
生成AI全盛期ですが、そのマネタイズモデルはまだ未知数であり、未知数だからこそ大きなチャンスがあるといえます。生成AIのモデル開発には大量のGPU(Graphics Processing Unit)が必要であり、現時点ではNVIDIAというGPUのトップベンダーが一番収益を上げているようです。その次として大量のGPUを確保し学習を行いモデルを開発するOpenAIやAnthoripicなどのモデル開発プレイヤー、それらのモデルが組み込まれたサービスを提供するクラウドベンダーなどが挙げられます。おそらく多くのエンジニアは個人でも課金をしていたり、企業が課金しているものを使っているのではないでしょうか。
2024年6月ごろにアンケートをとったところこんな結果が出ました。
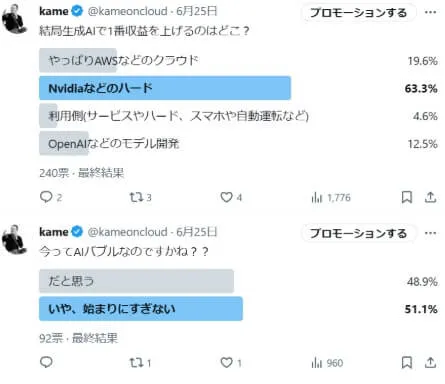
バブルであるかどうか意見が分かれた、ということは業界全体でまだ模索中であり、なおかつそのマネタイズモデルが見えないということです。本当にアンケート通りに生成AIで収益を上げるプレイヤーが、1) GPUのハードウェア 2) クラウド 3) 生成AI開発企業 4) 生成AIを組み込んだサービス、なのだとするとこれほどインパクトのある技術にも関わらず夢がなさすぎると言わざるを得ません。
サービスに生成AIを組み込むことは、ユーザー体験向上の簡単からもはや不可逆な必須の流れです。多くのサービスがこの機能を組み込むとなれば当然差別化要因にはならず、生成AIのコストをサービス利用者から回収できない、というのが今の現状です。すでに生成AI利用料金が高すぎるという声も上がり始めています。
高価なGPUを大量に確保可能なベンダーのみが、生成AIモデルを開発可能なのだとするとこれはマネーゲームとなってしまい、そこにベンチャーマインドを持った企業の参入余地が限られてしまうことは業界全体の発展性も危ぶまれます。様々なプレイヤーが切磋琢磨することで業界は発展していきます。
2025年1月にリリースされたDeepSeek-R1は、生成AIモデル開発及びその運用(推論)において、よりコストを削減可能な可能性を提示したため話題となりました。
そのまえにAIがGPUを必要とする理由をおさらいしていきます。
AIがGPUを必要とするわけ
なぜAIはGPUが必要なのでしょうか。CPUではだめなのでしょうか。そもそもグラフィックプロセッシングユニットがなぜAIに必要なのでしょうか。
理由その1:浮動小数点計算の多用
いまは多くのゲームが3D化されています。昔懐かしい職人技のドット打ち込みによる2Dゲームも味わい深いですが、AAAといわれる大型タイトルはほぼすべて3Dです。ゲームのグライフィックスが向上するとキャラクターの動きは滑らかになっていきます。そうすると画面の3D座標はどうしても小数点が多用されるようになります。このためGPUはもともとCPUに比べて小数点計算を多用することを前提として発展してきました。
AIも同じです。発展とともに多くの情報量を取り扱えるようになり、精度向上のために少しずつ特定のキーワードに重みをつけ最適化という名の微調整を行う必要が出てきます。すでに存在している2つの数字の間をとる、ということを延々と繰り返すのであれば、どうしても小数点の計算が主流となります。
このように2つの技術特性が似ていたということが挙げられます。
理由その2:並列処理
今のサーバやパソコンというのは、Macを除けば共通規格です。つまり、CPUやメモリ、GPU間の通信速度、通信方式は定まっていて、ベンダー独自方式で発展させることはできません。一方、単一ハードウェアの中身はベンダー独自に発展させ高速化させることが可能です。
このように、要求されるスペックの向上とともにGPUというハードウェアは進化を続け並列計算能力を向上させてきました。
しかしながらこれはあくまできっかけです。前述したGPUとAIの技術特性が似ていることに早くから着目したNVIDIAは、機械学習のエコシステム向けのライブラリ整備などに早くから着手しているため、きっかけは偶然技術素地が似ていた、というものですが、今は使われるべくしてGPUがAIに使われるようになってきています。CUDA(Compute Unified Device Architecture)というAI開発を加速化させる専用アーキテクチャーをリリースさせたり、グラフィックス機能以外にも汎用的にGPUを利用できるようなGPGPU(General-Purpose computing on Graphics Processing Units)といった機能も開発されています。
いまのGPUが抱える課題を1個上げるとするならば、もちろん値段が高すぎることと、NVIDIAという1社独占状態にあることでしょう。
DeepSeek-R1とは

