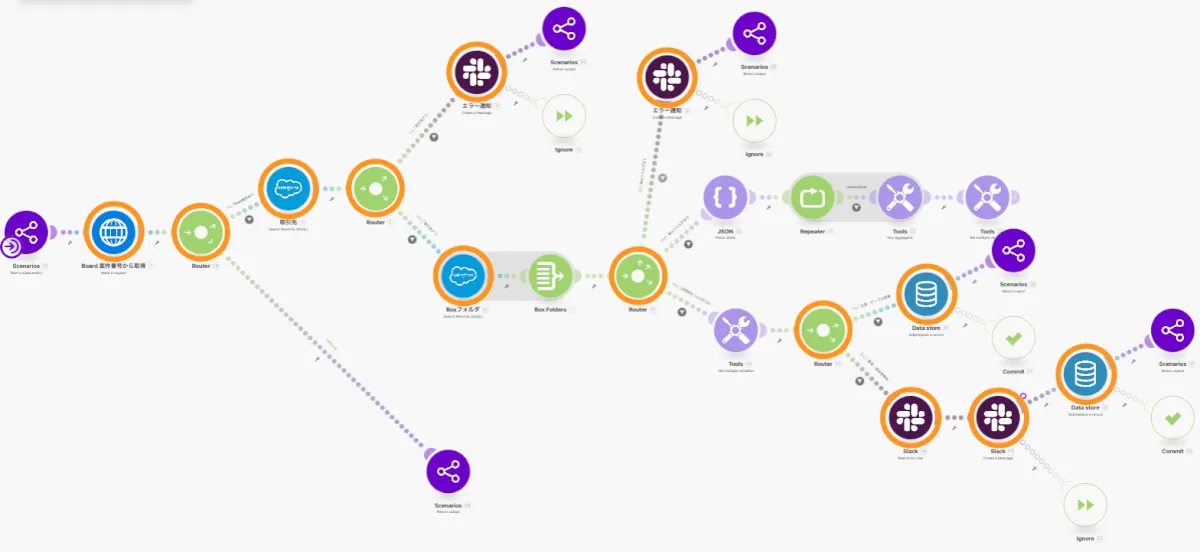
上の画像の場合、エラー処理を実装した方がよいと考えられる箇所は10箇所以上(橙枠)あり、各箇所にエラー通知処理(Slackにメッセージを投稿するなど)のModuleを配置するかと言われると、やりたくないというのが正直なところです。
Slackの場合、blocksを何度も見たくありません。Moduleをコピーすればいいじゃんと言われればそれまでですが、後々メンテナンスする可能性も考えると、設定するModuleが少ないか、あるいは設定が楽な方がよいです。
(想定外のエラーが出るScenarioを作っていること自体ナンセンスみたいなツッコミはなしでお願いします。)
そこで、メインの処理をSubscenarioとして実装し、子ScenarioからReturn outputsで親Scenarioに実行結果とエラーを返してあげることで、親Scenarioで子Scenarioから受け取った結果に応じて処理させることができれば、Slackのblocksをたくさん見る必要もなくなります。
それでもReturn outputsの設定は必要ですが、その他Moduleの設定項目の多さに比べれば大したことはないので、かなり楽になると考えています。
ちなみに、makeでは各Moduleに対してError Handling用の分岐を設定することができます。対象のModuleでErrorが発生した場合に、正常に実行された際の分岐とは異なるルートを設定することができるものです。
Error Handlingの分岐には、専用のModuleもありますが、Return outputsを配置することも可能です。
おわりに
今回は、Makeの Subscenario 機能について解説しました。Subscenario は、自動化をより効率的、効果的、そして管理しやすいものへと進化させる手段です。
一度その便利さを体験すれば、きっと手放せなくなるはずです。ぜひ、日々の業務で共通化できそうな処理や、複雑になりすぎたScenarioの見直しに、Subscenario の導入を検討してみてください。
用語解説
- Scenario:どのような処理を自動化するか定義されたものです。ZapierのZaps、Power Automateのフロー、WorkatoのRecipeに相当します。
- Module:Scenario内で利用できる操作そのものです。ZapierやPower Automate、Workatoのアクションに相当します。
- Operations:Moduleを実行できる回数です。makeの課金形態は従量課金であり、金額に応じて一定期間内で利用できるOperationsが変わります。
- Data Store:makeで利用できるストレージです。WorkatoのLookup Tableに相当します。