生成AIが多くのサービスに組み込まれ実際にそのパワーに触れる人が増えるにつれ、サービスに組み込みユーザー体験を向上させたい、もしくは社内ツールの利便性を向上させたいという要望が高まってきています。そのなかでRAGというものが注目を集めています。
そもそもRAGとは
RAG(Retrieval-Augmented Generation)という言葉は、2020年Meta/Facebookが出した論文が最初といわれていますが、古くからその考え方は存在しており、検索の補助として機械学習を用いてより精度の高い回答を動的に生成するという考え方です。
生成AIを用いることで、ある程度回答に含めてほしいキーワードや短い文章の束を投げれば、それを自然な回答にすることが簡単に実装できるようになったため、実装のハードルが下がり、また精度が向上したことからその利用が注目されています。
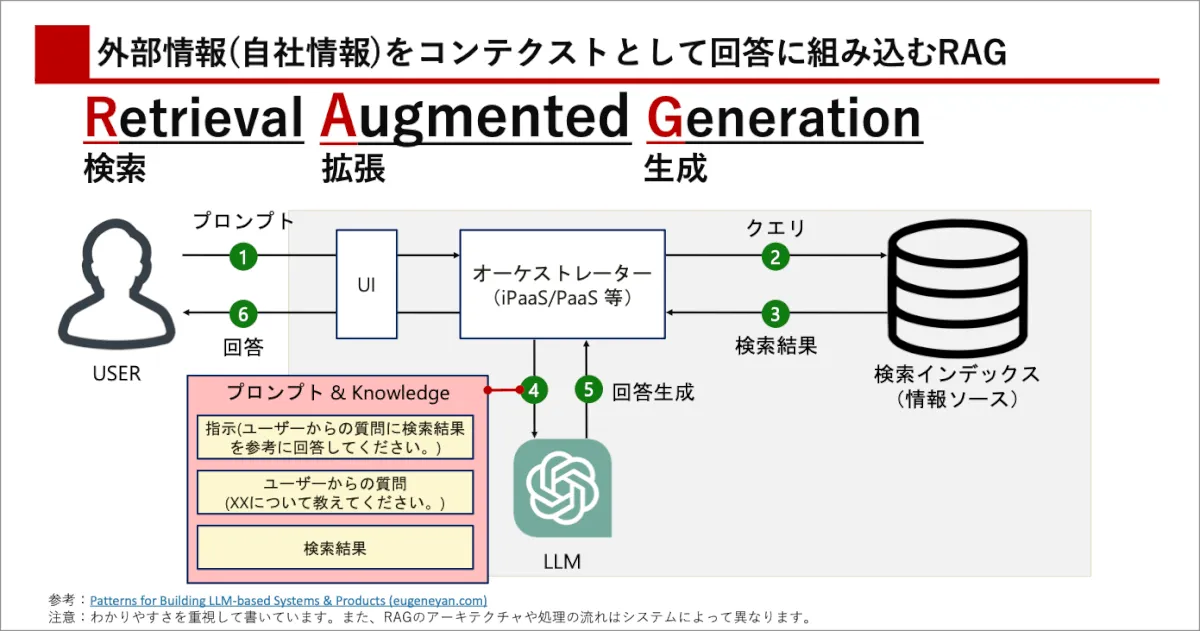
一般的な生成AIモデルは、インターネット上に存在している情報をクローラが収集し学習を行っています。このため特定企業の非公開情報や特定サービス固有の情報などは回答をしてくれません。一方で回答を生成するための素材(キーワードや短い文章の束)を投げてあげれば、それを自然な形の文章にしてくれます。
これを行うために、生成AIモデルと連携する検索インデックス(情報ソース)をあらかじめ作成しておきます。情報ソースの作成には様々な手法が準備されていますが、一般的にはベクトル検索を使うのが主流です。
あらかじ与えられた文章をチャンク という単位に分割しそれをベクトル化し、もとの文章(メタデータ)とセットで検索インデックスに保存しておきます。検索を行う際は、検索用に入力された文字列も同様にベクトル化され数学的に関連度が高いものを抽出します。そして最後に数学的に近いと判断されたベクトルデータと紐づくメタデータ(もとの文章)を生成AIが回答として自然な言語に作り直し回答が作成されます。
つまり生成AIのモデルは2回動作します。
- 事前のベクトル化(埋め込み)
- 最終的な回答の生成
この時、それぞれ異なるモデルを用いることが可能となっています。
埋め込みにおける見落とされがちなコスト
実際にRAGを構築して運用を行ってみるとわかりますが、時として精度が出ないケースがあります。生成AIの進化は目覚ましく、日進月歩です。上記の1.および2.ともに、用いる生成AIモデルをバージョンアップさせていくことで精度の向上は期待できるのですが、注意点があります。最終的な回答の生成 は、やり取りする文字列に応じで課金されますので、利用総容量と利用料金は比例します。一方事前のベクトル化(埋め込み) はあらかじめやっておくべき事前作業であり、一定のコストが発生します。現在、生成AI各種プレイヤが提供する埋め込み用モデルには、後方互換性が存在しないことに注意しておく必要があります。
つまり、RAG構築時に発生した埋め込み用生成AI利用料金は、バージョンアップの際に再度発生します。少なくとも予算として半年に一度はその作業を行うことを想定しておいた方が良いでしょう。