中国のAI企業DeepSeek社がリリースしたDeepSeekシリーズの最新モデルです。より少ないコスト(モデル開発時、推論時両方)でOpenAIのo1と同等の性能を持ちながら従来のコストを80%削減化に成功したということが話題になりました。

ここで使われているブレイクスルーを見出した技術が動的ビット量子化といわれるものです。
ビット量子化とは
まず動的ビット量子化の話の前に、ビット量子化についてまとめていきます。この記事は専門家向けではないですし私も専門家ではないのでふわっといきます。

前回まとめたRAGを例にとると、埋め込まれた(ベクトル化された)文字列は、埋め込みに持ちいるモデルにもよりますが300+や500+を超えるベクトルが生成されます。
[-0.030333733,-0.02388421,0.017893493,-0.028157676,-0.0021449253,-0.016910335,-0.0071901698,-0.011502961,0.0072491593,-0.0125909895,0.014013293,0.0042538014,0.003480383,0.015297955,-0.018968415,<snip>-0.017408468,-0.044543657,-0.012014204,-0.0033099686,-0.012440239,-0.013305419,-0.009962678]つまりこういう小数点を数百個含むベクトルがチャンクの数だけ生成され、検索時にはすべてのチャンクに対してベクトル検索が行われます。文字列をベクトルにしている分、通常のRDBMSにおける全文検索などよりは計算量を減らせることが期待てきますが、それにしても大量の浮動小数点計算が発生するためGPUが大量に必要となることがわかると思います。
この計算量を減らすのがビット量子化です。
量子化、という言葉
私もそうですが量子 イコールよくわからないもの、と直感的にとらえてしまいますが実は簡単です。もともと英語でいう量子化とは、ある物事を小さく区切って観察して全体を把握しようとすること、を意味します。物理(原子)の世界でそれを行ったときに、たまたまわけのわからない世界がそこには存在していた、だけなのです。あまりにあの量子物理学の印象が強いため量子化というと理解しがたいものという印象が付きまといます。
ではあらためて、ビット量子化と動的ビット量子化
単純に言えば計算量を減らすことです。
元データ:-0.030333733
量子化後データ:-0.03
このように計算量を減らしていきます。当然精度が下がることは予想がつくと思います。生成AIがプロンプトというリクエストを受け付けてから回答というレスポンスを戻すまで複数の計算が行われますが、そこに対して一律的に同じ量子化を行うと全体的な精度が下がります。複数行われる計算の中で、精度を下げていいもの、精度をあまり下げない方がいいもの、精度を下げないもの、などそれぞれの領域ごとにビット量子化の方式を変えていくのが動的ビット量子化です。
この考え方自体はシンプルですが、この方式の実装に商用レベルで成功したのがDeepSeek-R1といえます。
1ビット量子化
このビット量子化の考え方を極限までシンプルにしたものが1ビット量子化です。
元データベクトル
[-0.030333733,-0.02388421,0.017893493,-0.028157676,-0.0021449253]1ビット量子化後ベクトル
[0,0,1,0,0]このようにプラスのものを1 マイナスのものを0 にします。当然複数回行われるすべての計算にこの手法を用いると精度が厳しいので必要な時だけ極限まで量子化された情報を用いて計算を行います。
実はこのように、時と場合のよってどこまでシンプルに情報を判断につかうか?は実生活にはよくあります。
例えば仕事帰りに同僚と食事に行くとします。あらかじめお金をおろしておいた方がいいかどうか財布を見るときは、普通お札の情報しか見ないと思います。食事後同僚との割り勘は数百円、数十円単位で計算すると思います。そして最後お店への支払いの際には1円単位で行います。このようにどの時点でどこまで情報をシンプルにしたもので判断を行うのかは、実世界ではよくある話で、それが生成AIの世界で商用レベルで成功したのがDeepSeek-R1であり多くの人が注目した理由です。