事前の埋め込み作業を行わずベクトル検索を行う手法や、ベクトル検索を用いない手法もあるにはありますが、生成AIの隆起と共にRAGへの期待が高まったことと考えるとやはり精度的には課題がありそうです。
チャンクと精度向上の限界
多くの企業がRAGへの取り組みを継続し、それをサポートするインテグレータも増えるにつれ、精度向上は大きな課題となっています。株式会社クラウドネイティブでも以下の様にそのノウハウをまとめてブログで公開していますので、目を通してみてください。
とはいえ限界があります。一つの文章をチャンク という文字列に分解してベクトル化をおこない、検索に用いるという方式には限界があります。
シンプルな例を考えます。2,000文字のPDFがあるとします。これを500文字単位のチャンクに分解した場合、一つのチャンクに複数の文章が入るケースもあれば、一つの長い文章が分解されて複数のチャンクに分かれてしまうことによる相関性が失われるケースもあります。
そして作成されたこの4つのチャンクは基本的には相関性を持っていません。意図的に相関性を持たせるために、例えば50文字づつ同じ文字列をチャンクに入れる方法などもあります。
- チャンク1: 0 – 500
- チャンク2: 450 – 950
- チャンク3: 900 – 1,400
- チャンク4: 1,350 – 1,850
- チャンク5: 1,800 – 2,000
この意図的にオーバーラップさせた50文字の中によく検索される重要な単語が入れば精度の向上は期待できるかもしれませんが、やはり運の要素が大きいといえます。
グラフRAGへの期待
このため、ベクトル検索だけではなく言葉の相関性を持たせるグラフ理論に基づいた、ナレッジグラフを組み合わせる試みが本格化しています。一番最初にグラフRAGというものを提唱したのはMicrosoft社です。
そのライブラリはOSSとしても提供されているので、興味があれば試してみることも可能です。
2024年のAWS re:Inventでも、Amazon BedrockがグラフデータベースであるAmazon Netptuneのサポートを表明し、このグラフRAGというものは今後利用、そして実際の現場での開発知見などがたまっていくことが期待されています。
(https://aws.amazon.com/jp/neptune)
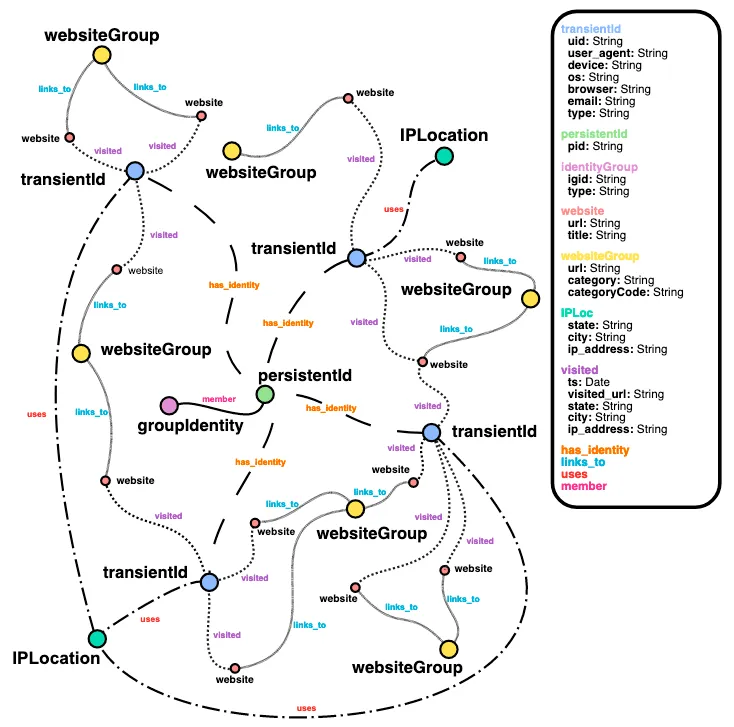
グラフデータというのは、ノード といわれる頂点とエッジ といわれるノード間を結ぶ線に設定される関係性のデータから構成されます。
これは空港と飛行に例えるとわかりやすいです。
ノードが各空港、エッジが空港間を飛ぶ飛行機です。元の文章を単純に500文字などの固定長で分割するよりは、頻出する単語をノードとして、どの単語がどの単語をどういう文脈でさしているか?を、エッジの情報として保存しておきます。それぞれの情報は通常のRAGと同じようにベクトル化されており、検索のロジックは同じとなりますが、その際に一番多くさされている単語に重みをつけて回答を生成するなど、より精度の高い回答が期待されています。